 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstroLLaVA: towards the unification of astronomical data and natural language
Apr 11, 2025
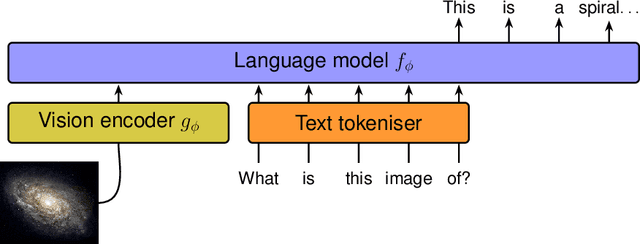


We present AstroLLaVA, a vision language model for astronomy that enables interaction with astronomical imagery through natural dialogue. By fine-tuning the LLaVA model on a diverse dataset of $\sim$30k images with captions and question-answer pairs sourced from NASA's `Astronomy Picture of the Day', the European Southern Observatory, and the NASA/ESA Hubble Space Telescope, we create a model capable of answering open-ended questions about astronomical concepts depicted visually. Our two-stage fine-tuning process adapts the model to both image captioning and visual question answering in the astronomy domain. We demonstrate AstroLLaVA's performance on an astronomical visual question answering benchmark and release the model weights, code, and training set to encourage further open source work in this space. Finally, we suggest a roadmap towards general astronomical data alignment with pre-trained language models, and provide an open space for collaboration towards this end for interested researchers.
A Survey on Hypothesis Generation for Scientific Discovery in the Era of Large Language Models
Apr 07, 2025Hypothesis generation is a fundamental step in scientific discovery, yet it is increasingly challenged by information overload and disciplinary fragmentation. Recent advances in Large Language Models (LLMs) have sparked growing interest in their potential to enhance and automate this process. This paper presents a comprehensive survey of hypothesis generation with LLMs by (i) reviewing existing methods, from simple prompting techniques to more complex frameworks, and proposing a taxonomy that categorizes these approaches; (ii) analyzing techniques for improving hypothesis quality, such as novelty boosting and structured reasoning; (iii) providing an overview of evaluation strategies; and (iv) discussing key challenges and future directions, including multimodal integration and human-AI collaboration. Our survey aims to serve as a reference for researchers exploring LLMs for hypothesis generation.
Machine learning-driven Anomaly Detection and Forecasting for Euclid Space Telescope Operations
Nov 08, 2024

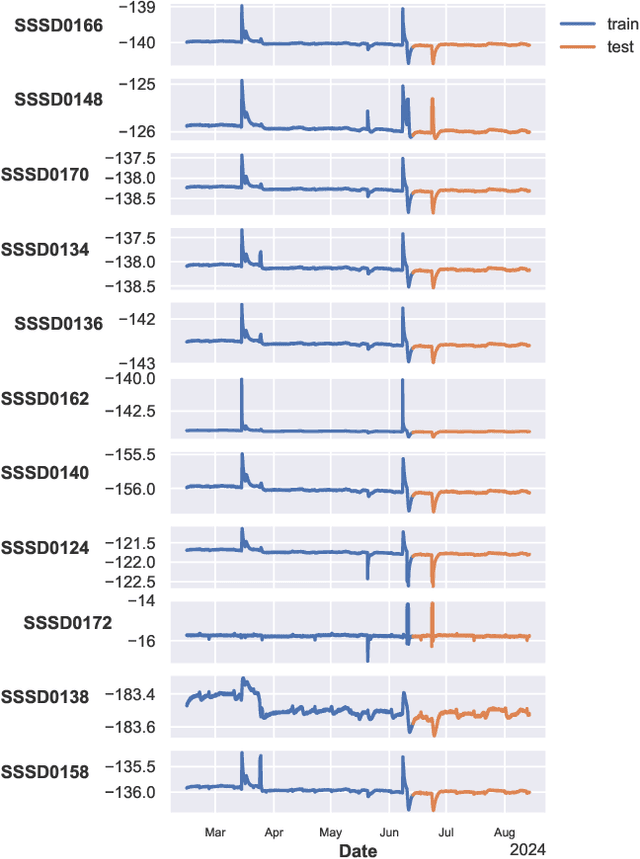
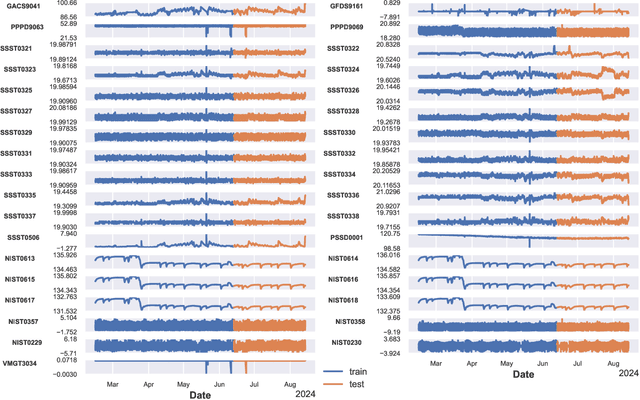
State-of-the-art space science missions increasingly rely on automation due to spacecraft complexity and the costs of human oversight. The high volume of data, including scientific and telemetry data, makes manual inspection challenging. Machine learning offers significant potential to meet these demands. The Euclid space telescope, in its survey phase since February 2024, exemplifies this shift. Euclid's success depends on accurate monitoring and interpretation of housekeeping telemetry and science-derived data. Thousands of telemetry parameters, monitored as time series, may or may not impact the quality of scientific data. These parameters have complex interdependencies, often due to physical relationships (e.g., proximity of temperature sensors). Optimising science operations requires careful anomaly detection and identification of hidden parameter states. Moreover, understanding the interactions between known anomalies and physical quantities is crucial yet complex, as related parameters may display anomalies with varied timing and intensity. We address these challenges by analysing temperature anomalies in Euclid's telemetry from February to August 2024, focusing on eleven temperature parameters and 35 covariates. We use a predictive XGBoost model to forecast temperatures based on historical values, detecting anomalies as deviations from predictions. A second XGBoost model predicts anomalies from covariates, capturing their relationships to temperature anomalies. We identify the top three anomalies per parameter and analyse their interactions with covariates using SHAP (Shapley Additive Explanations), enabling rapid, automated analysis of complex parameter relationships. Our method demonstrates how machine learning can enhance telemetry monitoring, offering scalable solutions for other missions with similar data challenges.
pathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.
Delving into the Utilisation of ChatGPT in Scientific Publications in Astronomy
Jun 25, 2024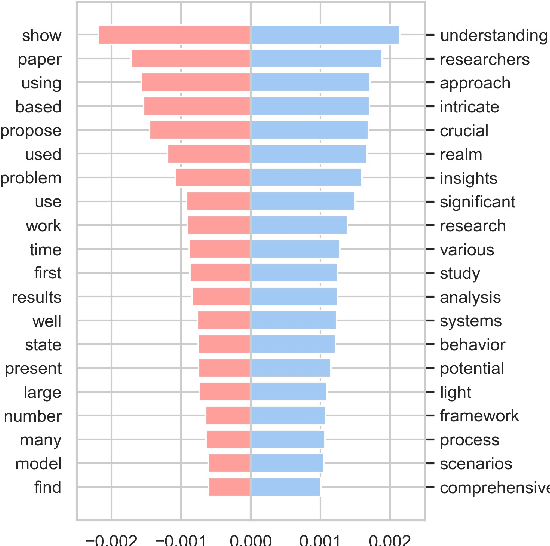
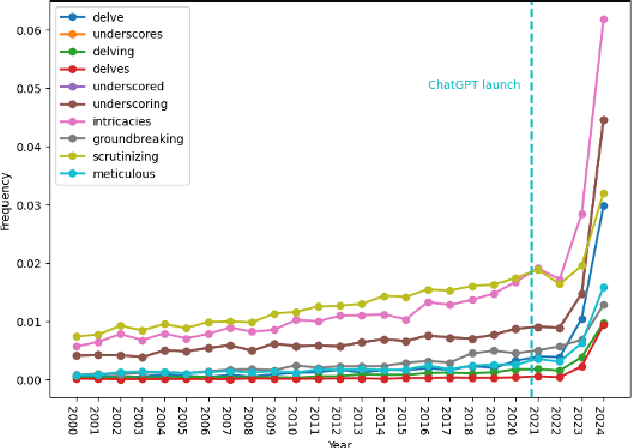
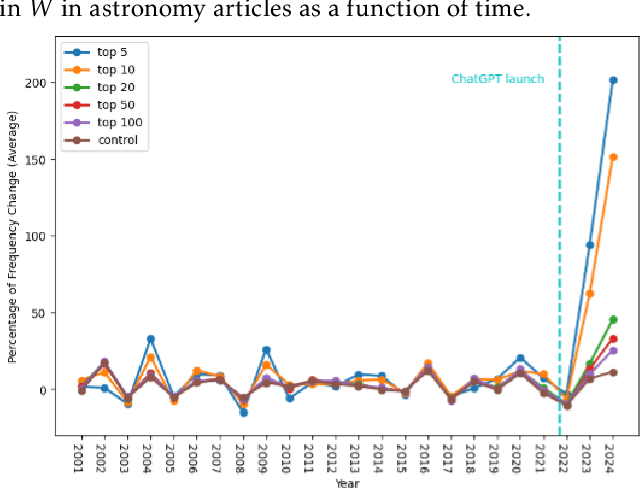
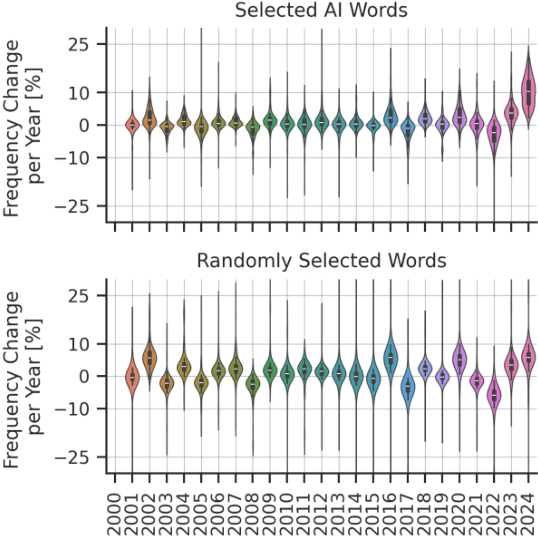
Rapid progress in the capabilities of machine learning approaches in natural language processing has culminated in the rise of large language models over the last two years. Recent works have shown unprecedented adoption of these for academic writing, especially in some fields, but their pervasiveness in astronomy has not been studied sufficiently. To remedy this, we extract words that ChatGPT uses more often than humans when generating academic text and search a total of 1 million articles for them. This way, we assess the frequency of word occurrence in published works in astronomy tracked by the NASA Astrophysics Data System since 2000. We then perform a statistical analysis of the occurrences. We identify a list of words favoured by ChatGPT and find a statistically significant increase for these words against a control group in 2024, which matches the trend in other disciplines. These results suggest a widespread adoption of these models in the writing of astronomy papers. We encourage organisations, publishers, and researchers to work together to identify ethical and pragmatic guidelines to maximise the benefits of these systems while maintaining scientific rigour.
XAMI -- A Benchmark Dataset for Artefact Detection in XMM-Newton Optical Images
Jun 25, 2024
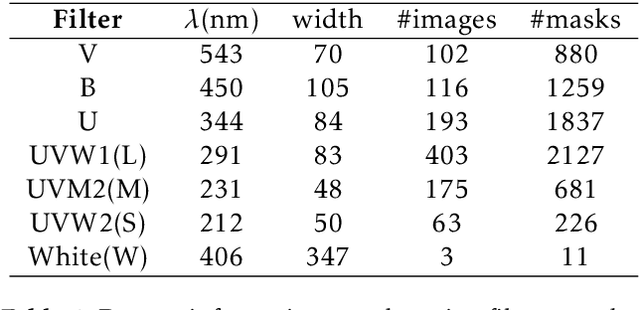
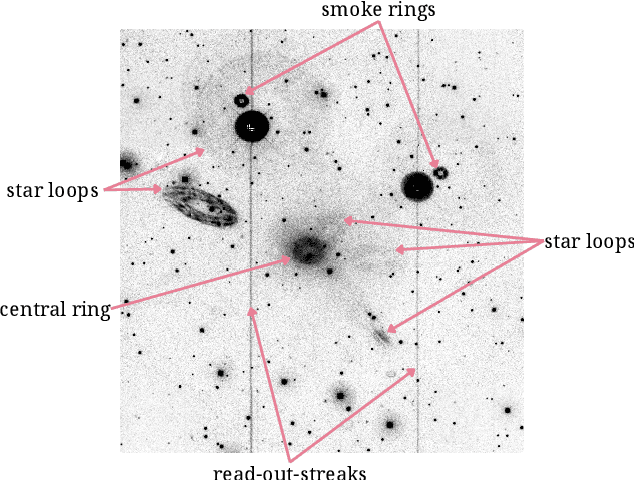
Reflected or scattered light produce artefacts in astronomical observations that can negatively impact the scientific study. Hence, automated detection of these artefacts is highly beneficial, especially with the increasing amounts of data gathered. Machine learning methods are well-suited to this problem, but currently there is a lack of annotated data to train such approaches to detect artefacts in astronomical observations. In this work, we present a dataset of images from the XMM-Newton space telescope Optical Monitoring camera showing different types of artefacts. We hand-annotated a sample of 1000 images with artefacts which we use to train automated ML methods. We further demonstrate techniques tailored for accurate detection and masking of artefacts using instance segmentation. We adopt a hybrid approach, combining knowledge from both convolutional neural networks (CNNs) and transformer-based models and use their advantages in segmentation. The presented method and dataset will advance artefact detection in astronomical observations by providing a reproducible baseline. All code and data are made available (https://github.com/ESA-Datalabs/XAMI-model and https://github.com/ESA-Datalabs/XAMI-dataset).
Designing an Evaluation Framework for Large Language Models in Astronomy Research
May 30, 2024


Large Language Models (LLMs) are shifting how scientific research is done. It is imperative to understand how researchers interact with these models and how scientific sub-communities like astronomy might benefit from them. However, there is currently no standard for evaluating the use of LLMs in astronomy. Therefore, we present the experimental design for an evaluation study on how astronomy researchers interact with LLMs. We deploy a Slack chatbot that can answer queries from users via Retrieval-Augmented Generation (RAG); these responses are grounded in astronomy papers from arXiv. We record and anonymize user questions and chatbot answers, user upvotes and downvotes to LLM responses, user feedback to the LLM, and retrieved documents and similarity scores with the query. Our data collection method will enable future dynamic evaluations of LLM tools for astronomy.
Scaling Laws for Galaxy Images
Apr 03, 2024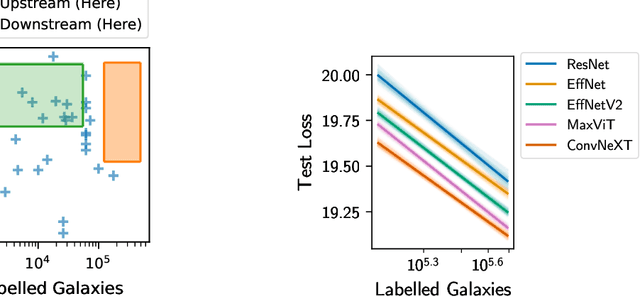
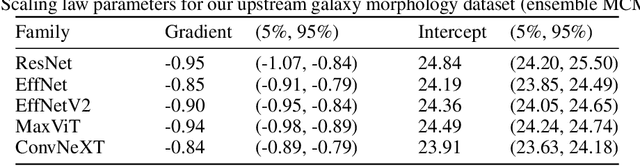
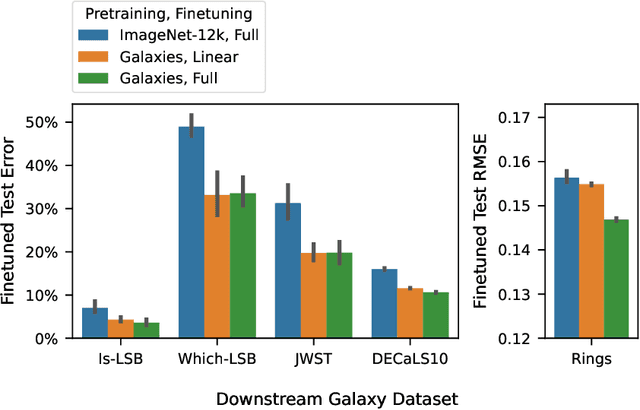
We present the first systematic investigation of supervised scaling laws outside of an ImageNet-like context - on images of galaxies. We use 840k galaxy images and over 100M annotations by Galaxy Zoo volunteers, comparable in scale to Imagenet-1K. We find that adding annotated galaxy images provides a power law improvement in performance across all architectures and all tasks, while adding trainable parameters is effective only for some (typically more subjectively challenging) tasks. We then compare the downstream performance of finetuned models pretrained on either ImageNet-12k alone vs. additionally pretrained on our galaxy images. We achieve an average relative error rate reduction of 31% across 5 downstream tasks of scientific interest. Our finetuned models are more label-efficient and, unlike their ImageNet-12k-pretrained equivalents, often achieve linear transfer performance equal to that of end-to-end finetuning. We find relatively modest additional downstream benefits from scaling model size, implying that scaling alone is not sufficient to address our domain gap, and suggest that practitioners with qualitatively different images might benefit more from in-domain adaption followed by targeted downstream labelling.
AstroLLaMA-Chat: Scaling AstroLLaMA with Conversational and Diverse Datasets
Jan 05, 2024We explore the potential of enhancing LLM performance in astronomy-focused question-answering through targeted, continual pre-training. By employing a compact 7B-parameter LLaMA-2 model and focusing exclusively on a curated set of astronomy corpora -- comprising abstracts, introductions, and conclusions -- we achieve notable improvements in specialized topic comprehension. While general LLMs like GPT-4 excel in broader question-answering scenarios due to superior reasoning capabilities, our findings suggest that continual pre-training with limited resources can still enhance model performance on specialized topics. Additionally, we present an extension of AstroLLaMA: the fine-tuning of the 7B LLaMA model on a domain-specific conversational dataset, culminating in the release of the chat-enabled AstroLLaMA for community use. Comprehensive quantitative benchmarking is currently in progress and will be detailed in an upcoming full paper. The model, AstroLLaMA-Chat, is now available at https://huggingface.co/universeTBD, providing the first open-source conversational AI tool tailored for the astronomy community.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023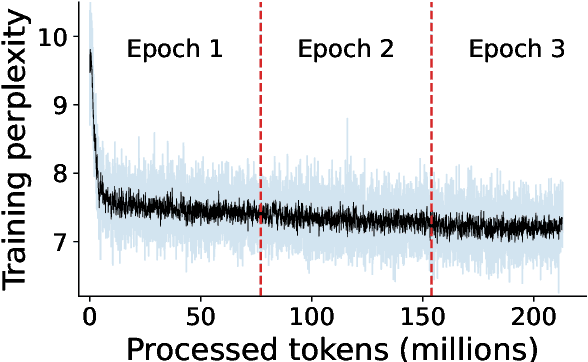

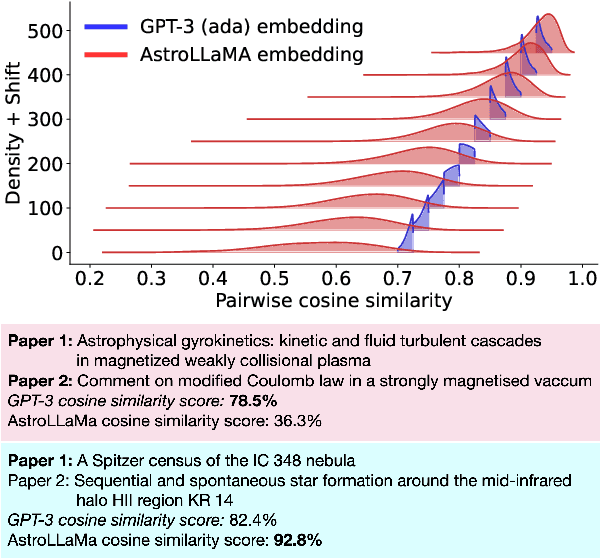
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.