 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Strong Gravitational Lensing Inversion: Joint Inference of Source and Lens Mass with Score-Based Models
Nov 06, 2025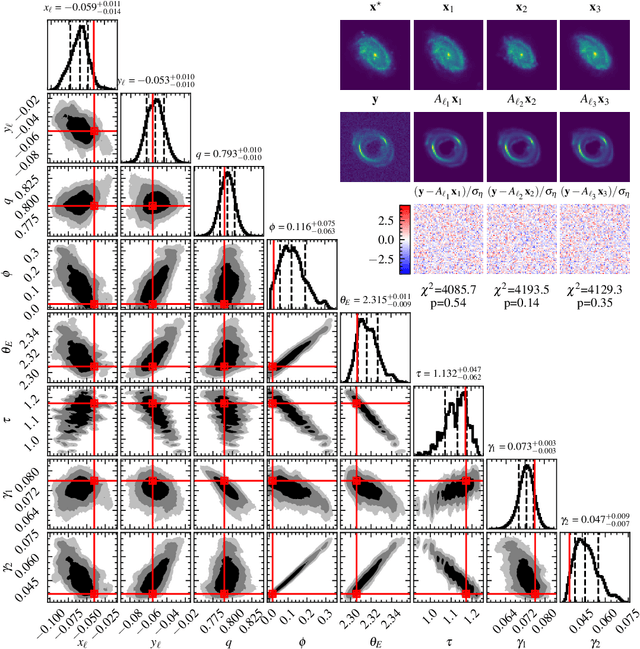
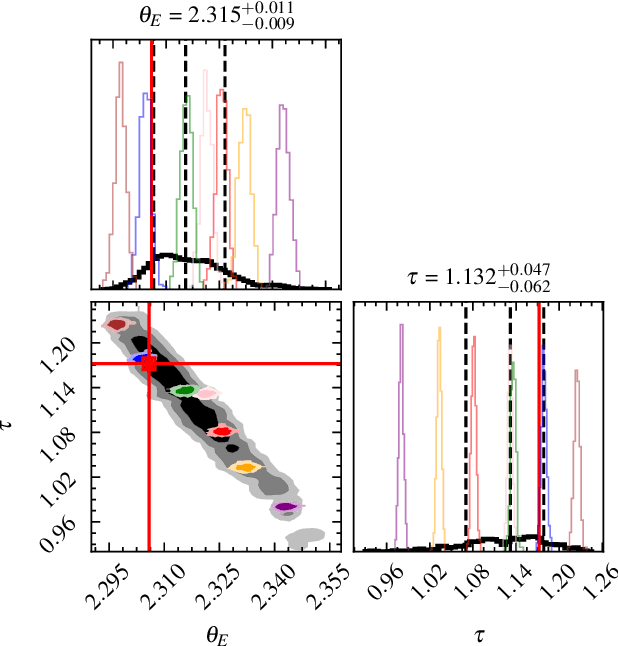

Score-based models can serve as expressive, data-driven priors for scientific inverse problems. In strong gravitational lensing, they enable posterior inference of a background galaxy from its distorted, multiply-imaged observation. Previous work, however, assumes that the lens mass distribution (and thus the forward operator) is known. We relax this assumption by jointly inferring the source and a parametric lens-mass profile, using a sampler based on GibbsDDRM but operating in continuous time. The resulting reconstructions yield residuals consistent with the observational noise, and the marginal posteriors of the lens parameters recover true values without systematic bias. To our knowledge, this is the first successful demonstration of joint source-and-lens inference with a score-based prior.
Tackling the Problem of Distributional Shifts: Correcting Misspecified, High-Dimensional Data-Driven Priors for Inverse Problems
Jul 24, 2024



Bayesian inference for inverse problems hinges critically on the choice of priors. In the absence of specific prior information, population-level distributions can serve as effective priors for parameters of interest. With the advent of machine learning, the use of data-driven population-level distributions (encoded, e.g., in a trained deep neural network) as priors is emerging as an appealing alternative to simple parametric priors in a variety of inverse problems. However, in many astrophysical applications, it is often difficult or even impossible to acquire independent and identically distributed samples from the underlying data-generating process of interest to train these models. In these cases, corrupted data or a surrogate, e.g. a simulator, is often used to produce training samples, meaning that there is a risk of obtaining misspecified priors. This, in turn, can bias the inferred posteriors in ways that are difficult to quantify, which limits the potential applicability of these models in real-world scenarios. In this work, we propose addressing this issue by iteratively updating the population-level distributions by retraining the model with posterior samples from different sets of observations and showcase the potential of this method on the problem of background image reconstruction in strong gravitational lensing when score-based models are used as data-driven priors. We show that starting from a misspecified prior distribution, the updated distribution becomes progressively closer to the underlying population-level distribution, and the resulting posterior samples exhibit reduced bias after several updates.
Echoes in the Noise: Posterior Samples of Faint Galaxy Surface Brightness Profiles with Score-Based Likelihoods and Priors
Nov 29, 2023



Examining the detailed structure of galaxy populations provides valuable insights into their formation and evolution mechanisms. Significant barriers to such analysis are the non-trivial noise properties of real astronomical images and the point spread function (PSF) which blurs structure. Here we present a framework which combines recent advances in score-based likelihood characterization and diffusion model priors to perform a Bayesian analysis of image deconvolution. The method, when applied to minimally processed \emph{Hubble Space Telescope} (\emph{HST}) data, recovers structures which have otherwise only become visible in next-generation \emph{James Webb Space Telescope} (\emph{JWST}) imaging.
Realistic galaxy image simulation via score-based generative models
Nov 02, 2021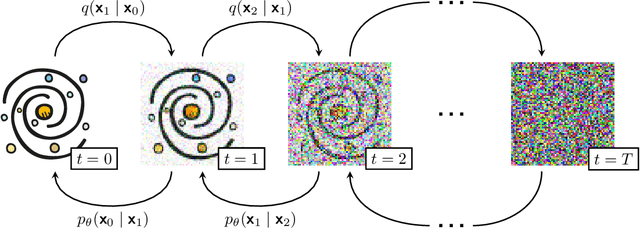

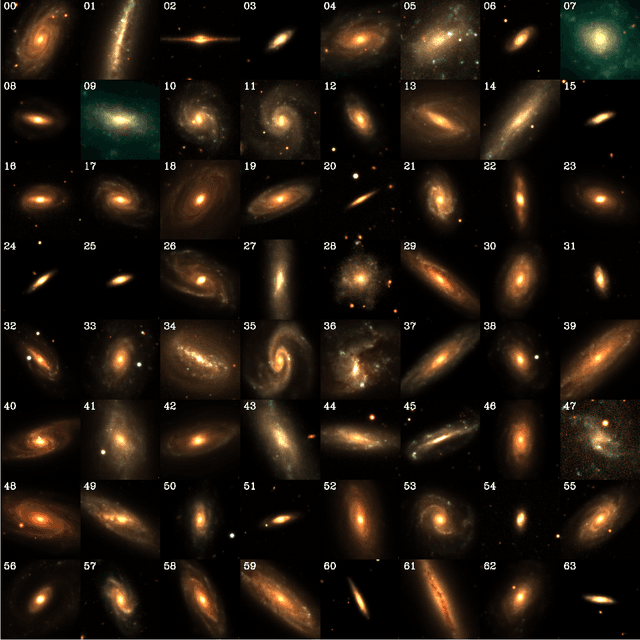

We show that a Denoising Diffusion Probabalistic Model (DDPM), a class of score-based generative model, can be used to produce realistic yet fake images that mimic observations of galaxies. Our method is tested with Dark Energy Spectroscopic Instrument grz imaging of galaxies from the Photometry and Rotation curve OBservations from Extragalactic Surveys (PROBES) sample and galaxies selected from the Sloan Digital Sky Survey. Subjectively, the generated galaxies are highly realistic when compared with samples from the real dataset. We quantify the similarity by borrowing from the deep generative learning literature, using the `Fr\'echet Inception Distance' to test for subjective and morphological similarity. We also introduce the `Synthetic Galaxy Distance' metric to compare the emergent physical properties (such as total magnitude, colour and half light radius) of a ground truth parent and synthesised child dataset. We argue that the DDPM approach produces sharper and more realistic images than other generative methods such as Adversarial Networks (with the downside of more costly inference), and could be used to produce large samples of synthetic observations tailored to a specific imaging survey. We demonstrate two potential uses of the DDPM: (1) accurate in-painting of occluded data, such as satellite trails, and (2) domain transfer, where new input images can be processed to mimic the properties of the DDPM training set. Here we `DESI-fy' cartoon images as a proof of concept for domain transfer. Finally, we suggest potential applications for score-based approaches that could motivate further research on this topic within the astronomical community.
Pix2Prof: fast extraction of sequential information from galaxy imagery via deep learning
Oct 01, 2020
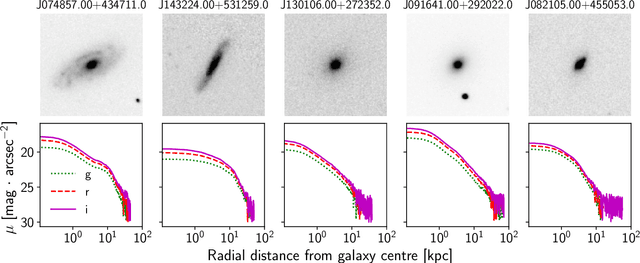
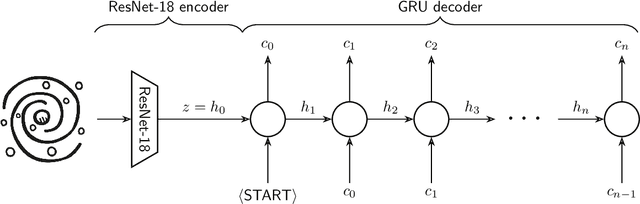
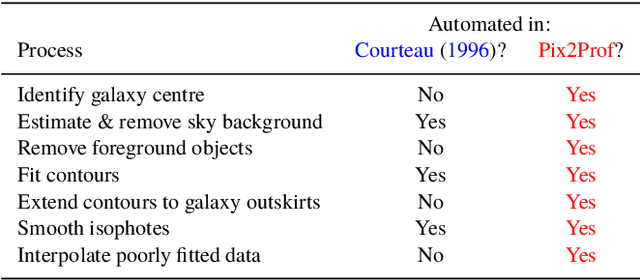
We present "Pix2Prof", a deep learning model that eliminates manual steps in the measurement of galaxy surface brightness (SB) profiles. We argue that a galaxy "profile" of any sort is conceptually similar to an image caption. This idea allows us to leverage image captioning methods from the field of natural language processing, and so we design Pix2Prof as a float sequence "captioning" model suitable for SB profile inferral. We demonstrate the technique by approximating the galaxy SB fitting method described by Courteau (1996), an algorithm with several manual steps. We use g, r, and i-band images from the Sloan Digital Sky Survey (SDSS) Data Release 10 (DR10) to train Pix2Prof on 5367 image--SB profile pairs. We test Pix2Prof on 300 SDSS DR10 galaxy image--SB profile pairs in each of the g, r, and i bands to calibrate the mean SB deviation between interactive manual measurements and automated extractions, and demonstrate the effectiveness of Pix2Prof in mirroring the manual method. Pix2Prof processes $\sim1$ image per second on an Intel Xeon E5-2650 v3 and $\sim2$ images per second on a NVIDIA TESLA V100, improving on the speed of the manual interactive method by more than two orders of magnitude. Crucially, Pix2Prof requires no manual interaction, and since galaxy profile estimation is an embarrassingly parallel problem, we can further increase the throughput by running many Pix2Prof instances simultaneously. In perspective, Pix2Prof would take under an hour to infer profiles for $10^5$ galaxies on a single NVIDIA DGX-2 system. A single human expert would take approximately two years to complete the same task. Automated methodology such as this will accelerate the analysis of the next generation of large area sky surveys expected to yield hundreds of millions of targets. In such instances, all manual approaches -- even those involving a large number of experts -- would be impractical.