 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast Generative Framework for High-dimensional Posterior Sampling: Application to CMB Delensing
Mar 04, 2026We introduce a deep generative framework for high-dimensional Bayesian inference that enables efficient posterior sampling. As telescopes and simulations rapidly expand the volume and resolution of astrophysical data, fast simulation-based inference methods are increasingly needed to extract scientific insights. While diffusion-based approaches offer high-quality generative capabilities, they are hindered by slow sampling speeds. Our method performs posterior sampling an order of magnitude faster than a diffusion baseline. Applied to the problem of CMB delensing, it successfully recovers the unlensed CMB power spectrum from simulated observations. The model also remains robust to shifts in cosmological parameters, demonstrating its potential for out-of-distribution generalization and application to observational cosmological data.
Opportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
Blind Strong Gravitational Lensing Inversion: Joint Inference of Source and Lens Mass with Score-Based Models
Nov 06, 2025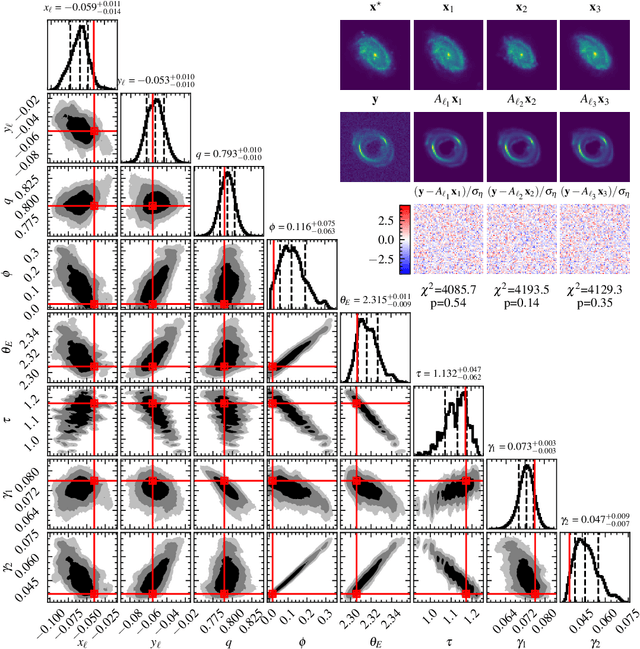
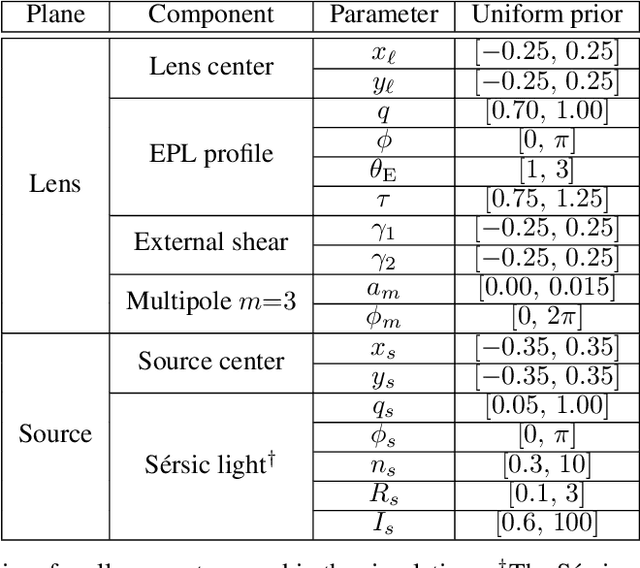
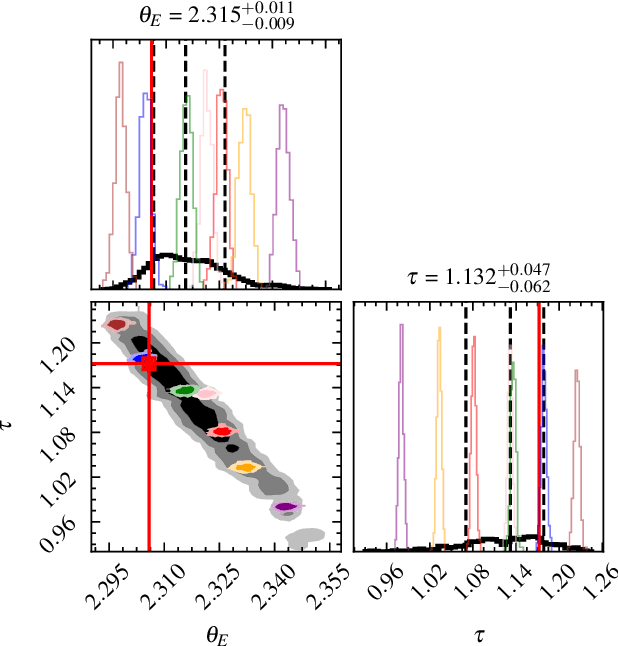

Score-based models can serve as expressive, data-driven priors for scientific inverse problems. In strong gravitational lensing, they enable posterior inference of a background galaxy from its distorted, multiply-imaged observation. Previous work, however, assumes that the lens mass distribution (and thus the forward operator) is known. We relax this assumption by jointly inferring the source and a parametric lens-mass profile, using a sampler based on GibbsDDRM but operating in continuous time. The resulting reconstructions yield residuals consistent with the observational noise, and the marginal posteriors of the lens parameters recover true values without systematic bias. To our knowledge, this is the first successful demonstration of joint source-and-lens inference with a score-based prior.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
IRIS: A Bayesian Approach for Image Reconstruction in Radio Interferometry with expressive Score-Based priors
Jan 05, 2025



Inferring sky surface brightness distributions from noisy interferometric data in a principled statistical framework has been a key challenge in radio astronomy. In this work, we introduce Imaging for Radio Interferometry with Score-based models (IRIS). We use score-based models trained on optical images of galaxies as an expressive prior in combination with a Gaussian likelihood in the uv-space to infer images of protoplanetary disks from visibility data of the DSHARP survey conducted by ALMA. We demonstrate the advantages of this framework compared with traditional radio interferometry imaging algorithms, showing that it produces plausible posterior samples despite the use of a misspecified galaxy prior. Through coverage testing on simulations, we empirically evaluate the accuracy of this approach to generate calibrated posterior samples.
Tackling the Problem of Distributional Shifts: Correcting Misspecified, High-Dimensional Data-Driven Priors for Inverse Problems
Jul 24, 2024



Bayesian inference for inverse problems hinges critically on the choice of priors. In the absence of specific prior information, population-level distributions can serve as effective priors for parameters of interest. With the advent of machine learning, the use of data-driven population-level distributions (encoded, e.g., in a trained deep neural network) as priors is emerging as an appealing alternative to simple parametric priors in a variety of inverse problems. However, in many astrophysical applications, it is often difficult or even impossible to acquire independent and identically distributed samples from the underlying data-generating process of interest to train these models. In these cases, corrupted data or a surrogate, e.g. a simulator, is often used to produce training samples, meaning that there is a risk of obtaining misspecified priors. This, in turn, can bias the inferred posteriors in ways that are difficult to quantify, which limits the potential applicability of these models in real-world scenarios. In this work, we propose addressing this issue by iteratively updating the population-level distributions by retraining the model with posterior samples from different sets of observations and showcase the potential of this method on the problem of background image reconstruction in strong gravitational lensing when score-based models are used as data-driven priors. We show that starting from a misspecified prior distribution, the updated distribution becomes progressively closer to the underlying population-level distribution, and the resulting posterior samples exhibit reduced bias after several updates.
PQMass: Probabilistic Assessment of the Quality of Generative Models using Probability Mass Estimation
Feb 06, 2024



We propose a comprehensive sample-based method for assessing the quality of generative models. The proposed approach enables the estimation of the probability that two sets of samples are drawn from the same distribution, providing a statistically rigorous method for assessing the performance of a single generative model or the comparison of multiple competing models trained on the same dataset. This comparison can be conducted by dividing the space into non-overlapping regions and comparing the number of data samples in each region. The method only requires samples from the generative model and the test data. It is capable of functioning directly on high-dimensional data, obviating the need for dimensionality reduction. Significantly, the proposed method does not depend on assumptions regarding the density of the true distribution, and it does not rely on training or fitting any auxiliary models. Instead, it focuses on approximating the integral of the density (probability mass) across various sub-regions within the data space.
Improving Gradient-guided Nested Sampling for Posterior Inference
Dec 06, 2023



We present a performant, general-purpose gradient-guided nested sampling algorithm, ${\tt GGNS}$, combining the state of the art in differentiable programming, Hamiltonian slice sampling, clustering, mode separation, dynamic nested sampling, and parallelization. This unique combination allows ${\tt GGNS}$ to scale well with dimensionality and perform competitively on a variety of synthetic and real-world problems. We also show the potential of combining nested sampling with generative flow networks to obtain large amounts of high-quality samples from the posterior distribution. This combination leads to faster mode discovery and more accurate estimates of the partition function.
Bayesian Imaging for Radio Interferometry with Score-Based Priors
Nov 29, 2023



The inverse imaging task in radio interferometry is a key limiting factor to retrieving Bayesian uncertainties in radio astronomy in a computationally effective manner. We use a score-based prior derived from optical images of galaxies to recover images of protoplanetary disks from the DSHARP survey. We demonstrate that our method produces plausible posterior samples despite the misspecified galaxy prior. We show that our approach produces results which are competitive with existing radio interferometry imaging algorithms.
Echoes in the Noise: Posterior Samples of Faint Galaxy Surface Brightness Profiles with Score-Based Likelihoods and Priors
Nov 29, 2023



Examining the detailed structure of galaxy populations provides valuable insights into their formation and evolution mechanisms. Significant barriers to such analysis are the non-trivial noise properties of real astronomical images and the point spread function (PSF) which blurs structure. Here we present a framework which combines recent advances in score-based likelihood characterization and diffusion model priors to perform a Bayesian analysis of image deconvolution. The method, when applied to minimally processed \emph{Hubble Space Telescope} (\emph{HST}) data, recovers structures which have otherwise only become visible in next-generation \emph{James Webb Space Telescope} (\emph{JWST}) imaging.