 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstroLLaVA: towards the unification of astronomical data and natural language
Apr 11, 2025
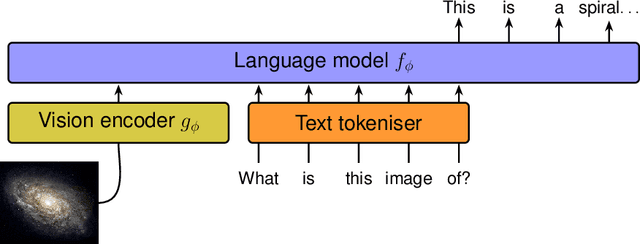


We present AstroLLaVA, a vision language model for astronomy that enables interaction with astronomical imagery through natural dialogue. By fine-tuning the LLaVA model on a diverse dataset of $\sim$30k images with captions and question-answer pairs sourced from NASA's `Astronomy Picture of the Day', the European Southern Observatory, and the NASA/ESA Hubble Space Telescope, we create a model capable of answering open-ended questions about astronomical concepts depicted visually. Our two-stage fine-tuning process adapts the model to both image captioning and visual question answering in the astronomy domain. We demonstrate AstroLLaVA's performance on an astronomical visual question answering benchmark and release the model weights, code, and training set to encourage further open source work in this space. Finally, we suggest a roadmap towards general astronomical data alignment with pre-trained language models, and provide an open space for collaboration towards this end for interested researchers.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023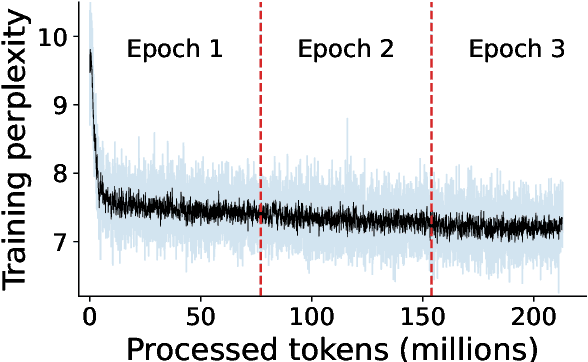

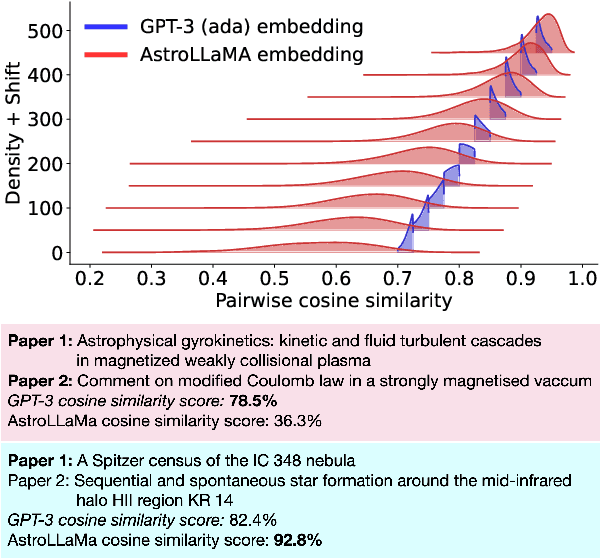
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.