 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Feynman-Kac Correctors
Jan 15, 2026Discrete diffusion models have recently emerged as a promising alternative to the autoregressive approach for generating discrete sequences. Sample generation via gradual denoising or demasking processes allows them to capture hierarchical non-sequential interdependencies in the data. These custom processes, however, do not assume a flexible control over the distribution of generated samples. We propose Discrete Feynman-Kac Correctors, a framework that allows for controlling the generated distribution of discrete masked diffusion models at inference time. We derive Sequential Monte Carlo (SMC) algorithms that, given a trained discrete diffusion model, control the temperature of the sampled distribution (i.e. perform annealing), sample from the product of marginals of several diffusion processes (e.g. differently conditioned processes), and sample from the product of the marginal with an external reward function, producing likely samples from the target distribution that also have high reward. Notably, our framework does not require any training of additional models or fine-tuning of the original model. We illustrate the utility of our framework in several applications including: efficient sampling from the annealed Boltzmann distribution of the Ising model, improving the performance of language models for code generation and amortized learning, as well as reward-tilted protein sequence generation.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
Outsourced diffusion sampling: Efficient posterior inference in latent spaces of generative models
Feb 10, 2025
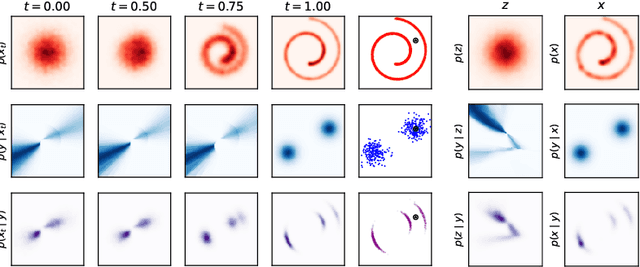


Any well-behaved generative model over a variable $\mathbf{x}$ can be expressed as a deterministic transformation of an exogenous ('outsourced') Gaussian noise variable $\mathbf{z}$: $\mathbf{x}=f_\theta(\mathbf{z})$. In such a model (e.g., a VAE, GAN, or continuous-time flow-based model), sampling of the target variable $\mathbf{x} \sim p_\theta(\mathbf{x})$ is straightforward, but sampling from a posterior distribution of the form $p(\mathbf{x}\mid\mathbf{y}) \propto p_\theta(\mathbf{x})r(\mathbf{x},\mathbf{y})$, where $r$ is a constraint function depending on an auxiliary variable $\mathbf{y}$, is generally intractable. We propose to amortize the cost of sampling from such posterior distributions with diffusion models that sample a distribution in the noise space ($\mathbf{z}$). These diffusion samplers are trained by reinforcement learning algorithms to enforce that the transformed samples $f_\theta(\mathbf{z})$ are distributed according to the posterior in the data space ($\mathbf{x}$). For many models and constraints of interest, the posterior in the noise space is smoother than the posterior in the data space, making it more amenable to such amortized inference. Our method enables conditional sampling under unconditional GAN, (H)VAE, and flow-based priors, comparing favorably both with current amortized and non-amortized inference methods. We demonstrate the proposed outsourced diffusion sampling in several experiments with large pretrained prior models: conditional image generation, reinforcement learning with human feedback, and protein structure generation.
Steering Masked Discrete Diffusion Models via Discrete Denoising Posterior Prediction
Oct 10, 2024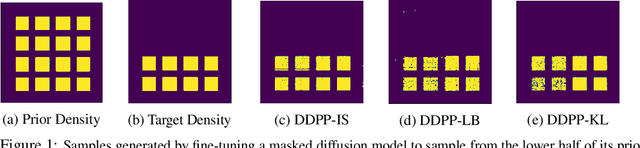

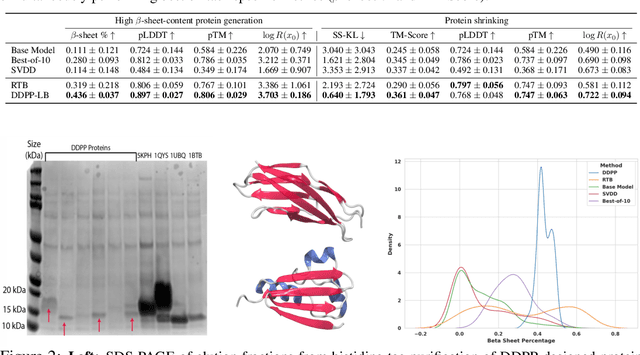

Generative modeling of discrete data underlies important applications spanning text-based agents like ChatGPT to the design of the very building blocks of life in protein sequences. However, application domains need to exert control over the generated data by steering the generative process - typically via RLHF - to satisfy a specified property, reward, or affinity metric. In this paper, we study the problem of steering Masked Diffusion Models (MDMs), a recent class of discrete diffusion models that offer a compelling alternative to traditional autoregressive models. We introduce Discrete Denoising Posterior Prediction (DDPP), a novel framework that casts the task of steering pre-trained MDMs as a problem of probabilistic inference by learning to sample from a target Bayesian posterior. Our DDPP framework leads to a family of three novel objectives that are all simulation-free, and thus scalable while applying to general non-differentiable reward functions. Empirically, we instantiate DDPP by steering MDMs to perform class-conditional pixel-level image modeling, RLHF-based alignment of MDMs using text-based rewards, and finetuning protein language models to generate more diverse secondary structures and shorter proteins. We substantiate our designs via wet-lab validation, where we observe transient expression of reward-optimized protein sequences.
Amortizing intractable inference in diffusion models for vision, language, and control
May 31, 2024



Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem. This paper studies amortized sampling of the posterior over data, $\mathbf{x}\sim p^{\rm post}(\mathbf{x})\propto p(\mathbf{x})r(\mathbf{x})$, in a model that consists of a diffusion generative model prior $p(\mathbf{x})$ and a black-box constraint or likelihood function $r(\mathbf{x})$. We state and prove the asymptotic correctness of a data-free learning objective, relative trajectory balance, for training a diffusion model that samples from this posterior, a problem that existing methods solve only approximately or in restricted cases. Relative trajectory balance arises from the generative flow network perspective on diffusion models, which allows the use of deep reinforcement learning techniques to improve mode coverage. Experiments illustrate the broad potential of unbiased inference of arbitrary posteriors under diffusion priors: in vision (classifier guidance), language (infilling under a discrete diffusion LLM), and multimodal data (text-to-image generation). Beyond generative modeling, we apply relative trajectory balance to the problem of continuous control with a score-based behavior prior, achieving state-of-the-art results on benchmarks in offline reinforcement learning.
Calibrated One Round Federated Learning with Bayesian Inference in the Predictive Space
Dec 15, 2023
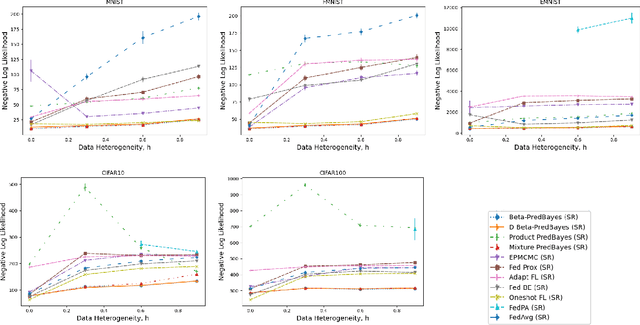
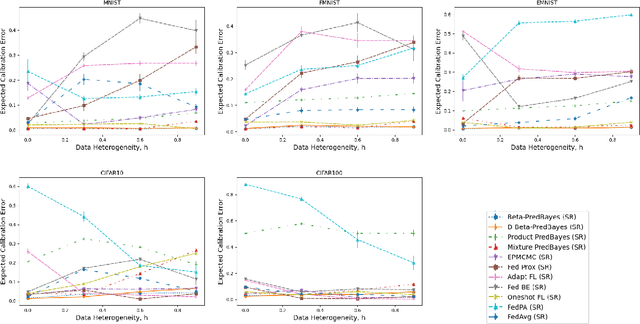
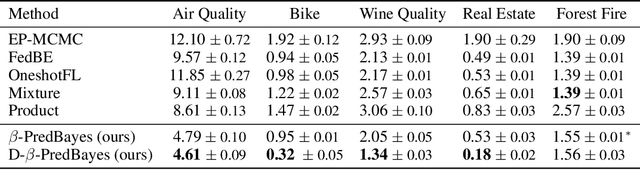
Federated Learning (FL) involves training a model over a dataset distributed among clients, with the constraint that each client's dataset is localized and possibly heterogeneous. In FL, small and noisy datasets are common, highlighting the need for well-calibrated models that represent the uncertainty of predictions. The closest FL techniques to achieving such goals are the Bayesian FL methods which collect parameter samples from local posteriors, and aggregate them to approximate the global posterior. To improve scalability for larger models, one common Bayesian approach is to approximate the global predictive posterior by multiplying local predictive posteriors. In this work, we demonstrate that this method gives systematically overconfident predictions, and we remedy this by proposing $\beta$-Predictive Bayes, a Bayesian FL algorithm that interpolates between a mixture and product of the predictive posteriors, using a tunable parameter $\beta$. This parameter is tuned to improve the global ensemble's calibration, before it is distilled to a single model. Our method is evaluated on a variety of regression and classification datasets to demonstrate its superiority in calibration to other baselines, even as data heterogeneity increases. Code available at https://github.com/hasanmohsin/betaPredBayes_FL
Robust One Round Federated Learning with Predictive Space Bayesian Inference
Jun 20, 2022


Making predictions robust is an important challenge. A separate challenge in federated learning (FL) is to reduce the number of communication rounds, particularly since doing so reduces performance in heterogeneous data settings. To tackle both issues, we take a Bayesian perspective on the problem of learning a global model. We show how the global predictive posterior can be approximated using client predictive posteriors. This is unlike other works which aggregate the local model space posteriors into the global model space posterior, and are susceptible to high approximation errors due to the posterior's high dimensional multimodal nature. In contrast, our method performs the aggregation on the predictive posteriors, which are typically easier to approximate owing to the low-dimensionality of the output space. We present an algorithm based on this idea, which performs MCMC sampling at each client to obtain an estimate of the local posterior, and then aggregates these in one round to obtain a global ensemble model. Through empirical evaluation on several classification and regression tasks, we show that despite using one round of communication, the method is competitive with other FL techniques, and outperforms them on heterogeneous settings. The code is publicly available at https://github.com/hasanmohsin/FedPredSpace_1Round.