 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training vision models for the classification of alerts from wide-field time-domain surveys
Dec 12, 2025Modern wide-field time-domain surveys facilitate the study of transient, variable and moving phenomena by conducting image differencing and relaying alerts to their communities. Machine learning tools have been used on data from these surveys and their precursors for more than a decade, and convolutional neural networks (CNNs), which make predictions directly from input images, saw particularly broad adoption through the 2010s. Since then, continually rapid advances in computer vision have transformed the standard practices around using such models. It is now commonplace to use standardized architectures pre-trained on large corpora of everyday images (e.g., ImageNet). In contrast, time-domain astronomy studies still typically design custom CNN architectures and train them from scratch. Here, we explore the affects of adopting various pre-training regimens and standardized model architectures on the performance of alert classification. We find that the resulting models match or outperform a custom, specialized CNN like what is typically used for filtering alerts. Moreover, our results show that pre-training on galaxy images from Galaxy Zoo tends to yield better performance than pre-training on ImageNet or training from scratch. We observe that the design of standardized architectures are much better optimized than the custom CNN baseline, requiring significantly less time and memory for inference despite having more trainable parameters. On the eve of the Legacy Survey of Space and Time and other image-differencing surveys, these findings advocate for a paradigm shift in the creation of vision models for alerts, demonstrating that greater performance and efficiency, in time and in data, can be achieved by adopting the latest practices from the computer vision field.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025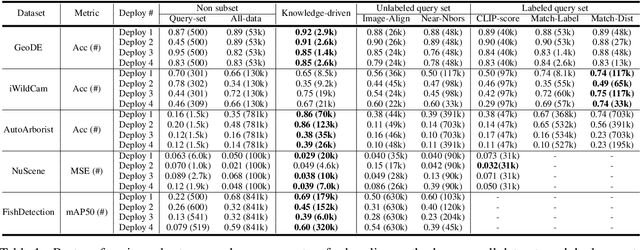
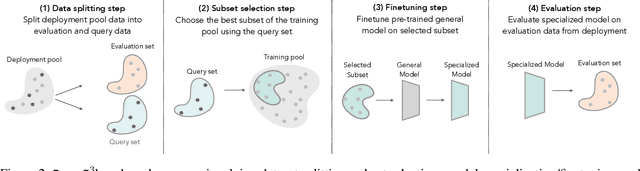
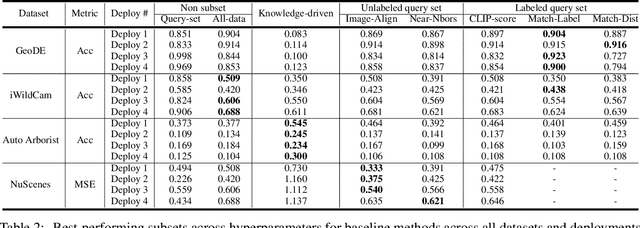
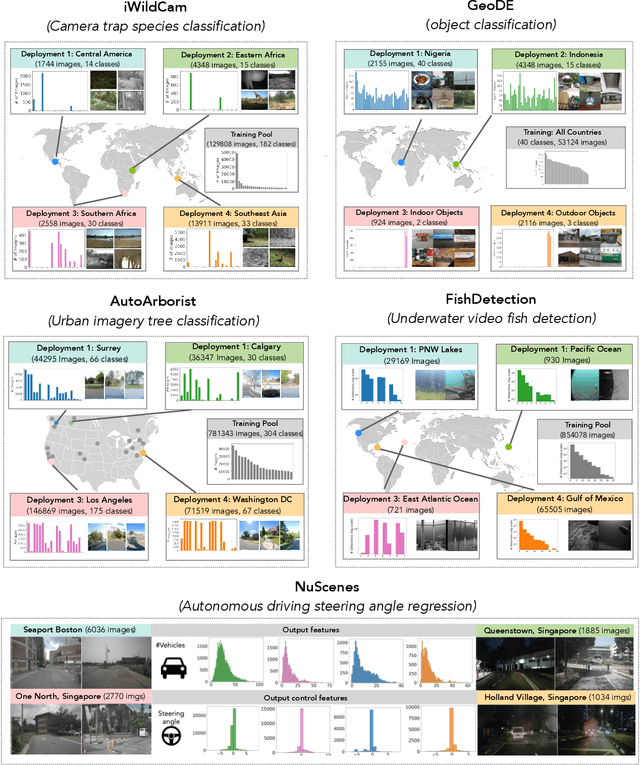
In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
Sparks of Science: Hypothesis Generation Using Structured Paper Data
Apr 17, 2025



Generating novel and creative scientific hypotheses is a cornerstone in achieving Artificial General Intelligence. Large language and reasoning models have the potential to aid in the systematic creation, selection, and validation of scientifically informed hypotheses. However, current foundation models often struggle to produce scientific ideas that are both novel and feasible. One reason is the lack of a dedicated dataset that frames Scientific Hypothesis Generation (SHG) as a Natural Language Generation (NLG) task. In this paper, we introduce HypoGen, the first dataset of approximately 5500 structured problem-hypothesis pairs extracted from top-tier computer science conferences structured with a Bit-Flip-Spark schema, where the Bit is the conventional assumption, the Spark is the key insight or conceptual leap, and the Flip is the resulting counterproposal. HypoGen uniquely integrates an explicit Chain-of-Reasoning component that reflects the intellectual process from Bit to Flip. We demonstrate that framing hypothesis generation as conditional language modelling, with the model fine-tuned on Bit-Flip-Spark and the Chain-of-Reasoning (and where, at inference, we only provide the Bit), leads to improvements in the overall quality of the hypotheses. Our evaluation employs automated metrics and LLM judge rankings for overall quality assessment. We show that by fine-tuning on our HypoGen dataset we improve the novelty, feasibility, and overall quality of the generated hypotheses. The HypoGen dataset is publicly available at huggingface.co/datasets/UniverseTBD/hypogen-dr1.
SIDDA: SInkhorn Dynamic Domain Adaptation for Image Classification with Equivariant Neural Networks
Jan 23, 2025



Modern neural networks (NNs) often do not generalize well in the presence of a "covariate shift"; that is, in situations where the training and test data distributions differ, but the conditional distribution of classification labels remains unchanged. In such cases, NN generalization can be reduced to a problem of learning more domain-invariant features. Domain adaptation (DA) methods include a range of techniques aimed at achieving this; however, these methods have struggled with the need for extensive hyperparameter tuning, which then incurs significant computational costs. In this work, we introduce SIDDA, an out-of-the-box DA training algorithm built upon the Sinkhorn divergence, that can achieve effective domain alignment with minimal hyperparameter tuning and computational overhead. We demonstrate the efficacy of our method on multiple simulated and real datasets of varying complexity, including simple shapes, handwritten digits, and real astronomical observations. SIDDA is compatible with a variety of NN architectures, and it works particularly well in improving classification accuracy and model calibration when paired with equivariant neural networks (ENNs). We find that SIDDA enhances the generalization capabilities of NNs, achieving up to a $\approx40\%$ improvement in classification accuracy on unlabeled target data. We also study the efficacy of DA on ENNs with respect to the varying group orders of the dihedral group $D_N$, and find that the model performance improves as the degree of equivariance increases. Finally, we find that SIDDA enhances model calibration on both source and target data--achieving over an order of magnitude improvement in the ECE and Brier score. SIDDA's versatility, combined with its automated approach to domain alignment, has the potential to advance multi-dataset studies by enabling the development of highly generalizable models.
pathfinder: A Semantic Framework for Literature Review and Knowledge Discovery in Astronomy
Aug 02, 2024



The exponential growth of astronomical literature poses significant challenges for researchers navigating and synthesizing general insights or even domain-specific knowledge. We present Pathfinder, a machine learning framework designed to enable literature review and knowledge discovery in astronomy, focusing on semantic searching with natural language instead of syntactic searches with keywords. Utilizing state-of-the-art large language models (LLMs) and a corpus of 350,000 peer-reviewed papers from the Astrophysics Data System (ADS), Pathfinder offers an innovative approach to scientific inquiry and literature exploration. Our framework couples advanced retrieval techniques with LLM-based synthesis to search astronomical literature by semantic context as a complement to currently existing methods that use keywords or citation graphs. It addresses complexities of jargon, named entities, and temporal aspects through time-based and citation-based weighting schemes. We demonstrate the tool's versatility through case studies, showcasing its application in various research scenarios. The system's performance is evaluated using custom benchmarks, including single-paper and multi-paper tasks. Beyond literature review, Pathfinder offers unique capabilities for reformatting answers in ways that are accessible to various audiences (e.g. in a different language or as simplified text), visualizing research landscapes, and tracking the impact of observatories and methodologies. This tool represents a significant advancement in applying AI to astronomical research, aiding researchers at all career stages in navigating modern astronomy literature.
Scaling Laws for Galaxy Images
Apr 03, 2024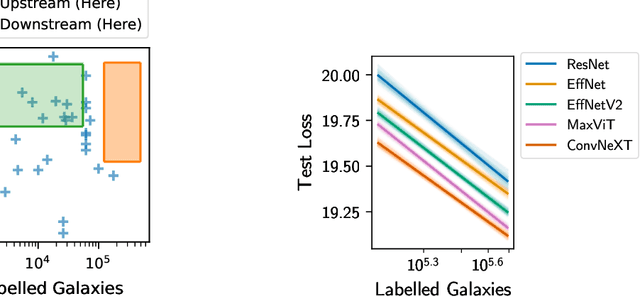
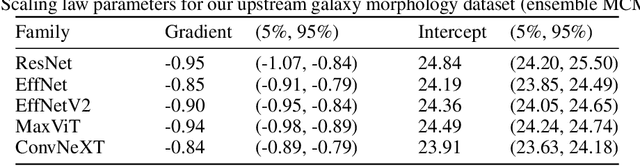
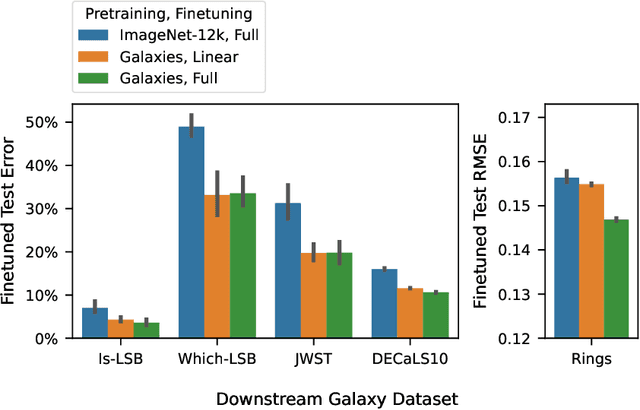
We present the first systematic investigation of supervised scaling laws outside of an ImageNet-like context - on images of galaxies. We use 840k galaxy images and over 100M annotations by Galaxy Zoo volunteers, comparable in scale to Imagenet-1K. We find that adding annotated galaxy images provides a power law improvement in performance across all architectures and all tasks, while adding trainable parameters is effective only for some (typically more subjectively challenging) tasks. We then compare the downstream performance of finetuned models pretrained on either ImageNet-12k alone vs. additionally pretrained on our galaxy images. We achieve an average relative error rate reduction of 31% across 5 downstream tasks of scientific interest. Our finetuned models are more label-efficient and, unlike their ImageNet-12k-pretrained equivalents, often achieve linear transfer performance equal to that of end-to-end finetuning. We find relatively modest additional downstream benefits from scaling model size, implying that scaling alone is not sufficient to address our domain gap, and suggest that practitioners with qualitatively different images might benefit more from in-domain adaption followed by targeted downstream labelling.
Rare Galaxy Classes Identified In Foundation Model Representations
Dec 05, 2023We identify rare and visually distinctive galaxy populations by searching for structure within the learned representations of pretrained models. We show that these representations arrange galaxies by appearance in patterns beyond those needed to predict the pretraining labels. We design a clustering approach to isolate specific local patterns, revealing groups of galaxies with rare and scientifically-interesting morphologies.
Deep Learning Segmentation of Spiral Arms and Bars
Dec 05, 2023
We present the first deep learning model for segmenting galactic spiral arms and bars. In a blinded assessment by expert astronomers, our predicted spiral arm masks are preferred over both current automated methods (99% of evaluations) and our original volunteer labels (79% of evaluations). Experts rated our spiral arm masks as `mostly good' to `perfect' in 89% of evaluations. Bar lengths trivially derived from our predicted bar masks are in excellent agreement with a dedicated crowdsourcing project. The pixelwise precision of our masks, previously impossible at scale, will underpin new research into how spiral arms and bars evolve.
A New Task: Deriving Semantic Class Targets for the Physical Sciences
Oct 27, 2022
We define deriving semantic class targets as a novel multi-modal task. By doing so, we aim to improve classification schemes in the physical sciences which can be severely abstracted and obfuscating. We address this task for upcoming radio astronomy surveys and present the derived semantic radio galaxy morphology class targets.
Towards Galaxy Foundation Models with Hybrid Contrastive Learning
Jun 23, 2022

New astronomical tasks are often related to earlier tasks for which labels have already been collected. We adapt the contrastive framework BYOL to leverage those labels as a pretraining task while also enforcing augmentation invariance. For large-scale pretraining, we introduce GZ-Evo v0.1, a set of 96.5M volunteer responses for 552k galaxy images plus a further 1.34M comparable unlabelled galaxies. Most of the 206 GZ-Evo answers are unknown for any given galaxy, and so our pretraining task uses a Dirichlet loss that naturally handles unknown answers. GZ-Evo pretraining, with or without hybrid learning, improves on direct training even with plentiful downstream labels (+4% accuracy with 44k labels). Our hybrid pretraining/contrastive method further improves downstream accuracy vs. pretraining or contrastive learning, especially in the low-label transfer regime (+6% accuracy with 750 labels).