 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA weak convergence approach to large deviations for stochastic approximations
Feb 04, 2025The theory of stochastic approximations form the theoretical foundation for studying convergence properties of many popular recursive learning algorithms in statistics, machine learning and statistical physics. Large deviations for stochastic approximations provide asymptotic estimates of the probability that the learning algorithm deviates from its expected path, given by a limit ODE, and the large deviation rate function gives insights to the most likely way that such deviations occur. In this paper we prove a large deviation principle for general stochastic approximations with state-dependent Markovian noise and decreasing step size. Using the weak convergence approach to large deviations, we generalize previous results for stochastic approximations and identify the appropriate scaling sequence for the large deviation principle. We also give a new representation for the rate function, in which the rate function is expressed as an action functional involving the family of Markov transition kernels. Examples of learning algorithms that are covered by the large deviation principle include stochastic gradient descent, persistent contrastive divergence and the Wang-Landau algorithm.
REMEDI: Corrective Transformations for Improved Neural Entropy Estimation
Feb 08, 2024
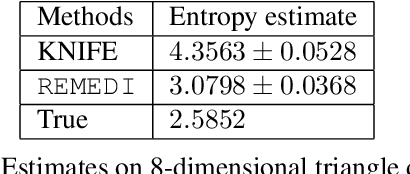
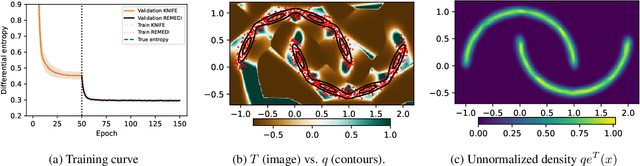
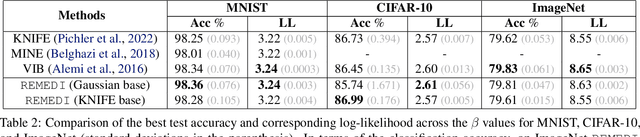
Information theoretic quantities play a central role in machine learning. The recent surge in the complexity of data and models has increased the demand for accurate estimation of these quantities. However, as the dimension grows the estimation presents significant challenges, with existing methods struggling already in relatively low dimensions. To address this issue, in this work, we introduce $\texttt{REMEDI}$ for efficient and accurate estimation of differential entropy, a fundamental information theoretic quantity. The approach combines the minimization of the cross-entropy for simple, adaptive base models and the estimation of their deviation, in terms of the relative entropy, from the data density. Our approach demonstrates improvement across a broad spectrum of estimation tasks, encompassing entropy estimation on both synthetic and natural data. Further, we extend important theoretical consistency results to a more generalized setting required by our approach. We illustrate how the framework can be naturally extended to information theoretic supervised learning models, with a specific focus on the Information Bottleneck approach. It is demonstrated that the method delivers better accuracy compared to the existing methods in Information Bottleneck. In addition, we explore a natural connection between $\texttt{REMEDI}$ and generative modeling using rejection sampling and Langevin dynamics.
A note on large deviations for interacting particle dynamics for finding mixed equilibria in zero-sum games
Jul 15, 2022Finding equilibria points in continuous minimax games has become a key problem within machine learning, in part due to its connection to the training of generative adversarial networks. Because of existence and robustness issues, recent developments have shifted from pure equilibria to focusing on mixed equilibria points. In this note we consider a method proposed by Domingo-Enrich et al. for finding mixed equilibria in two-layer zero-sum games. The method is based on entropic regularisation and the two competing strategies are represented by two sets of interacting particles. We show that the sequence of empirical measures of the particle system satisfies a large deviation principle as the number of particles grows to infinity, and how this implies convergence of the empirical measure and the associated Nikaid\^o-Isoda error, complementing existing law of large numbers results.