 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Noise to Narrative: Tracing the Origins of Hallucinations in Transformers
Sep 08, 2025As generative AI systems become competent and democratized in science, business, and government, deeper insight into their failure modes now poses an acute need. The occasional volatility in their behavior, such as the propensity of transformer models to hallucinate, impedes trust and adoption of emerging AI solutions in high-stakes areas. In the present work, we establish how and when hallucinations arise in pre-trained transformer models through concept representations captured by sparse autoencoders, under scenarios with experimentally controlled uncertainty in the input space. Our systematic experiments reveal that the number of semantic concepts used by the transformer model grows as the input information becomes increasingly unstructured. In the face of growing uncertainty in the input space, the transformer model becomes prone to activate coherent yet input-insensitive semantic features, leading to hallucinated output. At its extreme, for pure-noise inputs, we identify a wide variety of robustly triggered and meaningful concepts in the intermediate activations of pre-trained transformer models, whose functional integrity we confirm through targeted steering. We also show that hallucinations in the output of a transformer model can be reliably predicted from the concept patterns embedded in transformer layer activations. This collection of insights on transformer internal processing mechanics has immediate consequences for aligning AI models with human values, AI safety, opening the attack surface for potential adversarial attacks, and providing a basis for automatic quantification of a model's hallucination risk.
Torsional-GFN: a conditional conformation generator for small molecules
Jul 15, 2025Generating stable molecular conformations is crucial in several drug discovery applications, such as estimating the binding affinity of a molecule to a target. Recently, generative machine learning methods have emerged as a promising, more efficient method than molecular dynamics for sampling of conformations from the Boltzmann distribution. In this paper, we introduce Torsional-GFN, a conditional GFlowNet specifically designed to sample conformations of molecules proportionally to their Boltzmann distribution, using only a reward function as training signal. Conditioned on a molecular graph and its local structure (bond lengths and angles), Torsional-GFN samples rotations of its torsion angles. Our results demonstrate that Torsional-GFN is able to sample conformations approximately proportional to the Boltzmann distribution for multiple molecules with a single model, and allows for zero-shot generalization to unseen bond lengths and angles coming from the MD simulations for such molecules. Our work presents a promising avenue for scaling the proposed approach to larger molecular systems, achieving zero-shot generalization to unseen molecules, and including the generation of the local structure into the GFlowNet model.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
Outsourced diffusion sampling: Efficient posterior inference in latent spaces of generative models
Feb 10, 2025


Any well-behaved generative model over a variable $\mathbf{x}$ can be expressed as a deterministic transformation of an exogenous ('outsourced') Gaussian noise variable $\mathbf{z}$: $\mathbf{x}=f_\theta(\mathbf{z})$. In such a model (e.g., a VAE, GAN, or continuous-time flow-based model), sampling of the target variable $\mathbf{x} \sim p_\theta(\mathbf{x})$ is straightforward, but sampling from a posterior distribution of the form $p(\mathbf{x}\mid\mathbf{y}) \propto p_\theta(\mathbf{x})r(\mathbf{x},\mathbf{y})$, where $r$ is a constraint function depending on an auxiliary variable $\mathbf{y}$, is generally intractable. We propose to amortize the cost of sampling from such posterior distributions with diffusion models that sample a distribution in the noise space ($\mathbf{z}$). These diffusion samplers are trained by reinforcement learning algorithms to enforce that the transformed samples $f_\theta(\mathbf{z})$ are distributed according to the posterior in the data space ($\mathbf{x}$). For many models and constraints of interest, the posterior in the noise space is smoother than the posterior in the data space, making it more amenable to such amortized inference. Our method enables conditional sampling under unconditional GAN, (H)VAE, and flow-based priors, comparing favorably both with current amortized and non-amortized inference methods. We demonstrate the proposed outsourced diffusion sampling in several experiments with large pretrained prior models: conditional image generation, reinforcement learning with human feedback, and protein structure generation.
Scalable Ensemble Diversification for OOD Generalization and Detection
Sep 25, 2024



Training a diverse ensemble of models has several practical applications such as providing candidates for model selection with better out-of-distribution (OOD) generalization, and enabling the detection of OOD samples via Bayesian principles. An existing approach to diverse ensemble training encourages the models to disagree on provided OOD samples. However, the approach is computationally expensive and it requires well-separated ID and OOD examples, such that it has only been demonstrated in small-scale settings. $\textbf{Method.}$ This work presents a method for Scalable Ensemble Diversification (SED) applicable to large-scale settings (e.g. ImageNet) that does not require OOD samples. Instead, SED identifies hard training samples on the fly and encourages the ensemble members to disagree on these. To improve scaling, we show how to avoid the expensive computations in existing methods of exhaustive pairwise disagreements across models. $\textbf{Results.}$ We evaluate the benefits of diversification with experiments on ImageNet. First, for OOD generalization, we observe large benefits from the diversification in multiple settings including output-space (classical) ensembles and weight-space ensembles (model soups). Second, for OOD detection, we turn the diversity of ensemble hypotheses into a novel uncertainty score estimator that surpasses a large number of OOD detection baselines. Code is available here: https://github.com/AlexanderRubinstein/diverse-universe-public.
Amortizing intractable inference in diffusion models for vision, language, and control
May 31, 2024



Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem. This paper studies amortized sampling of the posterior over data, $\mathbf{x}\sim p^{\rm post}(\mathbf{x})\propto p(\mathbf{x})r(\mathbf{x})$, in a model that consists of a diffusion generative model prior $p(\mathbf{x})$ and a black-box constraint or likelihood function $r(\mathbf{x})$. We state and prove the asymptotic correctness of a data-free learning objective, relative trajectory balance, for training a diffusion model that samples from this posterior, a problem that existing methods solve only approximately or in restricted cases. Relative trajectory balance arises from the generative flow network perspective on diffusion models, which allows the use of deep reinforcement learning techniques to improve mode coverage. Experiments illustrate the broad potential of unbiased inference of arbitrary posteriors under diffusion priors: in vision (classifier guidance), language (infilling under a discrete diffusion LLM), and multimodal data (text-to-image generation). Beyond generative modeling, we apply relative trajectory balance to the problem of continuous control with a score-based behavior prior, achieving state-of-the-art results on benchmarks in offline reinforcement learning.
On diffusion models for amortized inference: Benchmarking and improving stochastic control and sampling
Feb 13, 2024
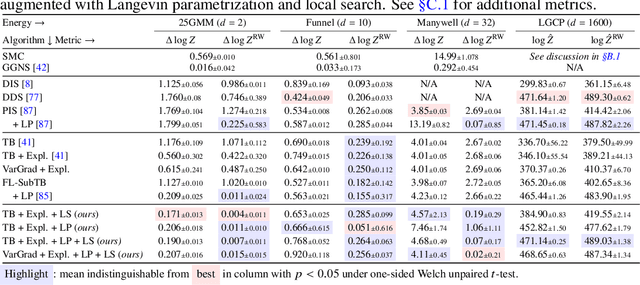
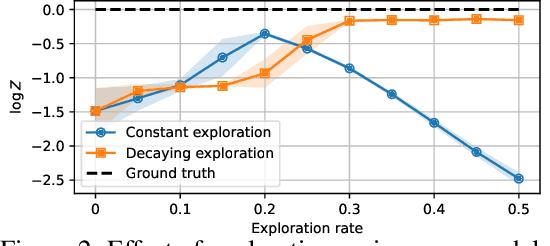
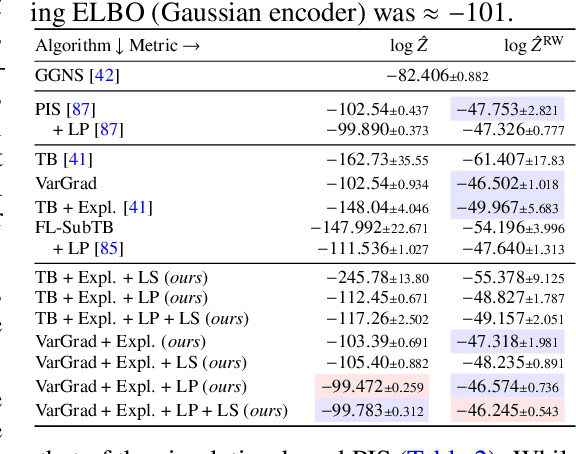
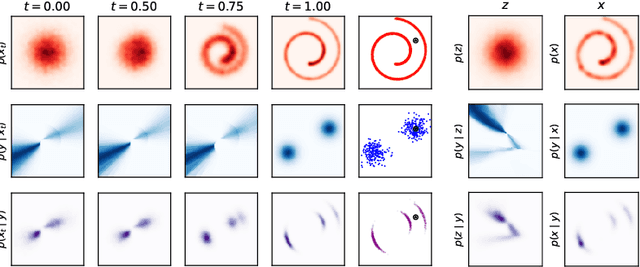
We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at https://github.com/GFNOrg/gfn-diffusion as a base for future work on diffusion models for amortized inference.
Shortcut Bias Mitigation via Ensemble Diversity Using Diffusion Probabilistic Models
Nov 23, 2023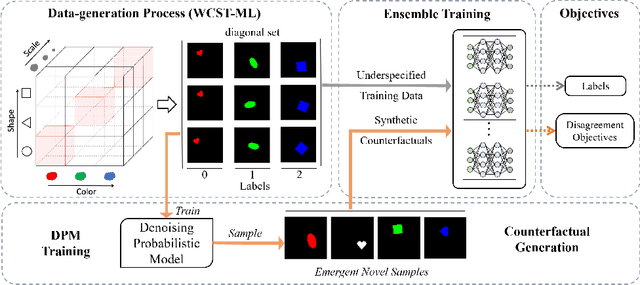
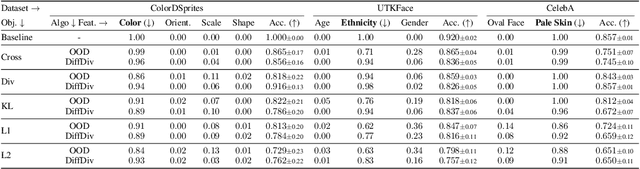

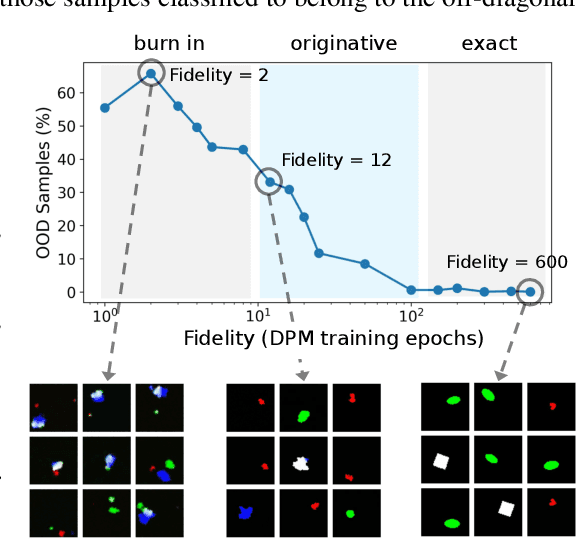
Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to a phenomenon known as simplicity bias, where a model relies on erroneous, easy-to-learn cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting Diffusion Probabilistic Models (DPMs) for shortcut bias mitigation. We show that at particular training intervals, DPMs can generate images with novel feature combinations, even when trained on images displaying correlated input features. We leverage this crucial property to generate synthetic counterfactuals to increase model diversity via ensemble disagreement. We show that DPM-guided diversification is sufficient to remove dependence on primary shortcut cues, without a need for additional supervised signals. We further empirically quantify its efficacy on several diversification objectives, and finally show improved generalization and diversification performance on par with prior work that relies on auxiliary data collection.
Leveraging Diffusion Disentangled Representations to Mitigate Shortcuts in Underspecified Visual Tasks
Oct 03, 2023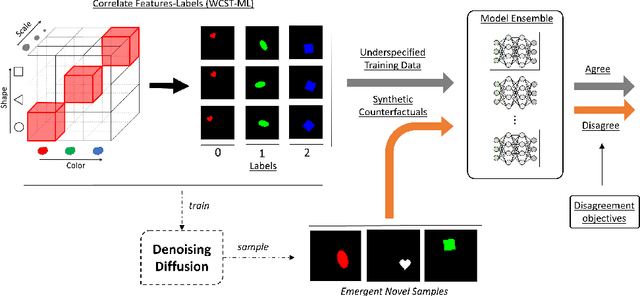
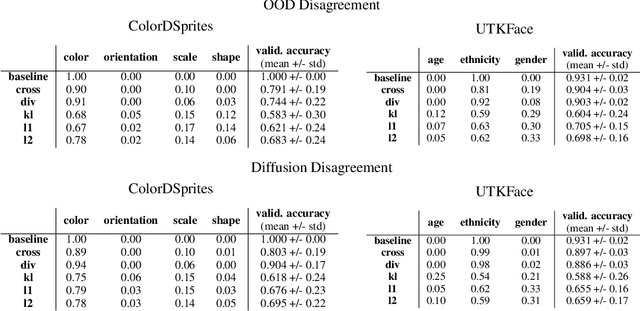
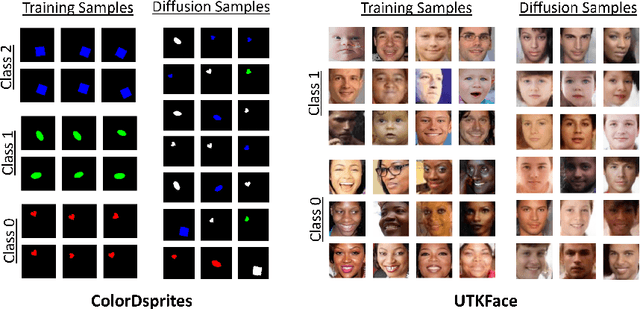

Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to shortcut learning phenomena, where a model may rely on erroneous, easy-to-learn, cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting the generation of synthetic counterfactuals using Diffusion Probabilistic Models (DPMs). We discover that DPMs have the inherent capability to represent multiple visual cues independently, even when they are largely correlated in the training data. We leverage this characteristic to encourage model diversity and empirically show the efficacy of the approach with respect to several diversification objectives. We show that diffusion-guided diversification can lead models to avert attention from shortcut cues, achieving ensemble diversity performance comparable to previous methods requiring additional data collection.
Which Shortcut Cues Will DNNs Choose? A Study from the Parameter-Space Perspective
Oct 06, 2021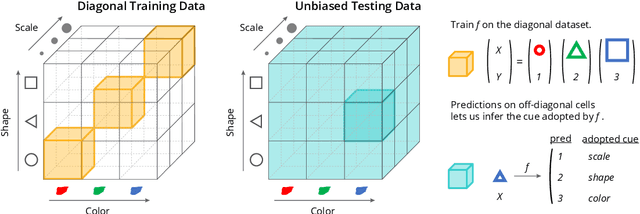
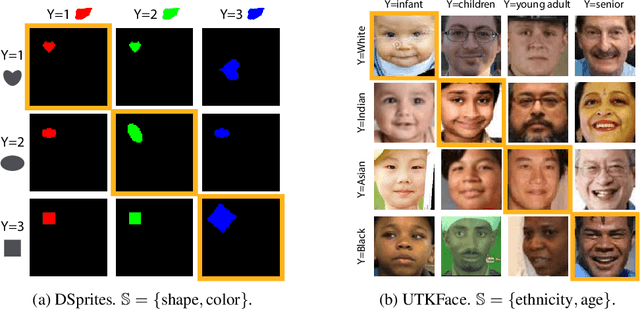
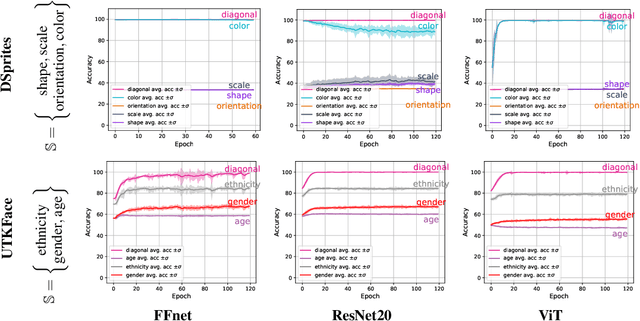
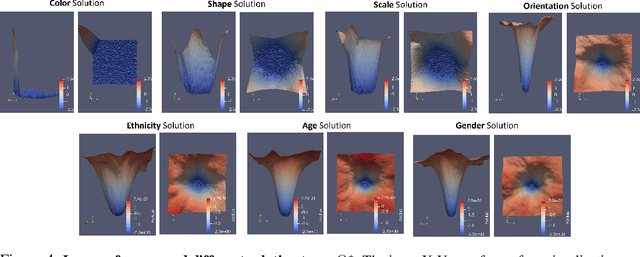
Deep neural networks (DNNs) often rely on easy-to-learn discriminatory features, or cues, that are not necessarily essential to the problem at hand. For example, ducks in an image may be recognized based on their typical background scenery, such as lakes or streams. This phenomenon, also known as shortcut learning, is emerging as a key limitation of the current generation of machine learning models. In this work, we introduce a set of experiments to deepen our understanding of shortcut learning and its implications. We design a training setup with several shortcut cues, named WCST-ML, where each cue is equally conducive to the visual recognition problem at hand. Even under equal opportunities, we observe that (1) certain cues are preferred to others, (2) solutions biased to the easy-to-learn cues tend to converge to relatively flat minima on the loss surface, and (3) the solutions focusing on those preferred cues are far more abundant in the parameter space. We explain the abundance of certain cues via their Kolmogorov (descriptional) complexity: solutions corresponding to Kolmogorov-simple cues are abundant in the parameter space and are thus preferred by DNNs. Our studies are based on the synthetic dataset DSprites and the face dataset UTKFace. In our WCST-ML, we observe that the inborn bias of models leans toward simple cues, such as color and ethnicity. Our findings emphasize the importance of active human intervention to remove the inborn model biases that may cause negative societal impacts.