 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompromise-free Bayesian neural networks
Apr 28, 2020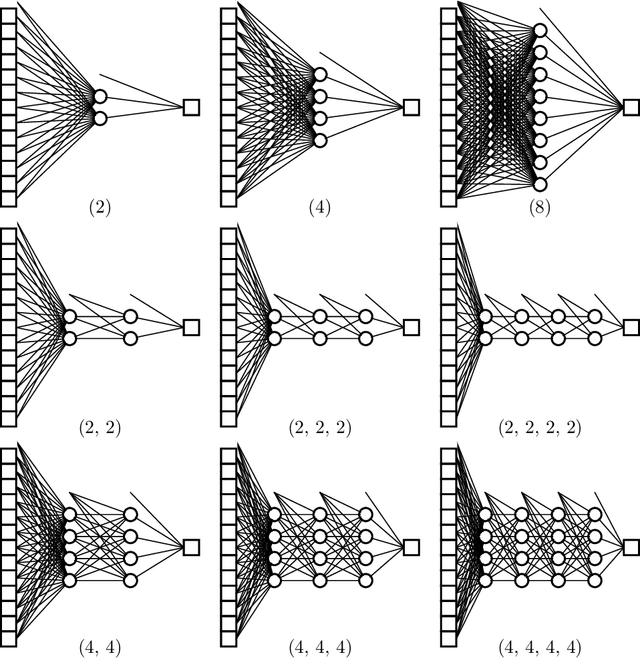
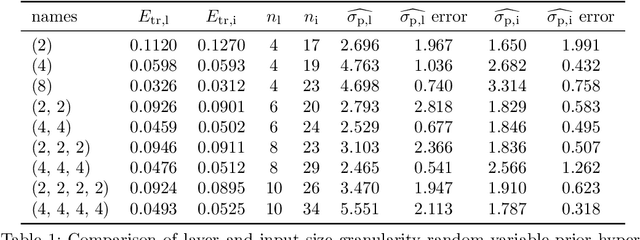
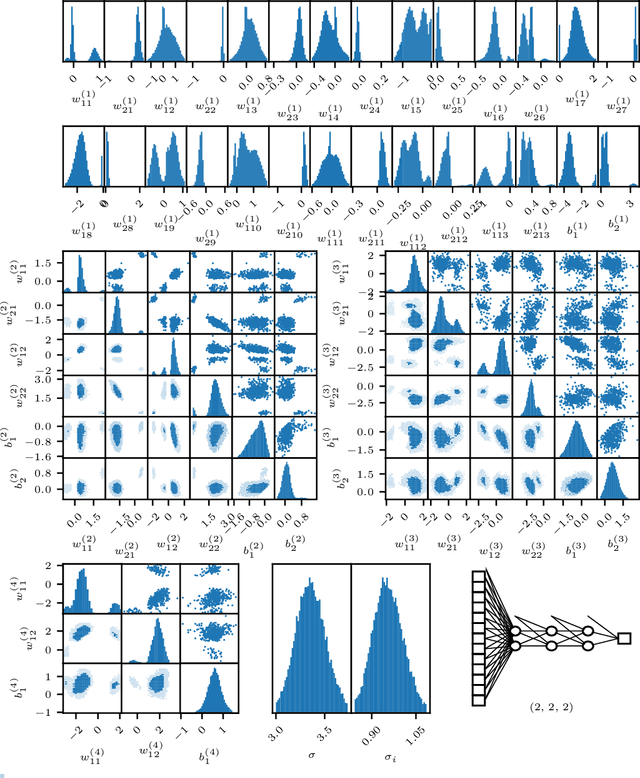
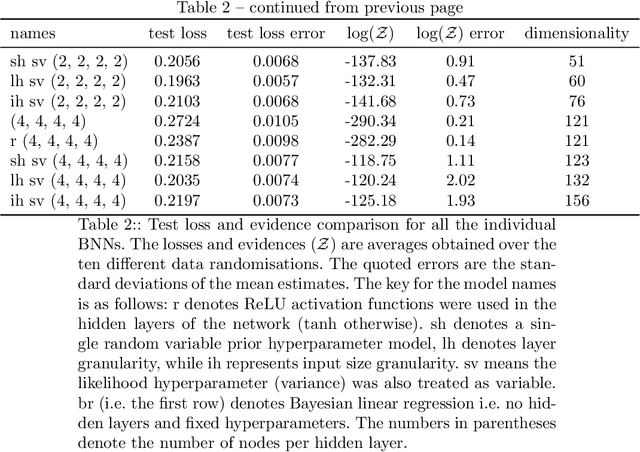
We conduct a thorough analysis of the relationship between the out-of-sample performance and the Bayesian evidence of Bayesian neural networks (BNNs) using the Boston housing dataset, as well as looking at the performance of ensembles of BNNs. We numerically sample without compromise the full network posterior and obtain estimates of the Bayesian evidence using the publicly available version of the nested sampling algorithm PolyChord$^1$ (Handley et al., 2015a,b), considering network models with up to 156 trainable parameters$^2$ (Javid and Handley, 2020). The networks have between zero and four hidden layers, either $\tanh$ or ReLU activation functions, and with and without hierarchical priors (MacKay, 1992c; Neal, 2012). The ensembles of BNNs are obtained by determining the posterior distribution over networks, from the posterior samples of individual BNNs re-weighted by the associated Bayesian evidence values. From the out-of-sample performance of the BNNs with ReLU activations, it is clear that they outperform BNNs of the same architecture with tanh activations, and evidence values corresponding to the former reflect this in their relatively high values. Looking at the models with hierarchical priors, there is a good correlation between out-of-sample performance and evidence, as was found in MacKay (1992c), as well as a remarkable symmetry between the evidence versus model size and out-of-sample performance versus model size planes. The BNNs predictively outperform the equivalent neural networks trained with a traditional backpropagation approach, and Bayesian marginalising/ensembling over architectures acts to further improve performance. 1: https://github.com/PolyChord/PolyChordLite 2: https://github.com/SuperKam91/bnn