 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKORAL: Knowledge Graph Guided LLM Reasoning for SSD Operational Analysis
Feb 10, 2026Solid State Drives (SSDs) are critical to datacenters, consumer platforms, and mission-critical systems. Yet diagnosing their performance and reliability is difficult because data are fragmented and time-disjoint, and existing methods demand large datasets and expert input while offering only limited insights. Degradation arises not only from shifting workloads and evolving architectures but also from environmental factors such as temperature, humidity, and vibration. We present KORAL, a knowledge driven reasoning framework that integrates Large Language Models (LLMs) with a structured Knowledge Graph (KG) to generate insights into SSD operations. Unlike traditional approaches that require extensive expert input and large datasets, KORAL generates a Data KG from fragmented telemetry and integrates a Literature KG that already organizes knowledge from literature, reports, and traces. This turns unstructured sources into a queryable graph and telemetry into structured knowledge, and both the Graphs guide the LLM to deliver evidence-based, explainable analysis aligned with the domain vocabulary and constraints. Evaluation using real production traces shows that the KORAL delivers expert-level diagnosis and recommendations, supported by grounded explanations that improve reasoning transparency, guide operator decisions, reduce manual effort, and provide actionable insights to improve service quality. To our knowledge, this is the first end-to-end system that combines LLMs and KGs for full-spectrum SSD reasoning including Descriptive, Predictive, Prescriptive, and What-if analysis. We release the generated SSD-specific KG to advance reproducible research in knowledge-based storage system analysis. GitHub Repository: https://github.com/Damrl-lab/KORAL
Multi-task Modeling for Engineering Applications with Sparse Data
Jan 09, 2026Modern engineering and scientific workflows often require simultaneous predictions across related tasks and fidelity levels, where high-fidelity data is scarce and expensive, while low-fidelity data is more abundant. This paper introduces an Multi-Task Gaussian Processes (MTGP) framework tailored for engineering systems characterized by multi-source, multi-fidelity data, addressing challenges of data sparsity and varying task correlations. The proposed framework leverages inter-task relationships across outputs and fidelity levels to improve predictive performance and reduce computational costs. The framework is validated across three representative scenarios: Forrester function benchmark, 3D ellipsoidal void modeling, and friction-stir welding. By quantifying and leveraging inter-task relationships, the proposed MTGP framework offers a robust and scalable solution for predictive modeling in domains with significant computational and experimental costs, supporting informed decision-making and efficient resource utilization.
Efficient Flow Matching using Latent Variables
May 07, 2025Flow matching models have shown great potential in image generation tasks among probabilistic generative models. Building upon the ideas of continuous normalizing flows, flow matching models generalize the transport path of the diffusion models from a simple prior distribution to the data. Most flow matching models in the literature do not explicitly model the underlying structure/manifold in the target data when learning the flow from a simple source distribution like the standard Gaussian. This leads to inefficient learning, especially for many high-dimensional real-world datasets, which often reside in a low-dimensional manifold. Existing strategies of incorporating manifolds, including data with underlying multi-modal distribution, often require expensive training and hence frequently lead to suboptimal performance. To this end, we present \texttt{Latent-CFM}, which provides simplified training/inference strategies to incorporate multi-modal data structures using pretrained deep latent variable models. Through experiments on multi-modal synthetic data and widely used image benchmark datasets, we show that \texttt{Latent-CFM} exhibits improved generation quality with significantly less training ($\sim 50\%$ less in some cases) and computation than state-of-the-art flow matching models. Using a 2d Darcy flow dataset, we demonstrate that our approach generates more physically accurate samples than competitive approaches. In addition, through latent space analysis, we demonstrate that our approach can be used for conditional image generation conditioned on latent features.
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Question Rephrasing for Quantifying Uncertainty in Large Language Models: Applications in Molecular Chemistry Tasks
Aug 07, 2024



Uncertainty quantification enables users to assess the reliability of responses generated by large language models (LLMs). We present a novel Question Rephrasing technique to evaluate the input uncertainty of LLMs, which refers to the uncertainty arising from equivalent variations of the inputs provided to LLMs. This technique is integrated with sampling methods that measure the output uncertainty of LLMs, thereby offering a more comprehensive uncertainty assessment. We validated our approach on property prediction and reaction prediction for molecular chemistry tasks.
AstroMLab 1: Who Wins Astronomy Jeopardy!?
Jul 15, 2024We present a comprehensive evaluation of proprietary and open-weights large language models using the first astronomy-specific benchmarking dataset. This dataset comprises 4,425 multiple-choice questions curated from the Annual Review of Astronomy and Astrophysics, covering a broad range of astrophysical topics. Our analysis examines model performance across various astronomical subfields and assesses response calibration, crucial for potential deployment in research environments. Claude-3.5-Sonnet outperforms competitors by up to 4.6 percentage points, achieving 85.0% accuracy. For proprietary models, we observed a universal reduction in cost every 3-to-12 months to achieve similar score in this particular astronomy benchmark. Open-source models have rapidly improved, with LLaMA-3-70b (80.6%) and Qwen-2-72b (77.7%) now competing with some of the best proprietary models. We identify performance variations across topics, with non-English-focused models generally struggling more in exoplanet-related fields, stellar astrophysics, and instrumentation related questions. These challenges likely stem from less abundant training data, limited historical context, and rapid recent developments in these areas. This pattern is observed across both open-weights and proprietary models, with regional dependencies evident, highlighting the impact of training data diversity on model performance in specialized scientific domains. Top-performing models demonstrate well-calibrated confidence, with correlations above 0.9 between confidence and correctness, though they tend to be slightly underconfident. The development for fast, low-cost inference of open-weights models presents new opportunities for affordable deployment in astronomy. The rapid progress observed suggests that LLM-driven research in astronomy may become feasible in the near future.
REMEDI: Corrective Transformations for Improved Neural Entropy Estimation
Feb 08, 2024
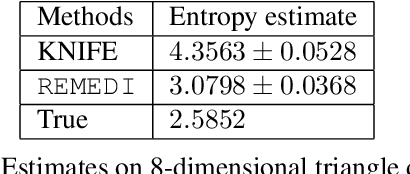
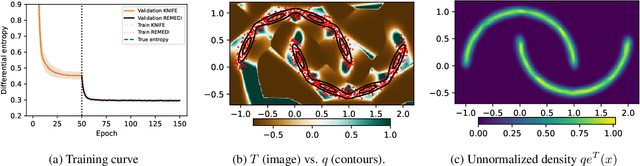
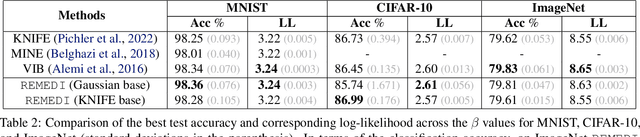
Information theoretic quantities play a central role in machine learning. The recent surge in the complexity of data and models has increased the demand for accurate estimation of these quantities. However, as the dimension grows the estimation presents significant challenges, with existing methods struggling already in relatively low dimensions. To address this issue, in this work, we introduce $\texttt{REMEDI}$ for efficient and accurate estimation of differential entropy, a fundamental information theoretic quantity. The approach combines the minimization of the cross-entropy for simple, adaptive base models and the estimation of their deviation, in terms of the relative entropy, from the data density. Our approach demonstrates improvement across a broad spectrum of estimation tasks, encompassing entropy estimation on both synthetic and natural data. Further, we extend important theoretical consistency results to a more generalized setting required by our approach. We illustrate how the framework can be naturally extended to information theoretic supervised learning models, with a specific focus on the Information Bottleneck approach. It is demonstrated that the method delivers better accuracy compared to the existing methods in Information Bottleneck. In addition, we explore a natural connection between $\texttt{REMEDI}$ and generative modeling using rejection sampling and Langevin dynamics.
Scaling transformer neural networks for skillful and reliable medium-range weather forecasting
Dec 06, 2023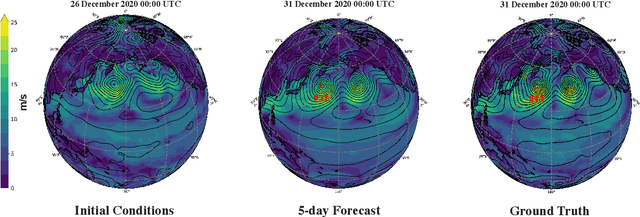
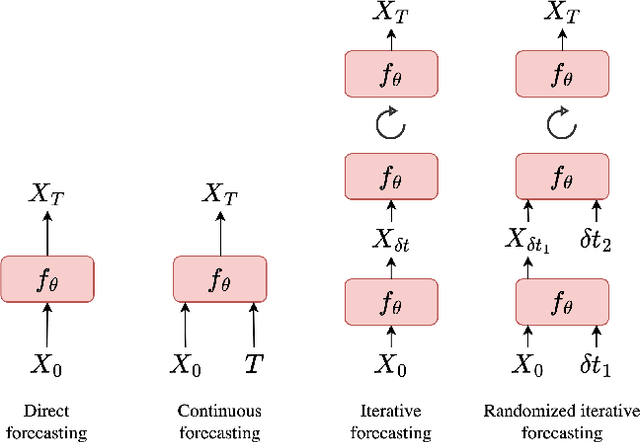
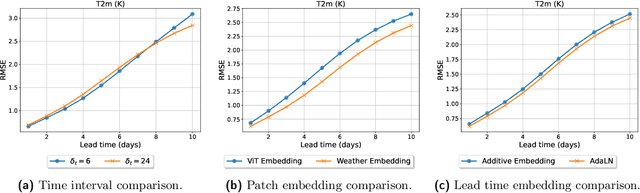
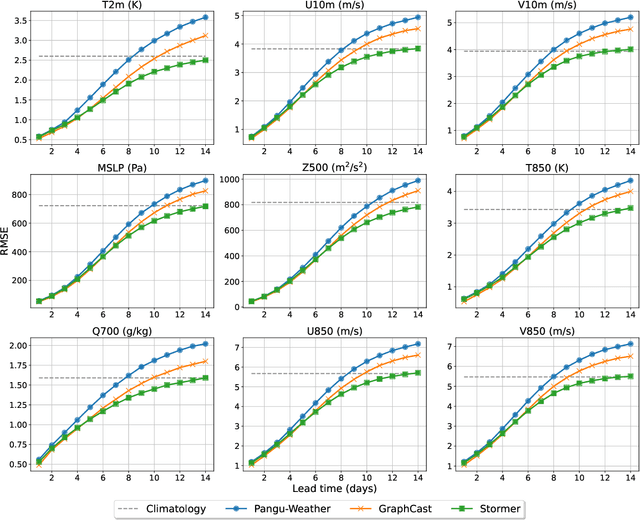
Weather forecasting is a fundamental problem for anticipating and mitigating the impacts of climate change. Recently, data-driven approaches for weather forecasting based on deep learning have shown great promise, achieving accuracies that are competitive with operational systems. However, those methods often employ complex, customized architectures without sufficient ablation analysis, making it difficult to understand what truly contributes to their success. Here we introduce Stormer, a simple transformer model that achieves state-of-the-art performance on weather forecasting with minimal changes to the standard transformer backbone. We identify the key components of Stormer through careful empirical analyses, including weather-specific embedding, randomized dynamics forecast, and pressure-weighted loss. At the core of Stormer is a randomized forecasting objective that trains the model to forecast the weather dynamics over varying time intervals. During inference, this allows us to produce multiple forecasts for a target lead time and combine them to obtain better forecast accuracy. On WeatherBench 2, Stormer performs competitively at short to medium-range forecasts and outperforms current methods beyond 7 days, while requiring orders-of-magnitude less training data and compute. Additionally, we demonstrate Stormer's favorable scaling properties, showing consistent improvements in forecast accuracy with increases in model size and training tokens. Code and checkpoints will be made publicly available.
Surrogate Neural Networks to Estimate Parametric Sensitivity of Ocean Models
Nov 10, 2023



Modeling is crucial to understanding the effect of greenhouse gases, warming, and ice sheet melting on the ocean. At the same time, ocean processes affect phenomena such as hurricanes and droughts. Parameters in the models that cannot be physically measured have a significant effect on the model output. For an idealized ocean model, we generated perturbed parameter ensemble data and trained surrogate neural network models. The neural surrogates accurately predicted the one-step forward dynamics, of which we then computed the parametric sensitivity.