 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Redshift: Random Networks are not Random Functions
Mar 05, 2024



Our understanding of the generalization capabilities of neural networks (NNs) is still incomplete. Prevailing explanations are based on implicit biases of gradient descent (GD) but they cannot account for the capabilities of models from gradient-free methods nor the simplicity bias recently observed in untrained networks. This paper seeks other sources of generalization in NNs. Findings. To understand the inductive biases provided by architectures independently from GD, we examine untrained, random-weight networks. Even simple MLPs show strong inductive biases: uniform sampling in weight space yields a very biased distribution of functions in terms of complexity. But unlike common wisdom, NNs do not have an inherent "simplicity bias". This property depends on components such as ReLUs, residual connections, and layer normalizations. Alternative architectures can be built with a bias for any level of complexity. Transformers also inherit all these properties from their building blocks. Implications. We provide a fresh explanation for the success of deep learning independent from gradient-based training. It points at promising avenues for controlling the solutions implemented by trained models.
Leveraging Diffusion Disentangled Representations to Mitigate Shortcuts in Underspecified Visual Tasks
Oct 03, 2023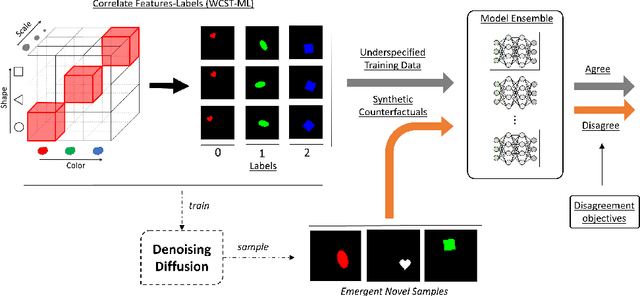
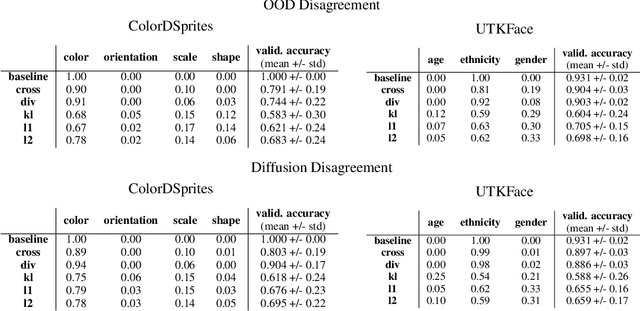
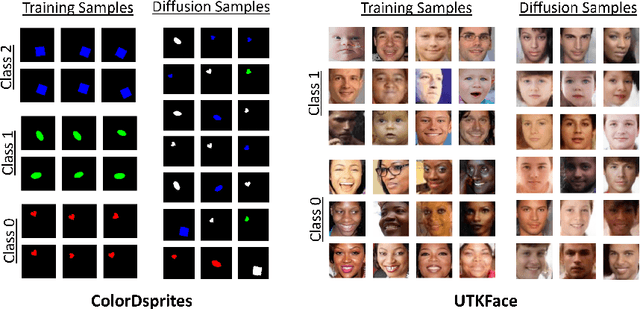

Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to shortcut learning phenomena, where a model may rely on erroneous, easy-to-learn, cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting the generation of synthetic counterfactuals using Diffusion Probabilistic Models (DPMs). We discover that DPMs have the inherent capability to represent multiple visual cues independently, even when they are largely correlated in the training data. We leverage this characteristic to encourage model diversity and empirically show the efficacy of the approach with respect to several diversification objectives. We show that diffusion-guided diversification can lead models to avert attention from shortcut cues, achieving ensemble diversity performance comparable to previous methods requiring additional data collection.