 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgejaxsgp4: GPU-accelerated mega-constellation propagation with batch parallelism
Mar 29, 2026As the population of anthropogenic space objects transitions from sparse clusters to mega-constellations exceeding 100,000 satellites, traditional orbital propagation techniques face a critical bottleneck. Standard CPU-bound implementations of the Simplified General Perturbations 4 (SGP4) algorithm are less well suited to handle the requisite scale of collision avoidance and Space Situational Awareness (SSA) tasks. This paper introduces \texttt{jaxsgp4}, an open-source high-performance reimplementation of SGP4 utilising the \texttt{JAX} library. \texttt{JAX} has gained traction in the landscape of computational research, offering an easy mechanism for Just-In-Time (JIT) compilation, automatic vectorisation and automatic optimisation of code for CPU, GPU and TPU hardware modalities. By refactoring the algorithm into a pure functional paradigm, we leverage these transformations to execute massively parallel propagations on modern GPUs. We demonstrate that \texttt{jaxsgp4} can propagate the entire Starlink constellation (9,341 satellites) each to 1,000 future time steps in under 4 ms on a single A100 GPU, representing a speedup of $1500\times$ over traditional C++ baselines. Furthermore, we argue that the use of 32-bit precision for SGP4 propagation tasks offers a principled trade-off, sacrificing negligible precision loss for a substantial gain in throughput on hardware accelerators.
Automatic Laplace Collapsed Sampling: Scalable Marginalisation of Latent Parameters via Automatic Differentiation
Mar 27, 2026We present Automatic Laplace Collapsed Sampling (ALCS), a general framework for marginalising latent parameters in Bayesian models using automatic differentiation, which we combine with nested sampling to explore the hyperparameter space in a robust and efficient manner. At each nested sampling likelihood evaluation, ALCS collapses the high-dimensional latent variables $z$ to a scalar contribution via maximum a posteriori (MAP) optimisation and a Laplace approximation, both computed using autodiff. This reduces the effective dimension from $d_θ+ d_z$ to just $d_θ$, making Bayesian evidence computation tractable for high-dimensional settings without hand-derived gradients or Hessians, and with minimal model-specific engineering. The MAP optimisation and Hessian evaluation are parallelised across live points on GPU-hardware, making the method practical at scale. We also show that automatic differentiation enables local approximations beyond Laplace to parametric families such as the Student-$t$, which improves evidence estimates for heavy-tailed latents. We validate ALCS on a suite of benchmarks spanning hierarchical, time-series, and discrete-likelihood models and establish where the Gaussian approximation holds. This enables a post-hoc ESS diagnostic that localises failures across hyperparameter space without expensive joint sampling.
Nested Slice Sampling: Vectorized Nested Sampling for GPU-Accelerated Inference
Jan 30, 2026Model comparison and calibrated uncertainty quantification often require integrating over parameters, but scalable inference can be challenging for complex, multimodal targets. Nested Sampling is a robust alternative to standard MCMC, yet its typically sequential structure and hard constraints make efficient accelerator implementations difficult. This paper introduces Nested Slice Sampling (NSS), a GPU-friendly, vectorized formulation of Nested Sampling that uses Hit-and-Run Slice Sampling for constrained updates. A tuning analysis yields a simple near-optimal rule for setting the slice width, improving high-dimensional behavior and making per-step compute more predictable for parallel execution. Experiments on challenging synthetic targets, high dimensional Bayesian inference, and Gaussian process hyperparameter marginalization show that NSS maintains accurate evidence estimates and high-quality posterior samples, and is particularly robust on difficult multimodal problems where current state-of-the-art methods such as tempered SMC baselines can struggle. An open-source implementation is released to facilitate adoption and reproducibility.
Resonances in reflective Hamiltonian Monte Carlo
Apr 16, 2025



In high dimensions, reflective Hamiltonian Monte Carlo with inexact reflections exhibits slow mixing when the particle ensemble is initialised from a Dirac delta distribution and the uniform distribution is targeted. By quantifying the instantaneous non-uniformity of the distribution with the Sinkhorn divergence, we elucidate the principal mechanisms underlying the mixing problems. In spheres and cubes, we show that the collective motion transitions between fluid-like and discretisation-dominated behaviour, with the critical step size scaling as a power law in the dimension. In both regimes, the particles can spontaneously unmix, leading to resonances in the particle density and the aforementioned problems. Additionally, low-dimensional toy models of the dynamics are constructed which reproduce the dominant features of the high-dimensional problem. Finally, the dynamics is contrasted with the exact Hamiltonian particle flow and tuning practices are discussed.
Cosmological Parameter Estimation with Sequential Linear Simulation-based Inference
Jan 07, 2025



We develop the framework of Linear Simulation-based Inference (LSBI), an application of simulation-based inference where the likelihood is approximated by a Gaussian linear function of its parameters. We obtain analytical expressions for the posterior distributions of hyper-parameters of the linear likelihood in terms of samples drawn from a simulator, for both uniform and conjugate priors. This method is applied sequentially to several toy-models and tested on emulated datasets for the Cosmic Microwave Background temperature power spectrum. We find that convergence is achieved after four or five rounds of $\mathcal{O}(10^4)$ simulations, which is competitive with state-of-the-art neural density estimation methods. Therefore, we demonstrate that it is possible to obtain significant information gain and generate posteriors that agree with the underlying parameters while maintaining explainability and intellectual oversight.
A comparison of Bayesian sampling algorithms for high-dimensional particle physics and cosmology applications
Sep 27, 2024For several decades now, Bayesian inference techniques have been applied to theories of particle physics, cosmology and astrophysics to obtain the probability density functions of their free parameters. In this study, we review and compare a wide range of Markov Chain Monte Carlo (MCMC) and nested sampling techniques to determine their relative efficacy on functions that resemble those encountered most frequently in the particle astrophysics literature. Our first series of tests explores a series of high-dimensional analytic test functions that exemplify particular challenges, for example highly multimodal posteriors or posteriors with curving degeneracies. We then investigate two real physics examples, the first being a global fit of the $\Lambda$CDM model using cosmic microwave background data from the Planck experiment, and the second being a global fit of the Minimal Supersymmetric Standard Model using a wide variety of collider and astrophysics data. We show that several examples widely thought to be most easily solved using nested sampling approaches can in fact be more efficiently solved using modern MCMC algorithms, but the details of the implementation matter. Furthermore, we also provide a series of useful insights for practitioners of particle astrophysics and cosmology.
Improving Gradient-guided Nested Sampling for Posterior Inference
Dec 06, 2023



We present a performant, general-purpose gradient-guided nested sampling algorithm, ${\tt GGNS}$, combining the state of the art in differentiable programming, Hamiltonian slice sampling, clustering, mode separation, dynamic nested sampling, and parallelization. This unique combination allows ${\tt GGNS}$ to scale well with dimensionality and perform competitively on a variety of synthetic and real-world problems. We also show the potential of combining nested sampling with generative flow networks to obtain large amounts of high-quality samples from the posterior distribution. This combination leads to faster mode discovery and more accurate estimates of the partition function.
Kernel-, mean- and noise-marginalised Gaussian processes for exoplanet transits and $H_0$ inference
Nov 07, 2023Using a fully Bayesian approach, Gaussian Process regression is extended to include marginalisation over the kernel choice and kernel hyperparameters. In addition, Bayesian model comparison via the evidence enables direct kernel comparison. The calculation of the joint posterior was implemented with a transdimensional sampler which simultaneously samples over the discrete kernel choice and their hyperparameters by embedding these in a higher-dimensional space, from which samples are taken using nested sampling. This method was explored on synthetic data from exoplanet transit light curve simulations. The true kernel was recovered in the low noise region while no kernel was preferred for larger noise. Furthermore, inference of the physical exoplanet hyperparameters was conducted. In the high noise region, either the bias in the posteriors was removed, the posteriors were broadened or the accuracy of the inference was increased. In addition, the uncertainty in mean function predictive distribution increased due to the uncertainty in the kernel choice. Subsequently, the method was extended to marginalisation over mean functions and noise models and applied to the inference of the present-day Hubble parameter, $H_0$, from real measurements of the Hubble parameter as a function of redshift, derived from the cosmologically model-independent cosmic chronometer and {\Lambda}CDM-dependent baryon acoustic oscillation observations. The inferred $H_0$ values from the cosmic chronometers, baryon acoustic oscillations and combined datasets are $H_0$ = 66$\pm$6 km/s/Mpc, $H_0$ = 67$\pm$10 km/s/Mpc and $H_0$ = 69$\pm$6 km/s/Mpc, respectively. The kernel posterior of the cosmic chronometers dataset prefers a non-stationary linear kernel. Finally, the datasets are shown to be not in tension with ln(R)=12.17$\pm$0.02.
Piecewise Normalizing Flows
May 04, 2023Normalizing flows are an established approach for modelling complex probability densities through invertible transformations from a base distribution. However, the accuracy with which the target distribution can be captured by the normalizing flow is strongly influenced by the topology of the base distribution. A mismatch between the topology of the target and the base can result in a poor performance, as is the case for multi-modal problems. A number of different works have attempted to modify the topology of the base distribution to better match the target, either through the use of Gaussian Mixture Models [Izmailov et al., 2020, Ardizzone et al., 2020, Hagemann and Neumayer, 2021] or learned accept/reject sampling [Stimper et al., 2022]. We introduce piecewise normalizing flows which divide the target distribution into clusters, with topologies that better match the standard normal base distribution, and train a series of flows to model complex multi-modal targets. The piecewise nature of the flows can be exploited to significantly reduce the computational cost of training through parallelization. We demonstrate the performance of the piecewise flows using standard benchmarks and compare the accuracy of the flows to the approach taken in Stimper et al., 2022 for modelling multi-modal distributions.
Split personalities in Bayesian Neural Networks: the case for full marginalisation
May 23, 2022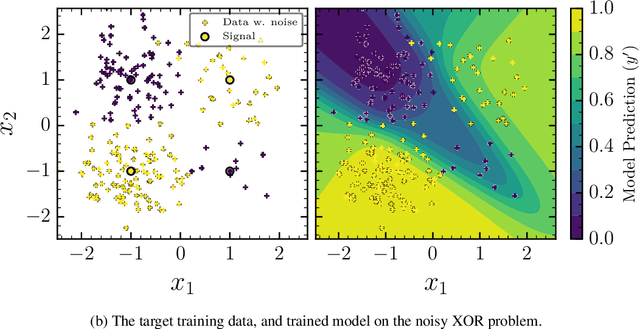
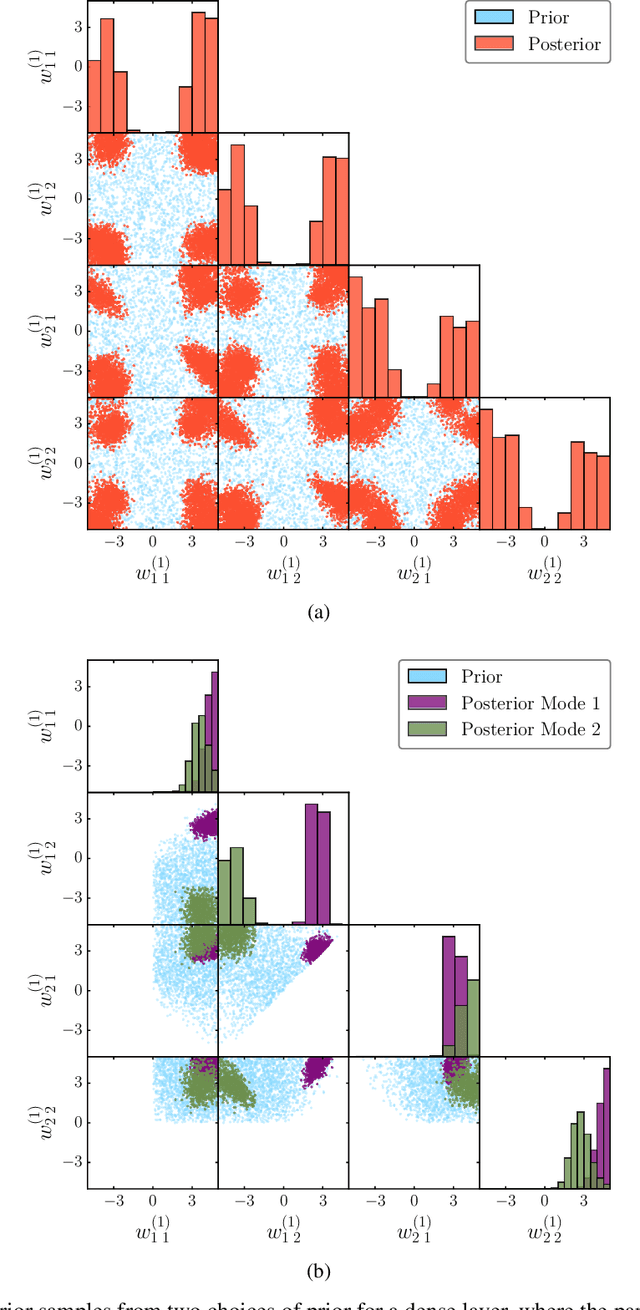
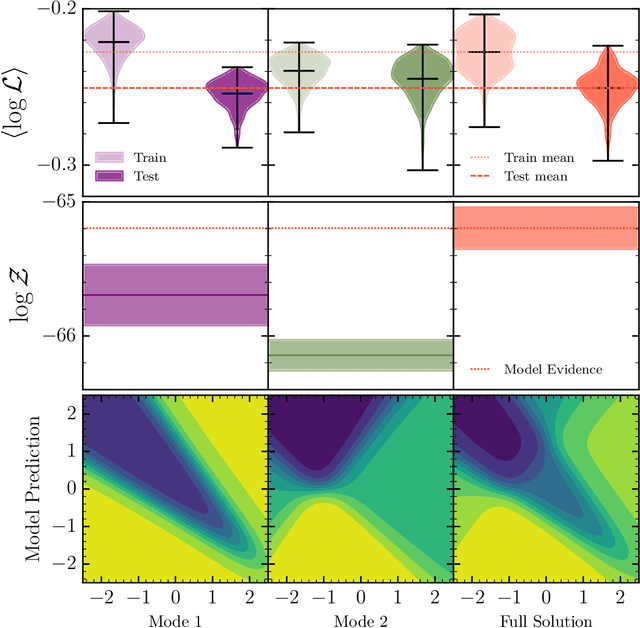
The true posterior distribution of a Bayesian neural network is massively multimodal. Whilst most of these modes are functionally equivalent, we demonstrate that there remains a level of real multimodality that manifests in even the simplest neural network setups. It is only by fully marginalising over all posterior modes, using appropriate Bayesian sampling tools, that we can capture the split personalities of the network. The ability of a network trained in this manner to reason between multiple candidate solutions dramatically improves the generalisability of the model, a feature we contend is not consistently captured by alternative approaches to the training of Bayesian neural networks. We provide a concise minimal example of this, which can provide lessons and a future path forward for correctly utilising the explainability and interpretability of Bayesian neural networks.