 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.
Adversarial Fine-Tuning of Language Models: An Iterative Optimisation Approach for the Generation and Detection of Problematic Content
Aug 26, 2023

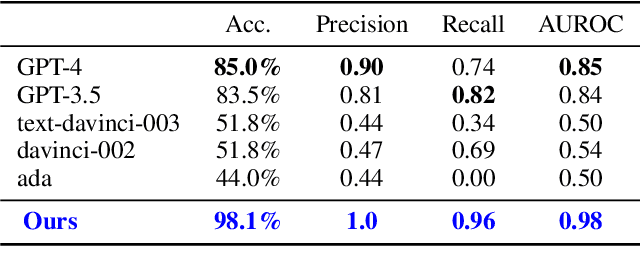

In this paper, we tackle the emerging challenge of unintended harmful content generation in Large Language Models (LLMs) with a novel dual-stage optimisation technique using adversarial fine-tuning. Our two-pronged approach employs an adversarial model, fine-tuned to generate potentially harmful prompts, and a judge model, iteratively optimised to discern these prompts. In this adversarial cycle, the two models seek to outperform each other in the prompting phase, generating a dataset of rich examples which are then used for fine-tuning. This iterative application of prompting and fine-tuning allows continuous refinement and improved performance. The performance of our approach is evaluated through classification accuracy on a dataset consisting of problematic prompts not detected by GPT-4, as well as a selection of contentious but unproblematic prompts. We show considerable increase in classification accuracy of the judge model on this challenging dataset as it undergoes the optimisation process. Furthermore, we show that a rudimentary model \texttt{ada} can achieve 13\% higher accuracy on the hold-out test set than GPT-4 after only a few rounds of this process, and that this fine-tuning improves performance in parallel tasks such as toxic comment identification.
Steering Language Generation: Harnessing Contrastive Expert Guidance and Negative Prompting for Coherent and Diverse Synthetic Data Generation
Aug 17, 2023



Large Language Models (LLMs) hold immense potential to generate synthetic data of high quality and utility, which has numerous applications from downstream model training to practical data utilisation. However, contemporary models, despite their impressive capacities, consistently struggle to produce both coherent and diverse data. To address the coherency issue, we introduce contrastive expert guidance, where the difference between the logit distributions of fine-tuned and base language models is emphasised to ensure domain adherence. In order to ensure diversity, we utilise existing real and synthetic examples as negative prompts to the model. We deem this dual-pronged approach to logit reshaping as STEER: Semantic Text Enhancement via Embedding Repositioning. STEER operates at inference-time and systematically guides the LLMs to strike a balance between adherence to the data distribution (ensuring semantic fidelity) and deviation from prior synthetic examples or existing real datasets (ensuring diversity and authenticity). This delicate balancing act is achieved by dynamically moving towards or away from chosen representations in the latent space. STEER demonstrates improved performance over previous synthetic data generation techniques, exhibiting better balance between data diversity and coherency across three distinct tasks: hypothesis generation, toxic and non-toxic comment generation, and commonsense reasoning task generation. We demonstrate how STEER allows for fine-tuned control over the diversity-coherency trade-off via its hyperparameters, highlighting its versatility.