 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamudrACE: Fast and Accurate Coupled Climate Modeling with 3D Ocean and Atmosphere Emulators
Sep 15, 2025
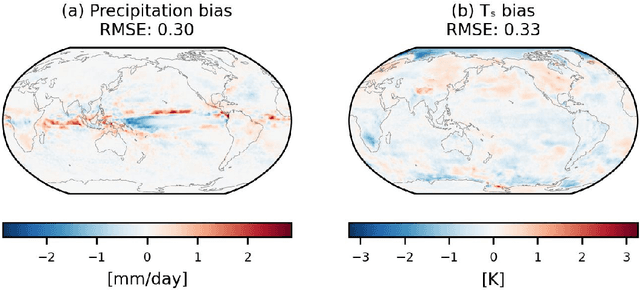


Traditional numerical global climate models simulate the full Earth system by exchanging boundary conditions between separate simulators of the atmosphere, ocean, sea ice, land surface, and other geophysical processes. This paradigm allows for distributed development of individual components within a common framework, unified by a coupler that handles translation between realms via spatial or temporal alignment and flux exchange. Following a similar approach adapted for machine learning-based emulators, we present SamudrACE: a coupled global climate model emulator which produces centuries-long simulations at 1-degree horizontal, 6-hourly atmospheric, and 5-daily oceanic resolution, with 145 2D fields spanning 8 atmospheric and 19 oceanic vertical levels, plus sea ice, surface, and top-of-atmosphere variables. SamudrACE is highly stable and has low climate biases comparable to those of its components with prescribed boundary forcing, with realistic variability in coupled climate phenomena such as ENSO that is not possible to simulate in uncoupled mode.
CondensNet: Enabling stable long-term climate simulations via hybrid deep learning models with adaptive physical constraints
Feb 18, 2025Accurate and efficient climate simulations are crucial for understanding Earth's evolving climate. However, current general circulation models (GCMs) face challenges in capturing unresolved physical processes, such as cloud and convection. A common solution is to adopt cloud resolving models, that provide more accurate results than the standard subgrid parametrisation schemes typically used in GCMs. However, cloud resolving models, also referred to as super paramtetrizations, remain computationally prohibitive. Hybrid modeling, which integrates deep learning with equation-based GCMs, offers a promising alternative but often struggles with long-term stability and accuracy issues. In this work, we find that water vapor oversaturation during condensation is a key factor compromising the stability of hybrid models. To address this, we introduce CondensNet, a novel neural network architecture that embeds a self-adaptive physical constraint to correct unphysical condensation processes. CondensNet effectively mitigates water vapor oversaturation, enhancing simulation stability while maintaining accuracy and improving computational efficiency compared to super parameterization schemes. We integrate CondensNet into a GCM to form PCNN-GCM (Physics-Constrained Neural Network GCM), a hybrid deep learning framework designed for long-term stable climate simulations in real-world conditions, including ocean and land. PCNN-GCM represents a significant milestone in hybrid climate modeling, as it shows a novel way to incorporate physical constraints adaptively, paving the way for accurate, lightweight, and stable long-term climate simulations.
Exploring the Potential of Hybrid Machine-Learning/Physics-Based Modeling for Atmospheric/Oceanic Prediction Beyond the Medium Range
May 29, 2024This paper explores the potential of a hybrid modeling approach that combines machine learning (ML) with conventional physics-based modeling for weather prediction beyond the medium range. It extends the work of Arcomano et al. (2022), which tested the approach for short- and medium-range weather prediction, and the work of Arcomano et al. (2023), which investigated its potential for climate modeling. The hybrid model used for the forecast experiments of the paper is based on the low-resolution, simplified parameterization atmospheric general circulation model (AGCM) SPEEDY. In addition to the hybridized prognostic variables of SPEEDY, the current version of the model has three purely ML-based prognostic variables. One of these is 6~h cumulative precipitation, another is the sea surface temperature, while the third is the heat content of the top 300 m deep layer of the ocean. The model has skill in predicting the El Ni\~no cycle and its global teleconnections with precipitation for 3-7 months depending on the season. The model captures equatorial variability of the precipitation associated with Kelvin and Rossby waves and MJO. Predictions of the precipitation in the equatorial region have skill for 15 days in the East Pacific and 11.5 days in the West Pacific. Though the model has low spatial resolution, for these tasks it has prediction skill comparable to what has been published for high-resolution, purely physics-based, conventional operational forecast models.
LUCIE: A Lightweight Uncoupled ClImate Emulator with long-term stability and physical consistency for O(1000)-member ensembles
May 25, 2024



We present LUCIE, a $1000$- member ensemble data-driven atmospheric emulator that remains stable during autoregressive inference for thousands of years without a drifting climatology. LUCIE has been trained on $9.5$ years of coarse-resolution ERA5 data with $4$ prognostic variables on a single A100 GPU for $2.4$ h. Owing to the cheap computational cost of inference, $1000$ model ensembles are executed for $5$ years to compute an uncertainty-quantified climatology for the prognostic variables that closely match the climatology obtained from ERA5. Unlike all the other state-of-the-art AI weather models, LUCIE is neither unstable nor does it produce hallucinations that result in unphysical drift of the emulated climate. Furthermore, LUCIE \textbf{does not impose} ``true" sea-surface temperature (SST) from a coupled numerical model to enforce the annual cycle in temperature. We demonstrate the long-term climatology obtained from LUCIE as well as subseasonal-to-seasonal scale prediction skills on the prognostic variables. We also demonstrate a $20$-year emulation with LUCIE here: https://drive.google.com/file/d/1mRmhx9RRGiF3uGo_mRQK8RpwQatrCiMn/view
Scaling transformer neural networks for skillful and reliable medium-range weather forecasting
Dec 06, 2023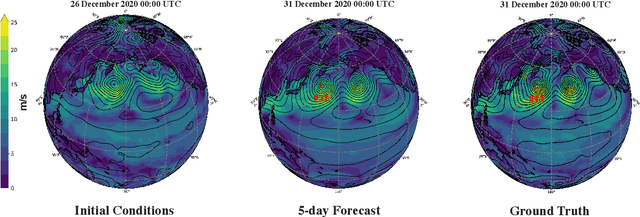
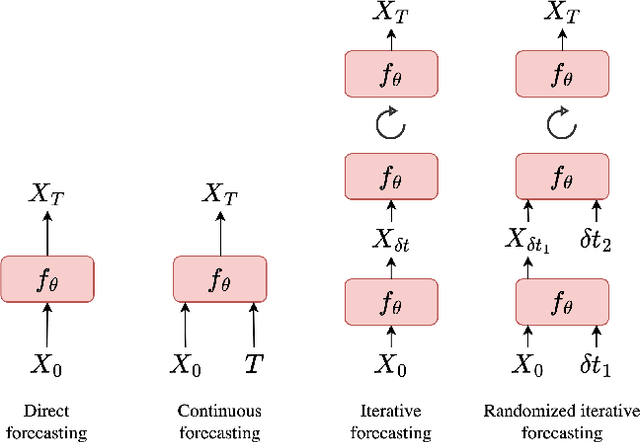
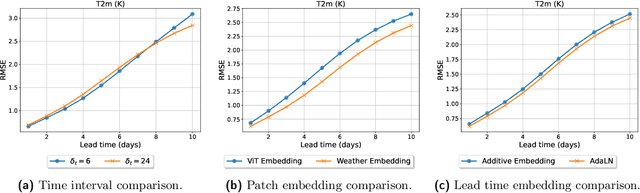
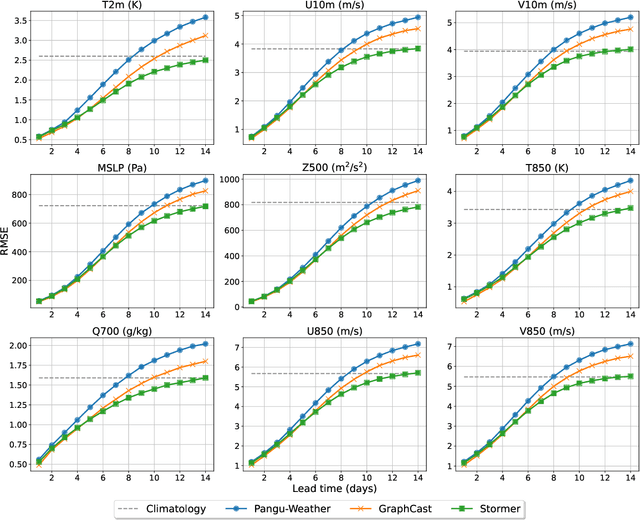
Weather forecasting is a fundamental problem for anticipating and mitigating the impacts of climate change. Recently, data-driven approaches for weather forecasting based on deep learning have shown great promise, achieving accuracies that are competitive with operational systems. However, those methods often employ complex, customized architectures without sufficient ablation analysis, making it difficult to understand what truly contributes to their success. Here we introduce Stormer, a simple transformer model that achieves state-of-the-art performance on weather forecasting with minimal changes to the standard transformer backbone. We identify the key components of Stormer through careful empirical analyses, including weather-specific embedding, randomized dynamics forecast, and pressure-weighted loss. At the core of Stormer is a randomized forecasting objective that trains the model to forecast the weather dynamics over varying time intervals. During inference, this allows us to produce multiple forecasts for a target lead time and combine them to obtain better forecast accuracy. On WeatherBench 2, Stormer performs competitively at short to medium-range forecasts and outperforms current methods beyond 7 days, while requiring orders-of-magnitude less training data and compute. Additionally, we demonstrate Stormer's favorable scaling properties, showing consistent improvements in forecast accuracy with increases in model size and training tokens. Code and checkpoints will be made publicly available.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023



In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Combining Machine Learning with Knowledge-Based Modeling for Scalable Forecasting and Subgrid-Scale Closure of Large, Complex, Spatiotemporal Systems
Feb 10, 2020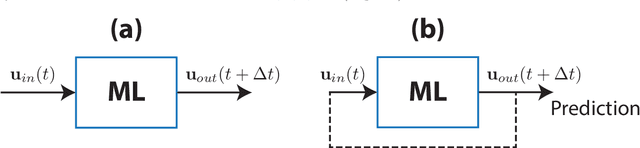
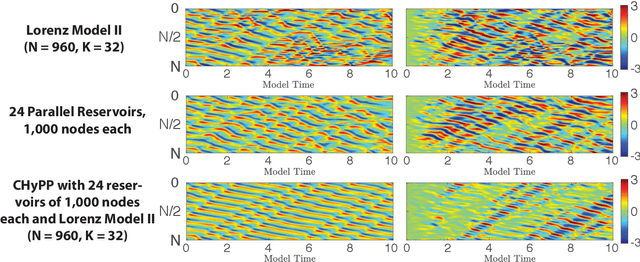
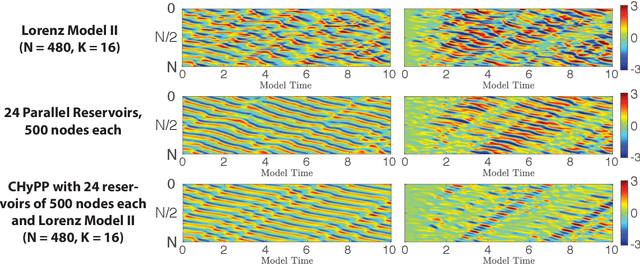
We consider the commonly encountered situation (e.g., in weather forecasting) where the goal is to predict the time evolution of a large, spatiotemporally chaotic dynamical system when we have access to both time series data of previous system states and an imperfect model of the full system dynamics. Specifically, we attempt to utilize machine learning as the essential tool for integrating the use of past data into predictions. In order to facilitate scalability to the common scenario of interest where the spatiotemporally chaotic system is very large and complex, we propose combining two approaches:(i) a parallel machine learning prediction scheme; and (ii) a hybrid technique, for a composite prediction system composed of a knowledge-based component and a machine-learning-based component. We demonstrate that not only can this method combining (i) and (ii) be scaled to give excellent performance for very large systems, but also that the length of time series data needed to train our multiple, parallel machine learning components is dramatically less than that necessary without parallelization. Furthermore, considering cases where computational realization of the knowledge-based component does not resolve subgrid-scale processes, our scheme is able to use training data to incorporate the effect of the unresolved short-scale dynamics upon the resolved longer-scale dynamics ("subgrid-scale closure").