 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning-driven Anomaly Detection and Forecasting for Euclid Space Telescope Operations
Nov 08, 2024

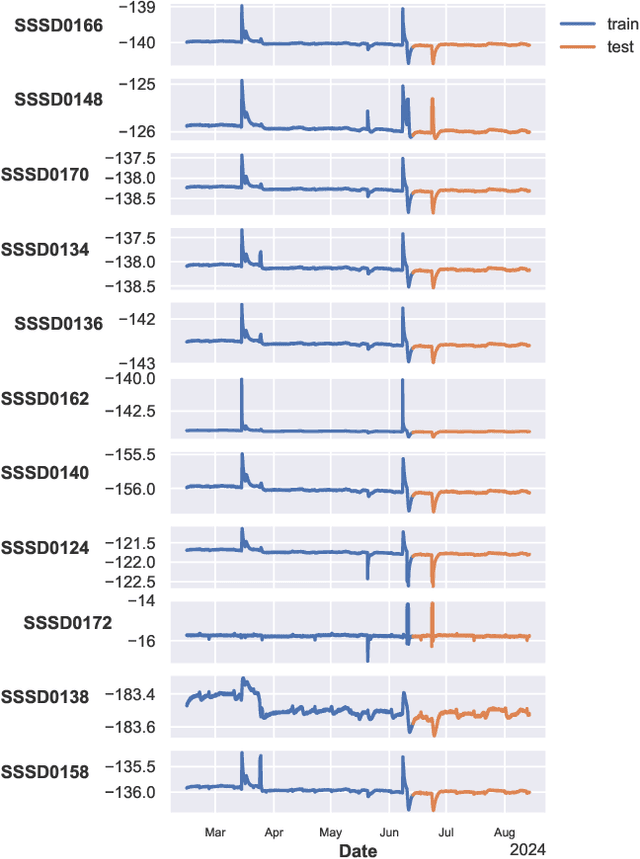
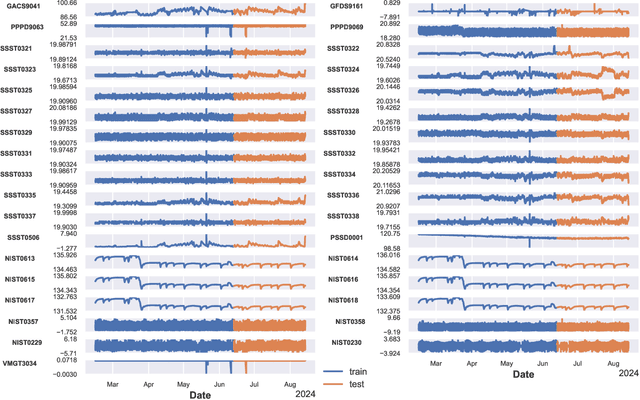
State-of-the-art space science missions increasingly rely on automation due to spacecraft complexity and the costs of human oversight. The high volume of data, including scientific and telemetry data, makes manual inspection challenging. Machine learning offers significant potential to meet these demands. The Euclid space telescope, in its survey phase since February 2024, exemplifies this shift. Euclid's success depends on accurate monitoring and interpretation of housekeeping telemetry and science-derived data. Thousands of telemetry parameters, monitored as time series, may or may not impact the quality of scientific data. These parameters have complex interdependencies, often due to physical relationships (e.g., proximity of temperature sensors). Optimising science operations requires careful anomaly detection and identification of hidden parameter states. Moreover, understanding the interactions between known anomalies and physical quantities is crucial yet complex, as related parameters may display anomalies with varied timing and intensity. We address these challenges by analysing temperature anomalies in Euclid's telemetry from February to August 2024, focusing on eleven temperature parameters and 35 covariates. We use a predictive XGBoost model to forecast temperatures based on historical values, detecting anomalies as deviations from predictions. A second XGBoost model predicts anomalies from covariates, capturing their relationships to temperature anomalies. We identify the top three anomalies per parameter and analyse their interactions with covariates using SHAP (Shapley Additive Explanations), enabling rapid, automated analysis of complex parameter relationships. Our method demonstrates how machine learning can enhance telemetry monitoring, offering scalable solutions for other missions with similar data challenges.
Delving into the Utilisation of ChatGPT in Scientific Publications in Astronomy
Jun 25, 2024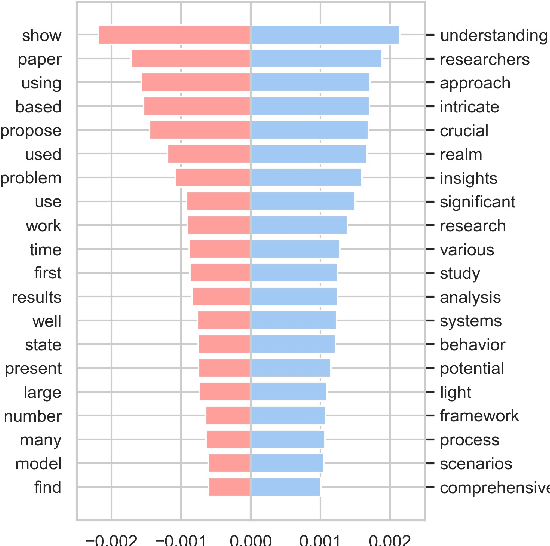
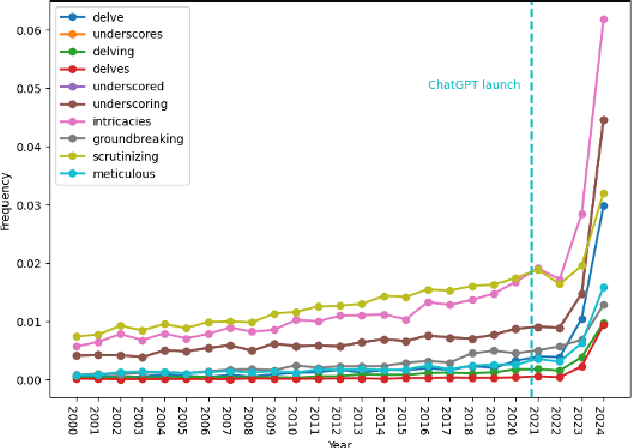
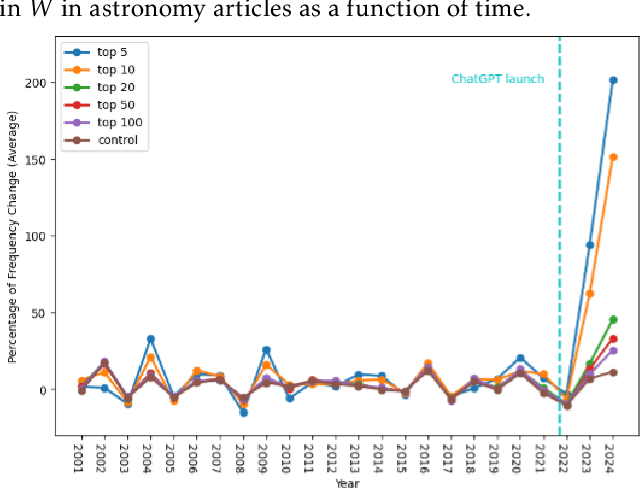
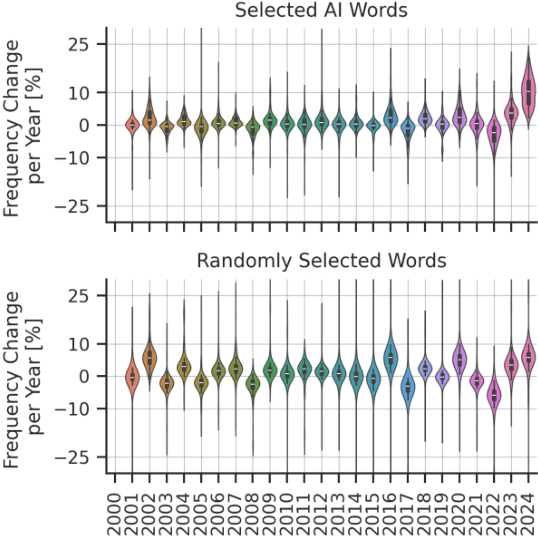
Rapid progress in the capabilities of machine learning approaches in natural language processing has culminated in the rise of large language models over the last two years. Recent works have shown unprecedented adoption of these for academic writing, especially in some fields, but their pervasiveness in astronomy has not been studied sufficiently. To remedy this, we extract words that ChatGPT uses more often than humans when generating academic text and search a total of 1 million articles for them. This way, we assess the frequency of word occurrence in published works in astronomy tracked by the NASA Astrophysics Data System since 2000. We then perform a statistical analysis of the occurrences. We identify a list of words favoured by ChatGPT and find a statistically significant increase for these words against a control group in 2024, which matches the trend in other disciplines. These results suggest a widespread adoption of these models in the writing of astronomy papers. We encourage organisations, publishers, and researchers to work together to identify ethical and pragmatic guidelines to maximise the benefits of these systems while maintaining scientific rigour.