 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupernova Event Dataset: Interpreting Large Language Model's Personality through Critical Event Analysis
Jun 13, 2025Large Language Models (LLMs) are increasingly integrated into everyday applications. As their influence grows, understanding their decision making and underlying personality becomes essential. In this work, we interpret model personality using our proposed Supernova Event Dataset, a novel dataset with diverse articles spanning biographies, historical events, news, and scientific discoveries. We use this dataset to benchmark LLMs on extracting and ranking key events from text, a subjective and complex challenge that requires reasoning over long-range context and modeling causal chains. We evaluate small models like Phi-4, Orca 2, and Qwen 2.5, and large, stronger models such as Claude 3.7, Gemini 2.5, and OpenAI o3, and propose a framework where another LLM acts as a judge to infer each model's personality based on its selection and classification of events. Our analysis shows distinct personality traits: for instance, Orca 2 demonstrates emotional reasoning focusing on interpersonal dynamics, while Qwen 2.5 displays a more strategic, analytical style. When analyzing scientific discovery events, Claude Sonnet 3.7 emphasizes conceptual framing, Gemini 2.5 Pro prioritizes empirical validation, and o3 favors step-by-step causal reasoning. This analysis improves model interpretability, making them user-friendly for a wide range of diverse applications.
Sparks of Science: Hypothesis Generation Using Structured Paper Data
Apr 17, 2025



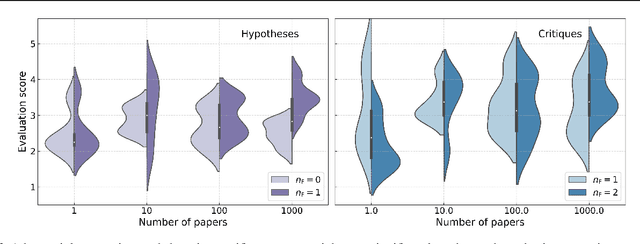
Generating novel and creative scientific hypotheses is a cornerstone in achieving Artificial General Intelligence. Large language and reasoning models have the potential to aid in the systematic creation, selection, and validation of scientifically informed hypotheses. However, current foundation models often struggle to produce scientific ideas that are both novel and feasible. One reason is the lack of a dedicated dataset that frames Scientific Hypothesis Generation (SHG) as a Natural Language Generation (NLG) task. In this paper, we introduce HypoGen, the first dataset of approximately 5500 structured problem-hypothesis pairs extracted from top-tier computer science conferences structured with a Bit-Flip-Spark schema, where the Bit is the conventional assumption, the Spark is the key insight or conceptual leap, and the Flip is the resulting counterproposal. HypoGen uniquely integrates an explicit Chain-of-Reasoning component that reflects the intellectual process from Bit to Flip. We demonstrate that framing hypothesis generation as conditional language modelling, with the model fine-tuned on Bit-Flip-Spark and the Chain-of-Reasoning (and where, at inference, we only provide the Bit), leads to improvements in the overall quality of the hypotheses. Our evaluation employs automated metrics and LLM judge rankings for overall quality assessment. We show that by fine-tuning on our HypoGen dataset we improve the novelty, feasibility, and overall quality of the generated hypotheses. The HypoGen dataset is publicly available at huggingface.co/datasets/UniverseTBD/hypogen-dr1.
A Survey on Hypothesis Generation for Scientific Discovery in the Era of Large Language Models
Apr 07, 2025Hypothesis generation is a fundamental step in scientific discovery, yet it is increasingly challenged by information overload and disciplinary fragmentation. Recent advances in Large Language Models (LLMs) have sparked growing interest in their potential to enhance and automate this process. This paper presents a comprehensive survey of hypothesis generation with LLMs by (i) reviewing existing methods, from simple prompting techniques to more complex frameworks, and proposing a taxonomy that categorizes these approaches; (ii) analyzing techniques for improving hypothesis quality, such as novelty boosting and structured reasoning; (iii) providing an overview of evaluation strategies; and (iv) discussing key challenges and future directions, including multimodal integration and human-AI collaboration. Our survey aims to serve as a reference for researchers exploring LLMs for hypothesis generation.
Experimenting with Large Language Models and vector embeddings in NASA SciX
Dec 21, 2023Open-source Large Language Models enable projects such as NASA SciX (i.e., NASA ADS) to think out of the box and try alternative approaches for information retrieval and data augmentation, while respecting data copyright and users' privacy. However, when large language models are directly prompted with questions without any context, they are prone to hallucination. At NASA SciX we have developed an experiment where we created semantic vectors for our large collection of abstracts and full-text content, and we designed a prompt system to ask questions using contextual chunks from our system. Based on a non-systematic human evaluation, the experiment shows a lower degree of hallucination and better responses when using Retrieval Augmented Generation. Further exploration is required to design new features and data augmentation processes at NASA SciX that leverages this technology while respecting the high level of trust and quality that the project holds.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023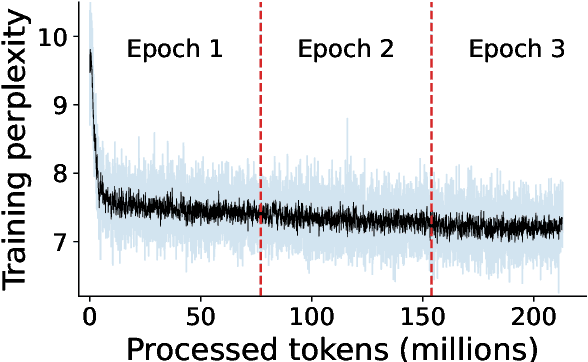

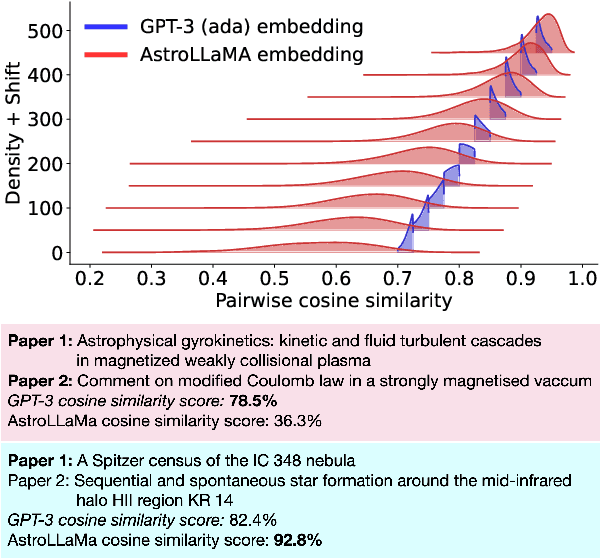
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.
Harnessing the Power of Adversarial Prompting and Large Language Models for Robust Hypothesis Generation in Astronomy
Jun 20, 2023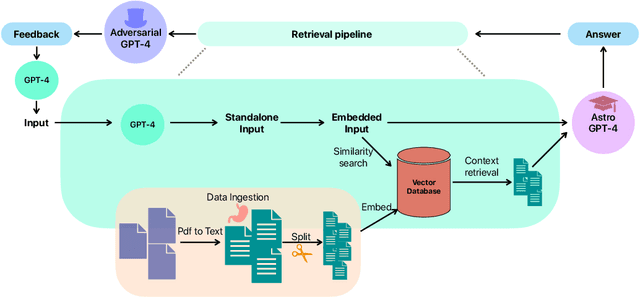
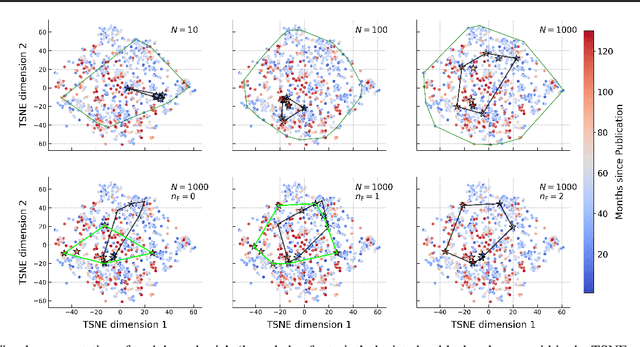
This study investigates the application of Large Language Models (LLMs), specifically GPT-4, within Astronomy. We employ in-context prompting, supplying the model with up to 1000 papers from the NASA Astrophysics Data System, to explore the extent to which performance can be improved by immersing the model in domain-specific literature. Our findings point towards a substantial boost in hypothesis generation when using in-context prompting, a benefit that is further accentuated by adversarial prompting. We illustrate how adversarial prompting empowers GPT-4 to extract essential details from a vast knowledge base to produce meaningful hypotheses, signaling an innovative step towards employing LLMs for scientific research in Astronomy.
Galactic ChitChat: Using Large Language Models to Converse with Astronomy Literature
Apr 12, 2023We demonstrate the potential of the state-of-the-art OpenAI GPT-4 large language model to engage in meaningful interactions with Astronomy papers using in-context prompting. To optimize for efficiency, we employ a distillation technique that effectively reduces the size of the original input paper by 50\%, while maintaining the paragraph structure and overall semantic integrity. We then explore the model's responses using a multi-document context (ten distilled documents). Our findings indicate that GPT-4 excels in the multi-document domain, providing detailed answers contextualized within the framework of related research findings. Our results showcase the potential of large language models for the astronomical community, offering a promising avenue for further exploration, particularly the possibility of utilizing the models for hypothesis generation.