 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnginuity: Building an Open Multi-Domain Dataset of Complex Engineering Diagrams
Jan 19, 2026We propose Enginuity - the first open, large-scale, multi-domain engineering diagram dataset with comprehensive structural annotations designed for automated diagram parsing. By capturing hierarchical component relationships, connections, and semantic elements across diverse engineering domains, our proposed dataset would enable multimodal large language models to address critical downstream tasks including structured diagram parsing, cross-modal information retrieval, and AI-assisted engineering simulation. Enginuity would be transformative for AI for Scientific Discovery by enabling artificial intelligence systems to comprehend and manipulate the visual-structural knowledge embedded in engineering diagrams, breaking down a fundamental barrier that currently prevents AI from fully participating in scientific workflows where diagram interpretation, technical drawing analysis, and visual reasoning are essential for hypothesis generation, experimental design, and discovery.
HARNESS: Human-Agent Risk Navigation and Event Safety System for Proactive Hazard Forecasting in High-Risk DOE Environments
Nov 13, 2025Operational safety at mission-critical work sites is a top priority given the complex and hazardous nature of daily tasks. This paper presents the Human-Agent Risk Navigation and Event Safety System (HARNESS), a modular AI framework designed to forecast hazardous events and analyze operational risks in U.S. Department of Energy (DOE) environments. HARNESS integrates Large Language Models (LLMs) with structured work data, historical event retrieval, and risk analysis to proactively identify potential hazards. A human-in-the-loop mechanism allows subject matter experts (SMEs) to refine predictions, creating an adaptive learning loop that enhances performance over time. By combining SME collaboration with iterative agentic reasoning, HARNESS improves the reliability and efficiency of predictive safety systems. Preliminary deployment shows promising results, with future work focusing on quantitative evaluation of accuracy, SME agreement, and decision latency reduction.
ORCHID: Orchestrated Retrieval-Augmented Classification with Human-in-the-Loop Intelligent Decision-Making for High-Risk Property
Nov 07, 2025


High-Risk Property (HRP) classification is critical at U.S. Department of Energy (DOE) sites, where inventories include sensitive and often dual-use equipment. Compliance must track evolving rules designated by various export control policies to make transparent and auditable decisions. Traditional expert-only workflows are time-consuming, backlog-prone, and struggle to keep pace with shifting regulatory boundaries. We demo ORCHID, a modular agentic system for HRP classification that pairs retrieval-augmented generation (RAG) with human oversight to produce policy-based outputs that can be audited. Small cooperating agents, retrieval, description refiner, classifier, validator, and feedback logger, coordinate via agent-to-agent messaging and invoke tools through the Model Context Protocol (MCP) for model-agnostic on-premise operation. The interface follows an Item to Evidence to Decision loop with step-by-step reasoning, on-policy citations, and append-only audit bundles (run-cards, prompts, evidence). In preliminary tests on real HRP cases, ORCHID improves accuracy and traceability over a non-agentic baseline while deferring uncertain items to Subject Matter Experts (SMEs). The demonstration shows single item submission, grounded citations, SME feedback capture, and exportable audit artifacts, illustrating a practical path to trustworthy LLM assistance in sensitive DOE compliance workflows.
AstroMLab 4: Benchmark-Topping Performance in Astronomy Q&A with a 70B-Parameter Domain-Specialized Reasoning Model
May 23, 2025General-purpose large language models, despite their broad capabilities, often struggle with specialized domain knowledge, a limitation particularly pronounced in more accessible, lower-parameter versions. This gap hinders their deployment as effective agents in demanding fields such as astronomy. Building on our prior work with AstroSage-8B, this study introduces AstroSage-70B, a significantly larger and more advanced domain-specialized natural-language AI assistant. It is designed for research and education across astronomy, astrophysics, space science, astroparticle physics, cosmology, and astronomical instrumentation. Developed from the Llama-3.1-70B foundation, AstroSage-70B underwent extensive continued pre-training on a vast corpus of astronomical literature, followed by supervised fine-tuning and model merging. Beyond its 70-billion parameter scale, this model incorporates refined datasets, judiciously chosen learning hyperparameters, and improved training procedures, achieving state-of-the-art performance on complex astronomical tasks. Notably, we integrated reasoning chains into the SFT dataset, enabling AstroSage-70B to either answer the user query immediately, or first emit a human-readable thought process. Evaluated on the AstroMLab-1 benchmark -- comprising 4,425 questions from literature withheld during training -- AstroSage-70B achieves state-of-the-art performance. It surpasses all other tested open-weight and proprietary models, including leading systems like o3, Gemini-2.5-Pro, Claude-3.7-Sonnet, Deepseek-R1, and Qwen-3-235B, even those with API costs two orders of magnitude higher. This work demonstrates that domain specialization, when applied to large-scale models, can enable them to outperform generalist counterparts in specialized knowledge areas like astronomy, thereby advancing the frontier of AI capabilities in the field.
Sparks of Science: Hypothesis Generation Using Structured Paper Data
Apr 17, 2025



Generating novel and creative scientific hypotheses is a cornerstone in achieving Artificial General Intelligence. Large language and reasoning models have the potential to aid in the systematic creation, selection, and validation of scientifically informed hypotheses. However, current foundation models often struggle to produce scientific ideas that are both novel and feasible. One reason is the lack of a dedicated dataset that frames Scientific Hypothesis Generation (SHG) as a Natural Language Generation (NLG) task. In this paper, we introduce HypoGen, the first dataset of approximately 5500 structured problem-hypothesis pairs extracted from top-tier computer science conferences structured with a Bit-Flip-Spark schema, where the Bit is the conventional assumption, the Spark is the key insight or conceptual leap, and the Flip is the resulting counterproposal. HypoGen uniquely integrates an explicit Chain-of-Reasoning component that reflects the intellectual process from Bit to Flip. We demonstrate that framing hypothesis generation as conditional language modelling, with the model fine-tuned on Bit-Flip-Spark and the Chain-of-Reasoning (and where, at inference, we only provide the Bit), leads to improvements in the overall quality of the hypotheses. Our evaluation employs automated metrics and LLM judge rankings for overall quality assessment. We show that by fine-tuning on our HypoGen dataset we improve the novelty, feasibility, and overall quality of the generated hypotheses. The HypoGen dataset is publicly available at huggingface.co/datasets/UniverseTBD/hypogen-dr1.
A Survey on Hypothesis Generation for Scientific Discovery in the Era of Large Language Models
Apr 07, 2025Hypothesis generation is a fundamental step in scientific discovery, yet it is increasingly challenged by information overload and disciplinary fragmentation. Recent advances in Large Language Models (LLMs) have sparked growing interest in their potential to enhance and automate this process. This paper presents a comprehensive survey of hypothesis generation with LLMs by (i) reviewing existing methods, from simple prompting techniques to more complex frameworks, and proposing a taxonomy that categorizes these approaches; (ii) analyzing techniques for improving hypothesis quality, such as novelty boosting and structured reasoning; (iii) providing an overview of evaluation strategies; and (iv) discussing key challenges and future directions, including multimodal integration and human-AI collaboration. Our survey aims to serve as a reference for researchers exploring LLMs for hypothesis generation.
'Quis custodiet ipsos custodes?' Who will watch the watchmen? On Detecting AI-generated peer-reviews
Oct 13, 2024
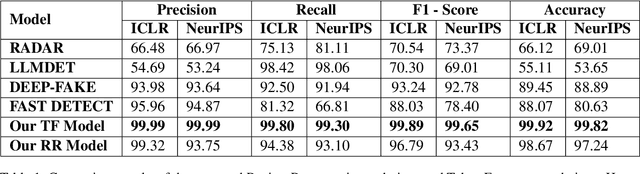

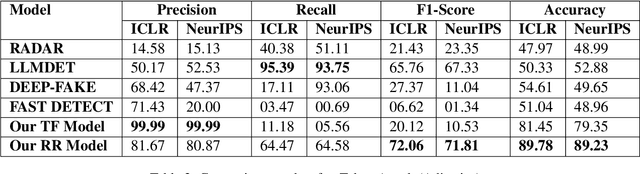
The integrity of the peer-review process is vital for maintaining scientific rigor and trust within the academic community. With the steady increase in the usage of large language models (LLMs) like ChatGPT in academic writing, there is a growing concern that AI-generated texts could compromise scientific publishing, including peer-reviews. Previous works have focused on generic AI-generated text detection or have presented an approach for estimating the fraction of peer-reviews that can be AI-generated. Our focus here is to solve a real-world problem by assisting the editor or chair in determining whether a review is written by ChatGPT or not. To address this, we introduce the Term Frequency (TF) model, which posits that AI often repeats tokens, and the Review Regeneration (RR) model, which is based on the idea that ChatGPT generates similar outputs upon re-prompting. We stress test these detectors against token attack and paraphrasing. Finally, we propose an effective defensive strategy to reduce the effect of paraphrasing on our models. Our findings suggest both our proposed methods perform better than the other AI text detectors. Our RR model is more robust, although our TF model performs better than the RR model without any attacks. We make our code, dataset, and model public.
AstroMLab 2: AstroLLaMA-2-70B Model and Benchmarking Specialised LLMs for Astronomy
Sep 29, 2024Continual pretraining of large language models on domain-specific data has been proposed to enhance performance on downstream tasks. In astronomy, the previous absence of astronomy-focused benchmarks has hindered objective evaluation of these specialized LLM models. Leveraging a recent initiative to curate high-quality astronomical MCQs, this study aims to quantitatively assess specialized LLMs in astronomy. We find that the previously released AstroLLaMA series, based on LLaMA-2-7B, underperforms compared to the base model. We demonstrate that this performance degradation can be partially mitigated by utilizing high-quality data for continual pretraining, such as summarized text from arXiv. Despite the observed catastrophic forgetting in smaller models, our results indicate that continual pretraining on the 70B model can yield significant improvements. However, the current supervised fine-tuning dataset still constrains the performance of instruct models. In conjunction with this study, we introduce a new set of models, AstroLLaMA-3-8B and AstroLLaMA-2-70B, building upon the previous AstroLLaMA series.
Can Large Language Models Unlock Novel Scientific Research Ideas?
Sep 10, 2024"An idea is nothing more nor less than a new combination of old elements" (Young, J.W.). The widespread adoption of Large Language Models (LLMs) and publicly available ChatGPT have marked a significant turning point in the integration of Artificial Intelligence (AI) into people's everyday lives. This study explores the capability of LLMs in generating novel research ideas based on information from research papers. We conduct a thorough examination of 4 LLMs in five domains (e.g., Chemistry, Computer, Economics, Medical, and Physics). We found that the future research ideas generated by Claude-2 and GPT-4 are more aligned with the author's perspective than GPT-3.5 and Gemini. We also found that Claude-2 generates more diverse future research ideas than GPT-4, GPT-3.5, and Gemini 1.0. We further performed a human evaluation of the novelty, relevancy, and feasibility of the generated future research ideas. This investigation offers insights into the evolving role of LLMs in idea generation, highlighting both its capability and limitations. Our work contributes to the ongoing efforts in evaluating and utilizing language models for generating future research ideas. We make our datasets and codes publicly available.
pathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.