 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Bayesian deep learning for radio galaxy classification
May 28, 2024


The radio astronomy community is rapidly adopting deep learning techniques to deal with the huge data volumes expected from the next generation of radio observatories. Bayesian neural networks (BNNs) provide a principled way to model uncertainty in the predictions made by such deep learning models and will play an important role in extracting well-calibrated uncertainty estimates on their outputs. In this work, we evaluate the performance of different BNNs against the following criteria: predictive performance, uncertainty calibration and distribution-shift detection for the radio galaxy classification problem.
Scaling Laws for Galaxy Images
Apr 03, 2024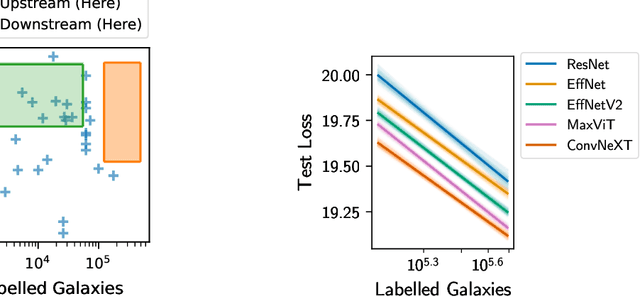
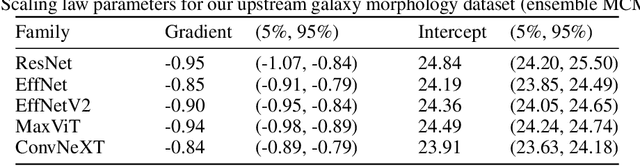
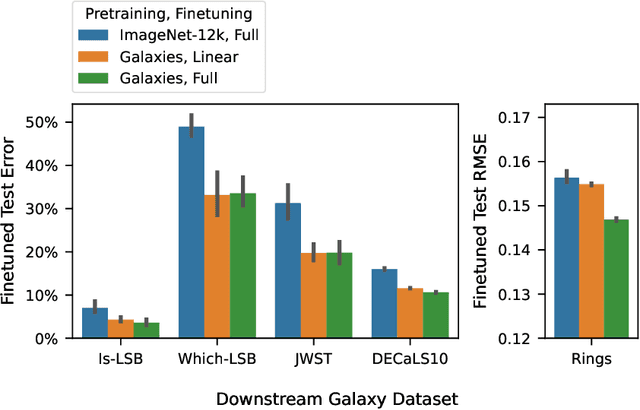
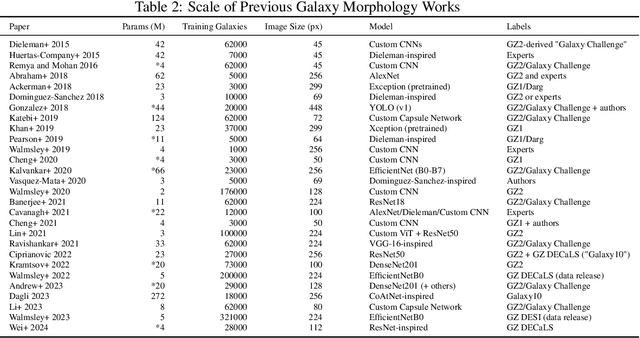
We present the first systematic investigation of supervised scaling laws outside of an ImageNet-like context - on images of galaxies. We use 840k galaxy images and over 100M annotations by Galaxy Zoo volunteers, comparable in scale to Imagenet-1K. We find that adding annotated galaxy images provides a power law improvement in performance across all architectures and all tasks, while adding trainable parameters is effective only for some (typically more subjectively challenging) tasks. We then compare the downstream performance of finetuned models pretrained on either ImageNet-12k alone vs. additionally pretrained on our galaxy images. We achieve an average relative error rate reduction of 31% across 5 downstream tasks of scientific interest. Our finetuned models are more label-efficient and, unlike their ImageNet-12k-pretrained equivalents, often achieve linear transfer performance equal to that of end-to-end finetuning. We find relatively modest additional downstream benefits from scaling model size, implying that scaling alone is not sufficient to address our domain gap, and suggest that practitioners with qualitatively different images might benefit more from in-domain adaption followed by targeted downstream labelling.
Rare Galaxy Classes Identified In Foundation Model Representations
Dec 05, 2023We identify rare and visually distinctive galaxy populations by searching for structure within the learned representations of pretrained models. We show that these representations arrange galaxies by appearance in patterns beyond those needed to predict the pretraining labels. We design a clustering approach to isolate specific local patterns, revealing groups of galaxies with rare and scientifically-interesting morphologies.
Bayesian Imaging for Radio Interferometry with Score-Based Priors
Nov 29, 2023



The inverse imaging task in radio interferometry is a key limiting factor to retrieving Bayesian uncertainties in radio astronomy in a computationally effective manner. We use a score-based prior derived from optical images of galaxies to recover images of protoplanetary disks from the DSHARP survey. We demonstrate that our method produces plausible posterior samples despite the misspecified galaxy prior. We show that our approach produces results which are competitive with existing radio interferometry imaging algorithms.
MiraBest: A Dataset of Morphologically Classified Radio Galaxies for Machine Learning
May 18, 2023



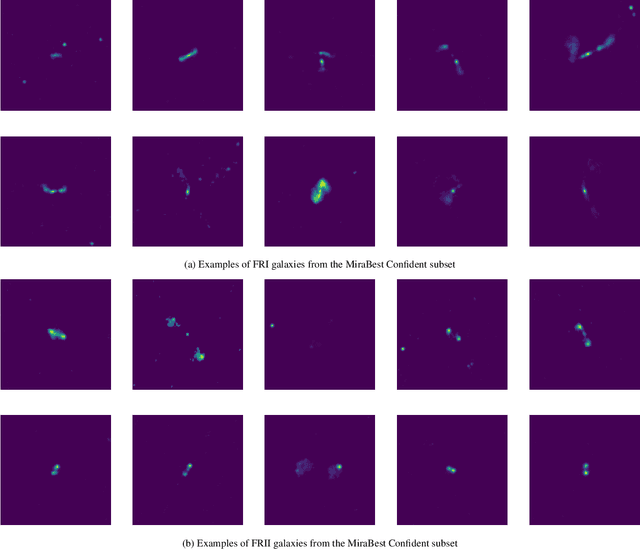
The volume of data from current and future observatories has motivated the increased development and application of automated machine learning methodologies for astronomy. However, less attention has been given to the production of standardised datasets for assessing the performance of different machine learning algorithms within astronomy and astrophysics. Here we describe in detail the MiraBest dataset, a publicly available batched dataset of 1256 radio-loud AGN from NVSS and FIRST, filtered to $0.03 < z < 0.1$, manually labelled by Miraghaei and Best (2017) according to the Fanaroff-Riley morphological classification, created for machine learning applications and compatible for use with standard deep learning libraries. We outline the principles underlying the construction of the dataset, the sample selection and pre-processing methodology, dataset structure and composition, as well as a comparison of MiraBest to other datasets used in the literature. Existing applications that utilise the MiraBest dataset are reviewed, and an extended dataset of 2100 sources is created by cross-matching MiraBest with other catalogues of radio-loud AGN that have been used more widely in the literature for machine learning applications.
A New Task: Deriving Semantic Class Targets for the Physical Sciences
Oct 27, 2022
We define deriving semantic class targets as a novel multi-modal task. By doing so, we aim to improve classification schemes in the physical sciences which can be severely abstracted and obfuscating. We address this task for upcoming radio astronomy surveys and present the derived semantic radio galaxy morphology class targets.
Towards Galaxy Foundation Models with Hybrid Contrastive Learning
Jun 23, 2022

New astronomical tasks are often related to earlier tasks for which labels have already been collected. We adapt the contrastive framework BYOL to leverage those labels as a pretraining task while also enforcing augmentation invariance. For large-scale pretraining, we introduce GZ-Evo v0.1, a set of 96.5M volunteer responses for 552k galaxy images plus a further 1.34M comparable unlabelled galaxies. Most of the 206 GZ-Evo answers are unknown for any given galaxy, and so our pretraining task uses a Dirichlet loss that naturally handles unknown answers. GZ-Evo pretraining, with or without hybrid learning, improves on direct training even with plentiful downstream labels (+4% accuracy with 44k labels). Our hybrid pretraining/contrastive method further improves downstream accuracy vs. pretraining or contrastive learning, especially in the low-label transfer regime (+6% accuracy with 750 labels).
Radio Galaxy Zoo: Using semi-supervised learning to leverage large unlabelled data-sets for radio galaxy classification under data-set shift
Apr 21, 2022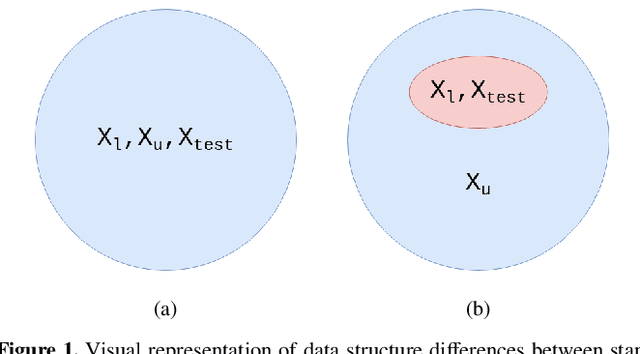



In this work we examine the classification accuracy and robustness of a state-of-the-art semi-supervised learning (SSL) algorithm applied to the morphological classification of radio galaxies. We test if SSL with fewer labels can achieve test accuracies comparable to the supervised state-of-the-art and whether this holds when incorporating previously unseen data. We find that for the radio galaxy classification problem considered, SSL provides additional regularisation and outperforms the baseline test accuracy. However, in contrast to model performance metrics reported on computer science benchmarking data-sets, we find that improvement is limited to a narrow range of label volumes, with performance falling off rapidly at low label volumes. Additionally, we show that SSL does not improve model calibration, regardless of whether classification is improved. Moreover, we find that when different underlying catalogues drawn from the same radio survey are used to provide the labelled and unlabelled data-sets required for SSL, a significant drop in classification performance is observered, highlighting the difficulty of applying SSL techniques under dataset shift. We show that a class-imbalanced unlabelled data pool negatively affects performance through prior probability shift, which we suggest may explain this performance drop, and that using the Frechet Distance between labelled and unlabelled data-sets as a measure of data-set shift can provide a prediction of model performance, but that for typical radio galaxy data-sets with labelled sample volumes of O(1000), the sample variance associated with this technique is high and the technique is in general not sufficiently robust to replace a train-test cycle.
Quantifying Uncertainty in Deep Learning Approaches to Radio Galaxy Classification
Jan 24, 2022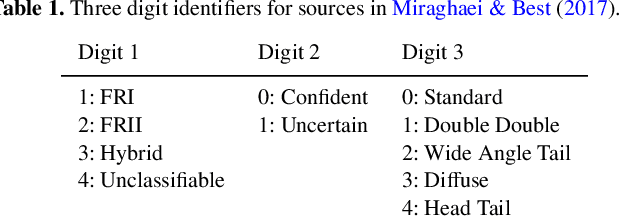
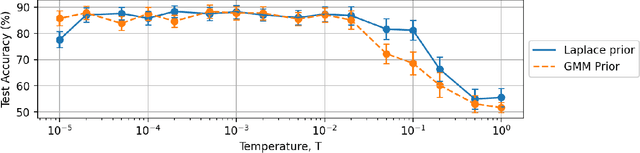
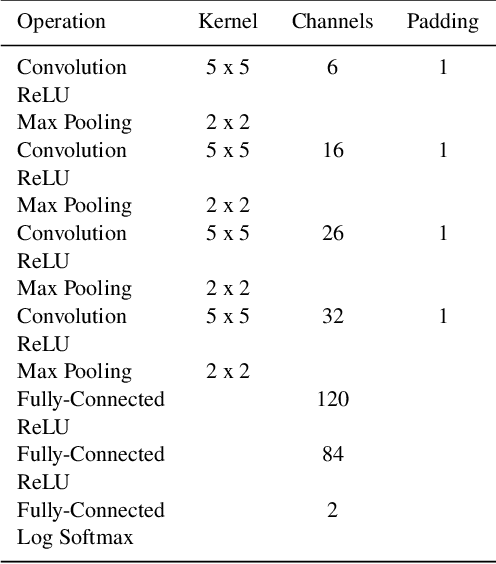
In this work we use variational inference to quantify the degree of uncertainty in deep learning model predictions of radio galaxy classification. We show that the level of model posterior variance for individual test samples is correlated with human uncertainty when labelling radio galaxies. We explore the model performance and uncertainty calibration for different weight priors and suggest that a sparse prior produces more well-calibrated uncertainty estimates. Using the posterior distributions for individual weights, we demonstrate that we can prune 30% of the fully-connected layer weights without significant loss of performance by removing the weights with the lowest signal-to-noise ratio. A larger degree of pruning can be achieved using a Fisher information based ranking, but both pruning methods affect the uncertainty calibration for Fanaroff-Riley type I and type II radio galaxies differently. Like other work in this field, we experience a cold posterior effect, whereby the posterior must be down-weighted to achieve good predictive performance. We examine whether adapting the cost function to accommodate model misspecification can compensate for this effect, but find that it does not make a significant difference. We also examine the effect of principled data augmentation and find that this improves upon the baseline but also does not compensate for the observed effect. We interpret this as the cold posterior effect being due to the overly effective curation of our training sample leading to likelihood misspecification, and raise this as a potential issue for Bayesian deep learning approaches to radio galaxy classification in future.
Can semi-supervised learning reduce the amount of manual labelling required for effective radio galaxy morphology classification?
Dec 01, 2021
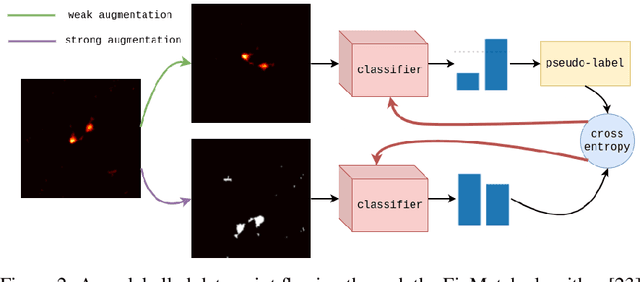
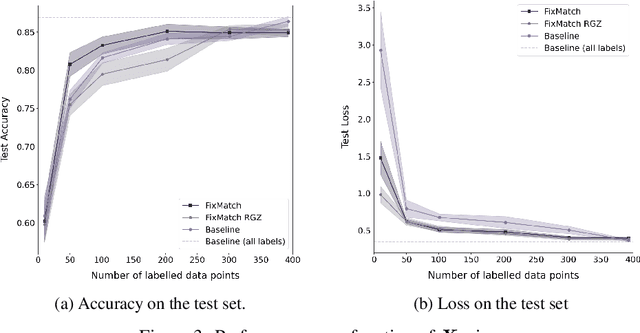
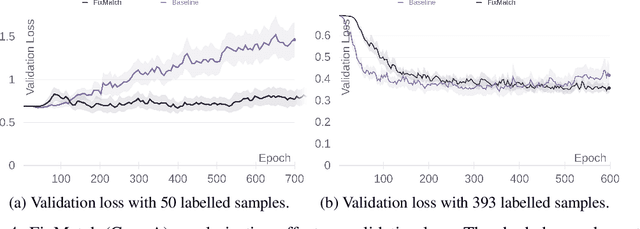
In this work, we examine the robustness of state-of-the-art semi-supervised learning (SSL) algorithms when applied to morphological classification in modern radio astronomy. We test whether SSL can achieve performance comparable to the current supervised state of the art when using many fewer labelled data points and if these results generalise to using truly unlabelled data. We find that although SSL provides additional regularisation, its performance degrades rapidly when using very few labels, and that using truly unlabelled data leads to a significant drop in performance.