 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Sharpness in Grokking
Feb 14, 2024Neural networks sometimes exhibit grokking, a phenomenon where perfect or near-perfect performance is achieved on a validation set well after the same performance has been obtained on the corresponding training set. In this workshop paper, we introduce a robust technique for measuring grokking, based on fitting an appropriate functional form. We then use this to investigate the sharpness of transitions in training and validation accuracy under two settings. The first setting is the theoretical framework developed by Levi et al. (2023) where closed form expressions are readily accessible. The second setting is a two-layer MLP trained to predict the parity of bits, with grokking induced by the concealment strategy of Miller et al. (2023). We find that trends between relative grokking gap and grokking sharpness are similar in both settings when using absolute and relative measures of sharpness. Reflecting on this, we make progress toward explaining some trends and identify the need for further study to untangle the various mechanisms which influence the sharpness of grokking.
Grokking Beyond Neural Networks: An Empirical Exploration with Model Complexity
Oct 26, 2023



In some settings neural networks exhibit a phenomenon known as grokking, where they achieve perfect or near-perfect accuracy on the validation set long after the same performance has been achieved on the training set. In this paper, we discover that grokking is not limited to neural networks but occurs in other settings such as Gaussian process (GP) classification, GP regression and linear regression. We also uncover a mechanism by which to induce grokking on algorithmic datasets via the addition of dimensions containing spurious information. The presence of the phenomenon in non-neural architectures provides evidence that grokking is not specific to SGD or weight norm regularisation. Instead, grokking may be possible in any setting where solution search is guided by complexity and error. Based on this insight and further trends we see in the training trajectories of a Bayesian neural network (BNN) and GP regression model, we make progress towards a more general theory of grokking. Specifically, we hypothesise that the phenomenon is governed by the accessibility of certain regions in the error and complexity landscapes.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023

Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
Adversarial Fine-Tuning of Language Models: An Iterative Optimisation Approach for the Generation and Detection of Problematic Content
Aug 26, 2023


In this paper, we tackle the emerging challenge of unintended harmful content generation in Large Language Models (LLMs) with a novel dual-stage optimisation technique using adversarial fine-tuning. Our two-pronged approach employs an adversarial model, fine-tuned to generate potentially harmful prompts, and a judge model, iteratively optimised to discern these prompts. In this adversarial cycle, the two models seek to outperform each other in the prompting phase, generating a dataset of rich examples which are then used for fine-tuning. This iterative application of prompting and fine-tuning allows continuous refinement and improved performance. The performance of our approach is evaluated through classification accuracy on a dataset consisting of problematic prompts not detected by GPT-4, as well as a selection of contentious but unproblematic prompts. We show considerable increase in classification accuracy of the judge model on this challenging dataset as it undergoes the optimisation process. Furthermore, we show that a rudimentary model \texttt{ada} can achieve 13\% higher accuracy on the hold-out test set than GPT-4 after only a few rounds of this process, and that this fine-tuning improves performance in parallel tasks such as toxic comment identification.
Steering Language Generation: Harnessing Contrastive Expert Guidance and Negative Prompting for Coherent and Diverse Synthetic Data Generation
Aug 17, 2023



Large Language Models (LLMs) hold immense potential to generate synthetic data of high quality and utility, which has numerous applications from downstream model training to practical data utilisation. However, contemporary models, despite their impressive capacities, consistently struggle to produce both coherent and diverse data. To address the coherency issue, we introduce contrastive expert guidance, where the difference between the logit distributions of fine-tuned and base language models is emphasised to ensure domain adherence. In order to ensure diversity, we utilise existing real and synthetic examples as negative prompts to the model. We deem this dual-pronged approach to logit reshaping as STEER: Semantic Text Enhancement via Embedding Repositioning. STEER operates at inference-time and systematically guides the LLMs to strike a balance between adherence to the data distribution (ensuring semantic fidelity) and deviation from prior synthetic examples or existing real datasets (ensuring diversity and authenticity). This delicate balancing act is achieved by dynamically moving towards or away from chosen representations in the latent space. STEER demonstrates improved performance over previous synthetic data generation techniques, exhibiting better balance between data diversity and coherency across three distinct tasks: hypothesis generation, toxic and non-toxic comment generation, and commonsense reasoning task generation. We demonstrate how STEER allows for fine-tuned control over the diversity-coherency trade-off via its hyperparameters, highlighting its versatility.
Beyond Low Earth Orbit: Biomonitoring, Artificial Intelligence, and Precision Space Health
Dec 22, 2021
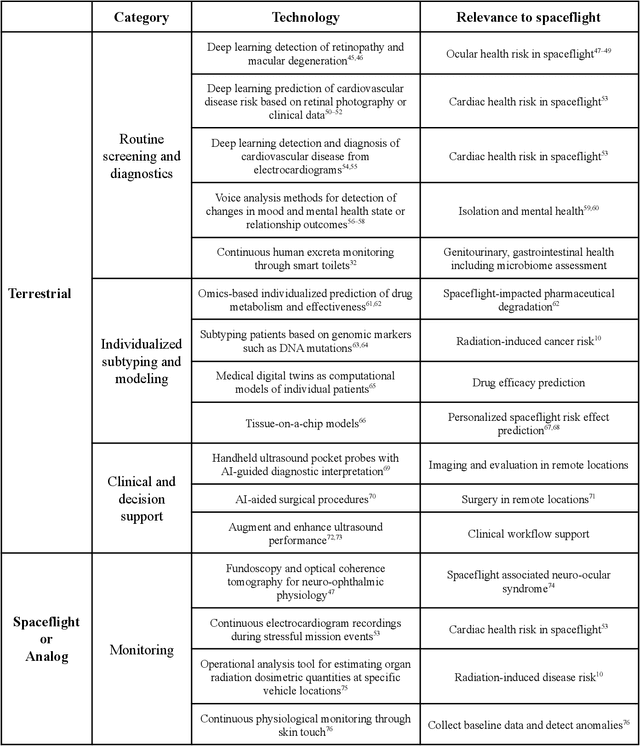
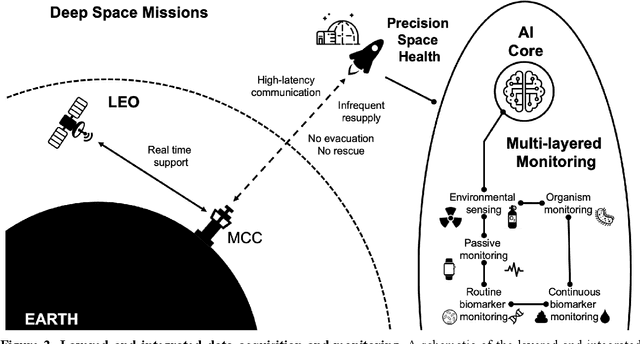
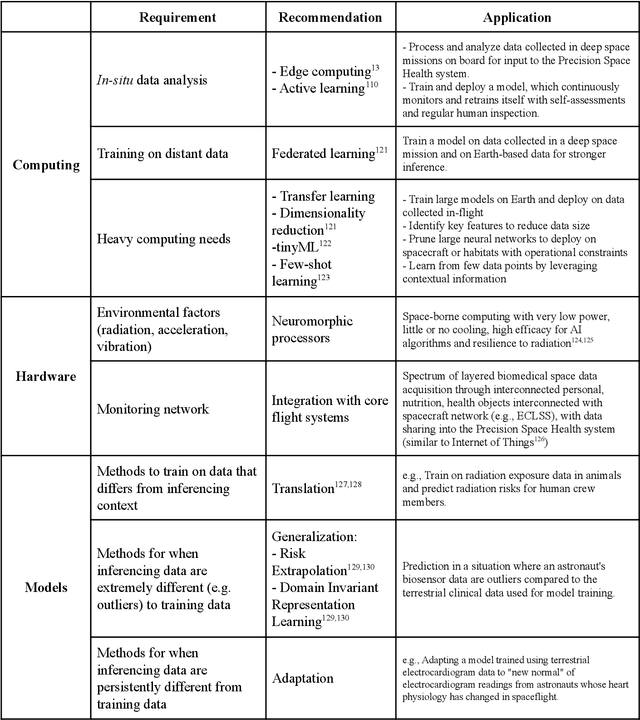
Human space exploration beyond low Earth orbit will involve missions of significant distance and duration. To effectively mitigate myriad space health hazards, paradigm shifts in data and space health systems are necessary to enable Earth-independence, rather than Earth-reliance. Promising developments in the fields of artificial intelligence and machine learning for biology and health can address these needs. We propose an appropriately autonomous and intelligent Precision Space Health system that will monitor, aggregate, and assess biomedical statuses; analyze and predict personalized adverse health outcomes; adapt and respond to newly accumulated data; and provide preventive, actionable, and timely insights to individual deep space crew members and iterative decision support to their crew medical officer. Here we present a summary of recommendations from a workshop organized by the National Aeronautics and Space Administration, on future applications of artificial intelligence in space biology and health. In the next decade, biomonitoring technology, biomarker science, spacecraft hardware, intelligent software, and streamlined data management must mature and be woven together into a Precision Space Health system to enable humanity to thrive in deep space.
Beyond Low Earth Orbit: Biological Research, Artificial Intelligence, and Self-Driving Labs
Dec 22, 2021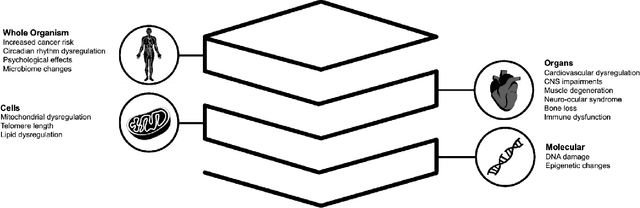
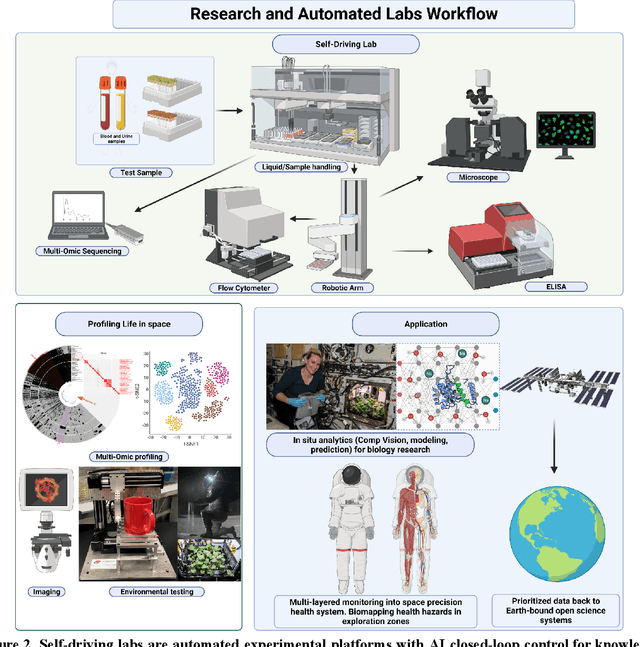
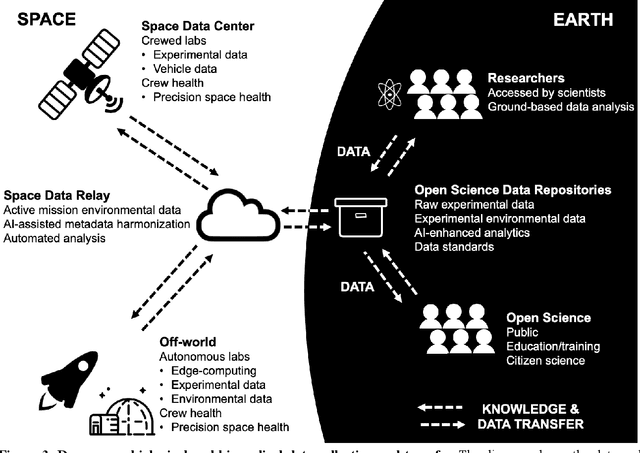
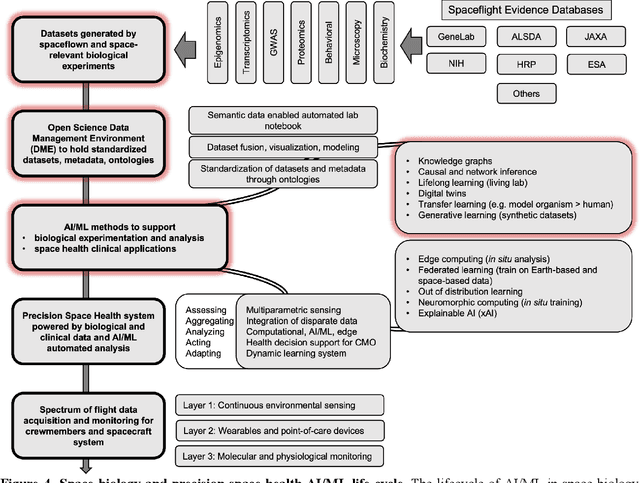
Space biology research aims to understand fundamental effects of spaceflight on organisms, develop foundational knowledge to support deep space exploration, and ultimately bioengineer spacecraft and habitats to stabilize the ecosystem of plants, crops, microbes, animals, and humans for sustained multi-planetary life. To advance these aims, the field leverages experiments, platforms, data, and model organisms from both spaceborne and ground-analog studies. As research is extended beyond low Earth orbit, experiments and platforms must be maximally autonomous, light, agile, and intelligent to expedite knowledge discovery. Here we present a summary of recommendations from a workshop organized by the National Aeronautics and Space Administration on artificial intelligence, machine learning, and modeling applications which offer key solutions toward these space biology challenges. In the next decade, the synthesis of artificial intelligence into the field of space biology will deepen the biological understanding of spaceflight effects, facilitate predictive modeling and analytics, support maximally autonomous and reproducible experiments, and efficiently manage spaceborne data and metadata, all with the goal to enable life to thrive in deep space.