 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Dimension Estimation for Radio Galaxy Zoo using Diffusion Models
Nov 14, 2025



In this work, we estimate the intrinsic dimension (iD) of the Radio Galaxy Zoo (RGZ) dataset using a score-based diffusion model. We examine how the iD estimates vary as a function of Bayesian neural network (BNN) energy scores, which measure how similar the radio sources are to the MiraBest subset of the RGZ dataset. We find that out-of-distribution sources exhibit higher iD values, and that the overall iD for RGZ exceeds those typically reported for natural image datasets. Furthermore, we analyse how iD varies across Fanaroff-Riley (FR) morphological classes and as a function of the signal-to-noise ratio (SNR). While no relationship is found between FR I and FR II classes, a weak trend toward higher SNR at lower iD. Future work using the RGZ dataset could make use of the relationship between iD and energy scores to quantitatively study and improve the representations learned by various self-supervised learning algorithms.
* 9 pages, 5 figures, 2 tables, submitted to NeurIPS 2025 ML4PS Workshop
Evaluating Bayesian deep learning for radio galaxy classification
May 28, 2024


The radio astronomy community is rapidly adopting deep learning techniques to deal with the huge data volumes expected from the next generation of radio observatories. Bayesian neural networks (BNNs) provide a principled way to model uncertainty in the predictions made by such deep learning models and will play an important role in extracting well-calibrated uncertainty estimates on their outputs. In this work, we evaluate the performance of different BNNs against the following criteria: predictive performance, uncertainty calibration and distribution-shift detection for the radio galaxy classification problem.
Scaling Laws for Galaxy Images
Apr 03, 2024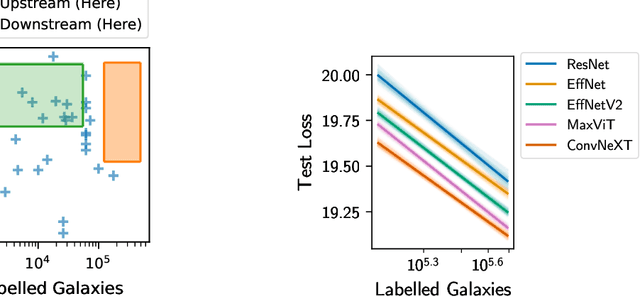
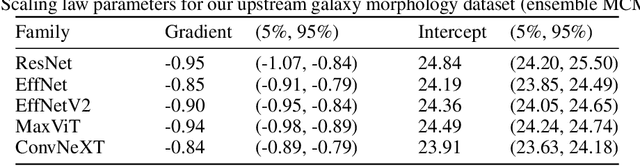
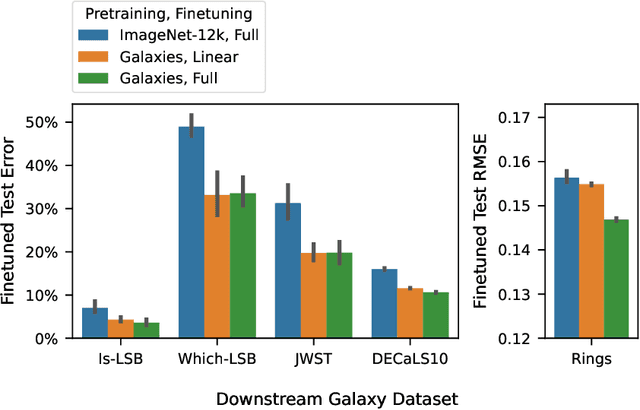
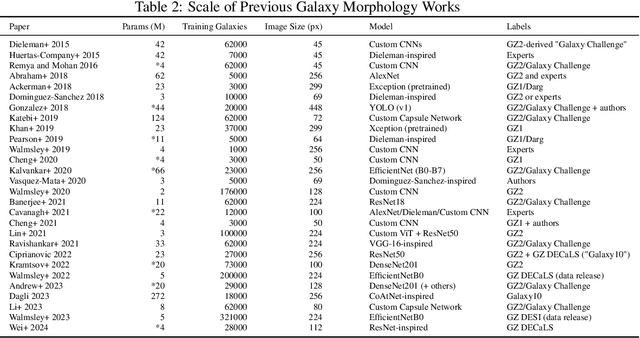
We present the first systematic investigation of supervised scaling laws outside of an ImageNet-like context - on images of galaxies. We use 840k galaxy images and over 100M annotations by Galaxy Zoo volunteers, comparable in scale to Imagenet-1K. We find that adding annotated galaxy images provides a power law improvement in performance across all architectures and all tasks, while adding trainable parameters is effective only for some (typically more subjectively challenging) tasks. We then compare the downstream performance of finetuned models pretrained on either ImageNet-12k alone vs. additionally pretrained on our galaxy images. We achieve an average relative error rate reduction of 31% across 5 downstream tasks of scientific interest. Our finetuned models are more label-efficient and, unlike their ImageNet-12k-pretrained equivalents, often achieve linear transfer performance equal to that of end-to-end finetuning. We find relatively modest additional downstream benefits from scaling model size, implying that scaling alone is not sufficient to address our domain gap, and suggest that practitioners with qualitatively different images might benefit more from in-domain adaption followed by targeted downstream labelling.
Quantifying Uncertainty in Deep Learning Approaches to Radio Galaxy Classification
Jan 24, 2022
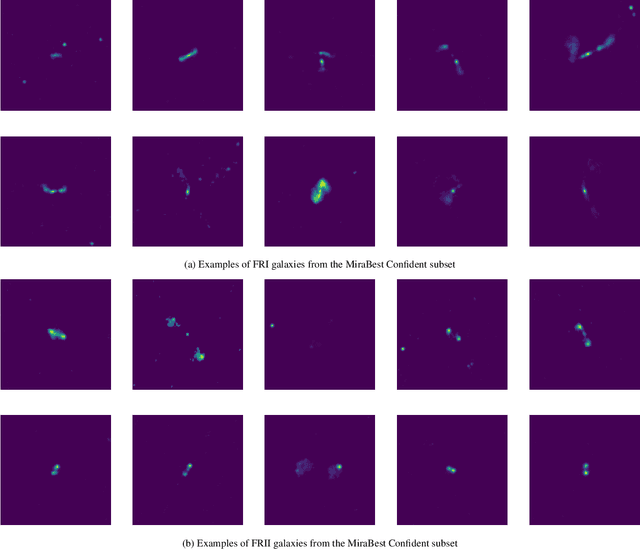
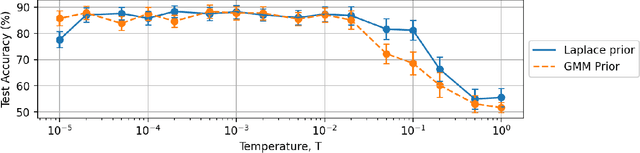
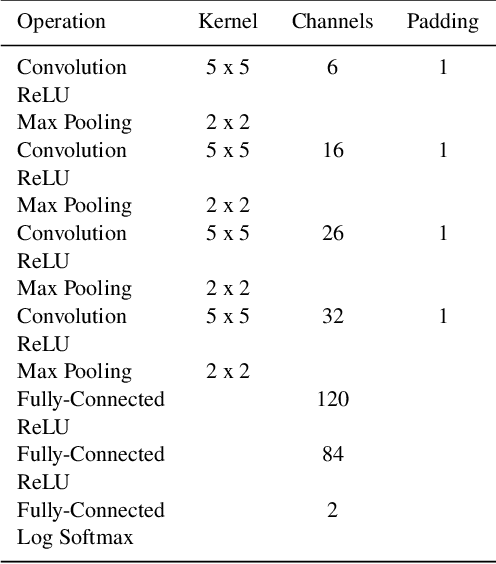
In this work we use variational inference to quantify the degree of uncertainty in deep learning model predictions of radio galaxy classification. We show that the level of model posterior variance for individual test samples is correlated with human uncertainty when labelling radio galaxies. We explore the model performance and uncertainty calibration for different weight priors and suggest that a sparse prior produces more well-calibrated uncertainty estimates. Using the posterior distributions for individual weights, we demonstrate that we can prune 30% of the fully-connected layer weights without significant loss of performance by removing the weights with the lowest signal-to-noise ratio. A larger degree of pruning can be achieved using a Fisher information based ranking, but both pruning methods affect the uncertainty calibration for Fanaroff-Riley type I and type II radio galaxies differently. Like other work in this field, we experience a cold posterior effect, whereby the posterior must be down-weighted to achieve good predictive performance. We examine whether adapting the cost function to accommodate model misspecification can compensate for this effect, but find that it does not make a significant difference. We also examine the effect of principled data augmentation and find that this improves upon the baseline but also does not compensate for the observed effect. We interpret this as the cold posterior effect being due to the overly effective curation of our training sample leading to likelihood misspecification, and raise this as a potential issue for Bayesian deep learning approaches to radio galaxy classification in future.
Weight Pruning and Uncertainty in Radio Galaxy Classification
Nov 29, 2021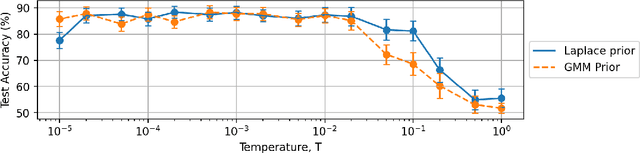
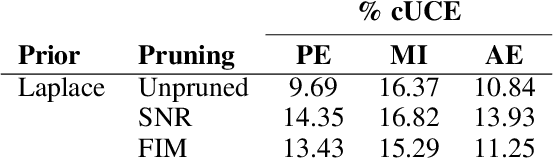

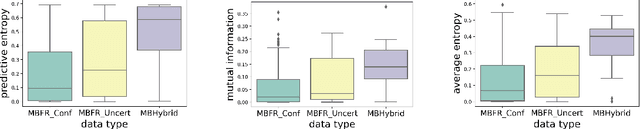
In this work we use variational inference to quantify the degree of epistemic uncertainty in model predictions of radio galaxy classification and show that the level of model posterior variance for individual test samples is correlated with human uncertainty when labelling radio galaxies. We explore the model performance and uncertainty calibration for a variety of different weight priors and suggest that a sparse prior produces more well-calibrated uncertainty estimates. Using the posterior distributions for individual weights, we show that signal-to-noise ratio (SNR) ranking allows pruning of the fully-connected layers to the level of 30% without significant loss of performance, and that this pruning increases the predictive uncertainty in the model. Finally we show that, like other work in this field, we experience a cold posterior effect. We examine whether adapting the cost function in our model to accommodate model misspecification can compensate for this effect, but find that it does not make a significant difference. We also examine the effect of principled data augmentation and find that it improves upon the baseline but does not compensate for the observed effect fully. We interpret this as the cold posterior effect being due to the overly effective curation of our training sample leading to likelihood misspecification, and raise this as a potential issue for Bayesian deep learning approaches to radio galaxy classification in future.