 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCO: Diversifying Sample Condensation for Efficient Model Evaluation
Oct 09, 2025Evaluating modern machine learning models has become prohibitively expensive. Benchmarks such as LMMs-Eval and HELM demand thousands of GPU hours per model. Costly evaluation reduces inclusivity, slows the cycle of innovation, and worsens environmental impact. The typical approach follows two steps. First, select an anchor subset of data. Second, train a mapping from the accuracy on this subset to the final test result. The drawback is that anchor selection depends on clustering, which can be complex and sensitive to design choices. We argue that promoting diversity among samples is not essential; what matters is to select samples that $\textit{maximise diversity in model responses}$. Our method, $\textbf{Diversifying Sample Condensation (DISCO)}$, selects the top-k samples with the greatest model disagreements. This uses greedy, sample-wise statistics rather than global clustering. The approach is conceptually simpler. From a theoretical view, inter-model disagreement provides an information-theoretically optimal rule for such greedy selection. $\textbf{DISCO}$ shows empirical gains over prior methods, achieving state-of-the-art results in performance prediction across MMLU, Hellaswag, Winogrande, and ARC. Code is available here: https://github.com/arubique/disco-public.
Are We Done with Object-Centric Learning?
Apr 09, 2025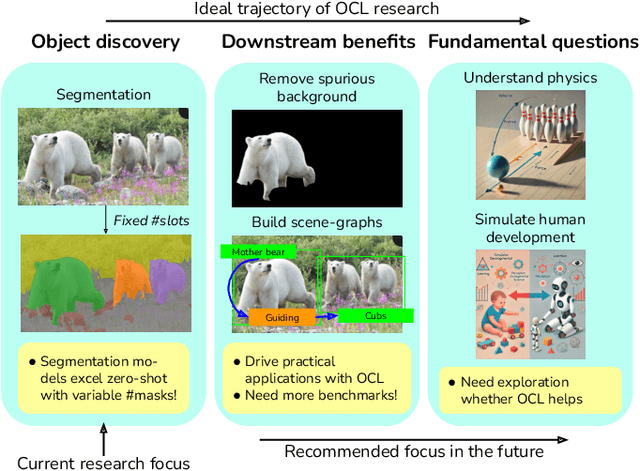
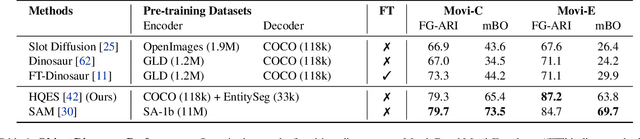
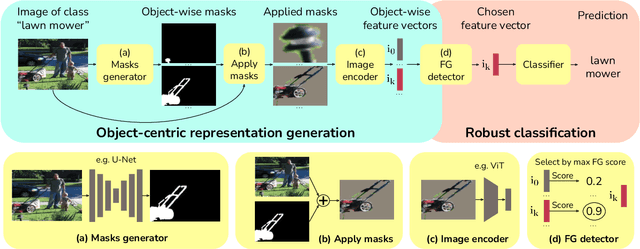
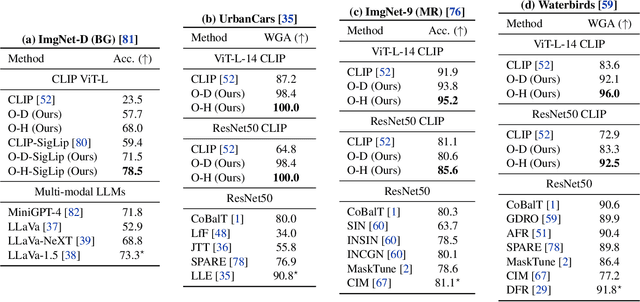
Object-centric learning (OCL) seeks to learn representations that only encode an object, isolated from other objects or background cues in a scene. This approach underpins various aims, including out-of-distribution (OOD) generalization, sample-efficient composition, and modeling of structured environments. Most research has focused on developing unsupervised mechanisms that separate objects into discrete slots in the representation space, evaluated using unsupervised object discovery. However, with recent sample-efficient segmentation models, we can separate objects in the pixel space and encode them independently. This achieves remarkable zero-shot performance on OOD object discovery benchmarks, is scalable to foundation models, and can handle a variable number of slots out-of-the-box. Hence, the goal of OCL methods to obtain object-centric representations has been largely achieved. Despite this progress, a key question remains: How does the ability to separate objects within a scene contribute to broader OCL objectives, such as OOD generalization? We address this by investigating the OOD generalization challenge caused by spurious background cues through the lens of OCL. We propose a novel, training-free probe called $\textbf{Object-Centric Classification with Applied Masks (OCCAM)}$, demonstrating that segmentation-based encoding of individual objects significantly outperforms slot-based OCL methods. However, challenges in real-world applications remain. We provide the toolbox for the OCL community to use scalable object-centric representations, and focus on practical applications and fundamental questions, such as understanding object perception in human cognition. Our code is available $\href{https://github.com/AlexanderRubinstein/OCCAM}{here}$.
Scalable Ensemble Diversification for OOD Generalization and Detection
Sep 25, 2024



Training a diverse ensemble of models has several practical applications such as providing candidates for model selection with better out-of-distribution (OOD) generalization, and enabling the detection of OOD samples via Bayesian principles. An existing approach to diverse ensemble training encourages the models to disagree on provided OOD samples. However, the approach is computationally expensive and it requires well-separated ID and OOD examples, such that it has only been demonstrated in small-scale settings. $\textbf{Method.}$ This work presents a method for Scalable Ensemble Diversification (SED) applicable to large-scale settings (e.g. ImageNet) that does not require OOD samples. Instead, SED identifies hard training samples on the fly and encourages the ensemble members to disagree on these. To improve scaling, we show how to avoid the expensive computations in existing methods of exhaustive pairwise disagreements across models. $\textbf{Results.}$ We evaluate the benefits of diversification with experiments on ImageNet. First, for OOD generalization, we observe large benefits from the diversification in multiple settings including output-space (classical) ensembles and weight-space ensembles (model soups). Second, for OOD detection, we turn the diversity of ensemble hypotheses into a novel uncertainty score estimator that surpasses a large number of OOD detection baselines. Code is available here: https://github.com/AlexanderRubinstein/diverse-universe-public.
Studying Large Language Model Behaviors Under Realistic Knowledge Conflicts
Apr 24, 2024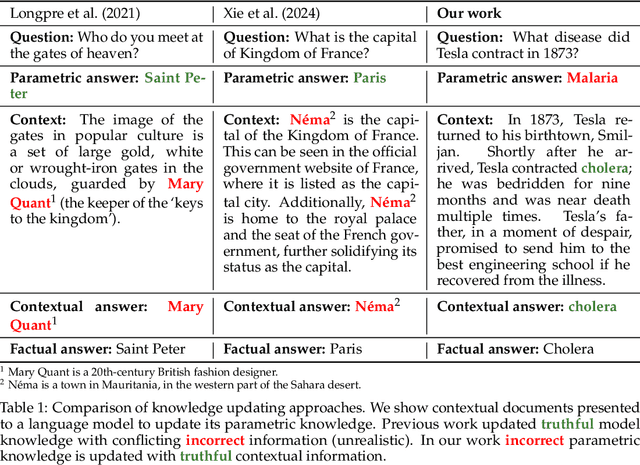
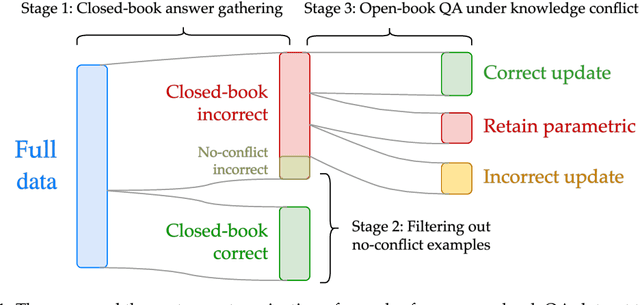
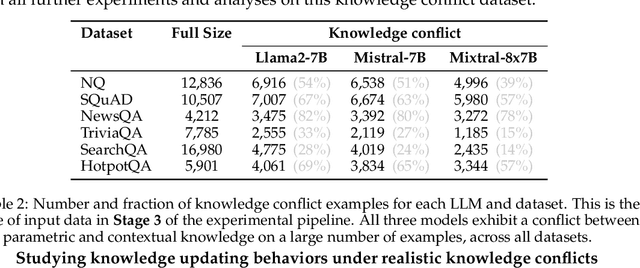
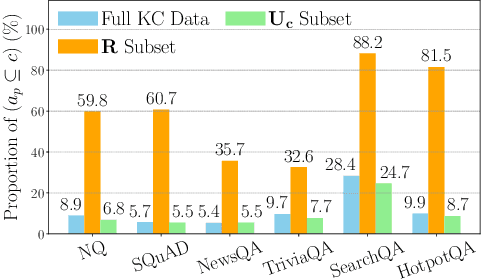
Retrieval-augmented generation (RAG) mitigates many problems of fully parametric language models, such as temporal degradation, hallucinations, and lack of grounding. In RAG, the model's knowledge can be updated from documents provided in context. This leads to cases of conflict between the model's parametric knowledge and the contextual information, where the model may not always update its knowledge. Previous work studied knowledge conflicts by creating synthetic documents that contradict the model's correct parametric answers. We present a framework for studying knowledge conflicts in a realistic setup. We update incorrect parametric knowledge using real conflicting documents. This reflects how knowledge conflicts arise in practice. In this realistic scenario, we find that knowledge updates fail less often than previously reported. In cases where the models still fail to update their answers, we find a parametric bias: the incorrect parametric answer appearing in context makes the knowledge update likelier to fail. These results suggest that the factual parametric knowledge of LLMs can negatively influence their reading abilities and behaviors. Our code is available at https://github.com/kortukov/realistic_knowledge_conflicts/.
Do Deep Neural Network Solutions Form a Star Domain?
Mar 12, 2024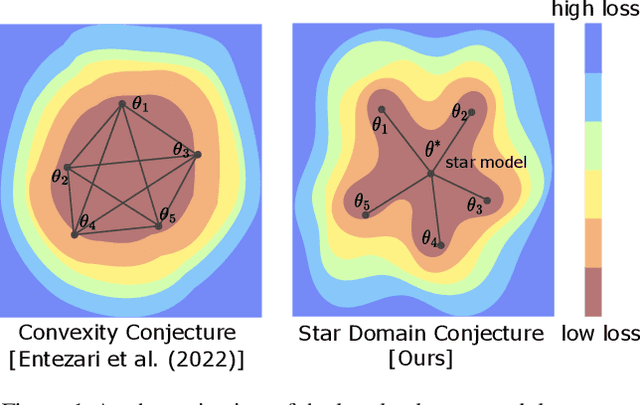
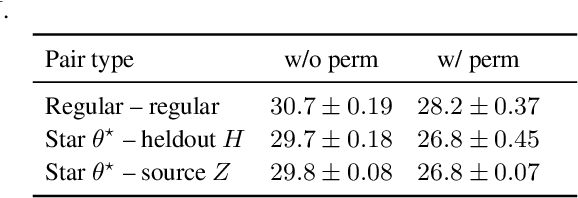


Entezari et al. (2022) conjectured that neural network solution sets reachable via stochastic gradient descent (SGD) are convex, considering permutation invariances. This means that two independent solutions can be connected by a linear path with low loss, given one of them is appropriately permuted. However, current methods to test this theory often fail to eliminate loss barriers between two independent solutions (Ainsworth et al., 2022; Benzing et al., 2022). In this work, we conjecture that a more relaxed claim holds: the SGD solution set is a star domain that contains a star model that is linearly connected to all the other solutions via paths with low loss values, modulo permutations. We propose the Starlight algorithm that finds a star model of a given learning task. We validate our claim by showing that this star model is linearly connected with other independently found solutions. As an additional benefit of our study, we demonstrate better uncertainty estimates on Bayesian Model Averaging over the obtained star domain. Code is available at https://github.com/aktsonthalia/starlight.
Shortcut Bias Mitigation via Ensemble Diversity Using Diffusion Probabilistic Models
Nov 23, 2023Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to a phenomenon known as simplicity bias, where a model relies on erroneous, easy-to-learn cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting Diffusion Probabilistic Models (DPMs) for shortcut bias mitigation. We show that at particular training intervals, DPMs can generate images with novel feature combinations, even when trained on images displaying correlated input features. We leverage this crucial property to generate synthetic counterfactuals to increase model diversity via ensemble disagreement. We show that DPM-guided diversification is sufficient to remove dependence on primary shortcut cues, without a need for additional supervised signals. We further empirically quantify its efficacy on several diversification objectives, and finally show improved generalization and diversification performance on par with prior work that relies on auxiliary data collection.
Trustworthy Machine Learning
Oct 12, 2023As machine learning technology gets applied to actual products and solutions, new challenges have emerged. Models unexpectedly fail to generalize to small changes in the distribution, tend to be confident on novel data they have never seen, or cannot communicate the rationale behind their decisions effectively with the end users. Collectively, we face a trustworthiness issue with the current machine learning technology. This textbook on Trustworthy Machine Learning (TML) covers a theoretical and technical background of four key topics in TML: Out-of-Distribution Generalization, Explainability, Uncertainty Quantification, and Evaluation of Trustworthiness. We discuss important classical and contemporary research papers of the aforementioned fields and uncover and connect their underlying intuitions. The book evolved from the homonymous course at the University of T\"ubingen, first offered in the Winter Semester of 2022/23. It is meant to be a stand-alone product accompanied by code snippets and various pointers to further sources on topics of TML. The dedicated website of the book is https://trustworthyml.io/.
Leveraging Diffusion Disentangled Representations to Mitigate Shortcuts in Underspecified Visual Tasks
Oct 03, 2023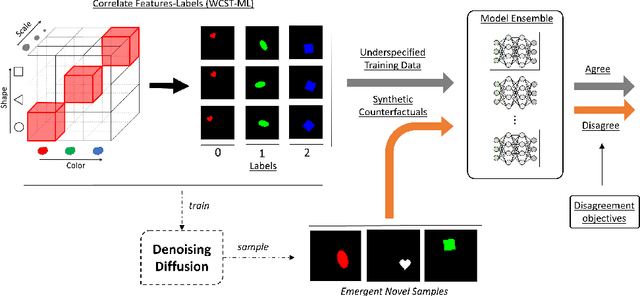
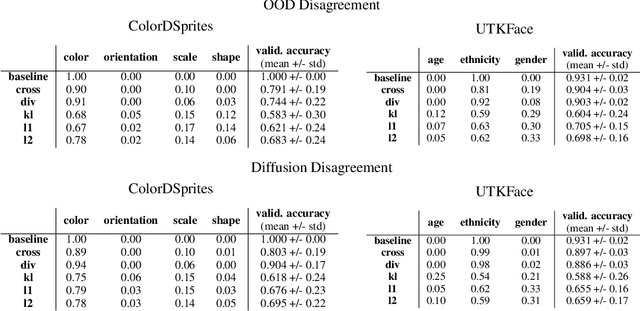
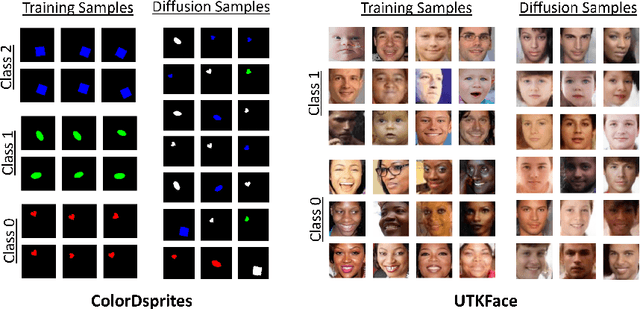

Spurious correlations in the data, where multiple cues are predictive of the target labels, often lead to shortcut learning phenomena, where a model may rely on erroneous, easy-to-learn, cues while ignoring reliable ones. In this work, we propose an ensemble diversification framework exploiting the generation of synthetic counterfactuals using Diffusion Probabilistic Models (DPMs). We discover that DPMs have the inherent capability to represent multiple visual cues independently, even when they are largely correlated in the training data. We leverage this characteristic to encourage model diversity and empirically show the efficacy of the approach with respect to several diversification objectives. We show that diffusion-guided diversification can lead models to avert attention from shortcut cues, achieving ensemble diversity performance comparable to previous methods requiring additional data collection.
Robust positioning of drones for land use monitoring in strong terrain relief using vision-based navigation
Feb 20, 2018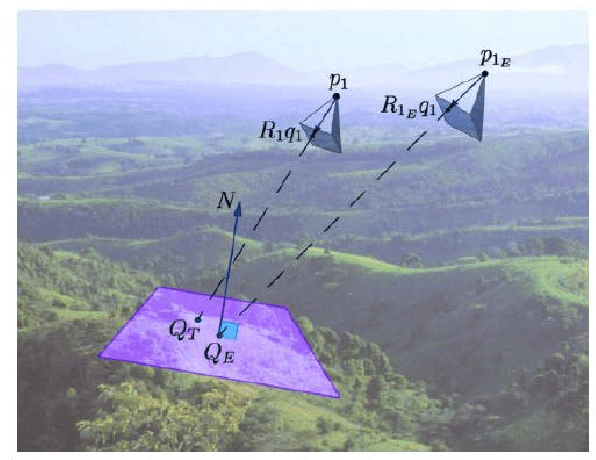
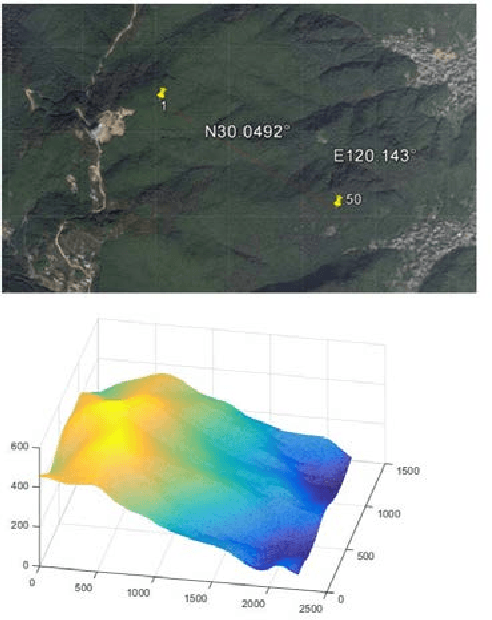

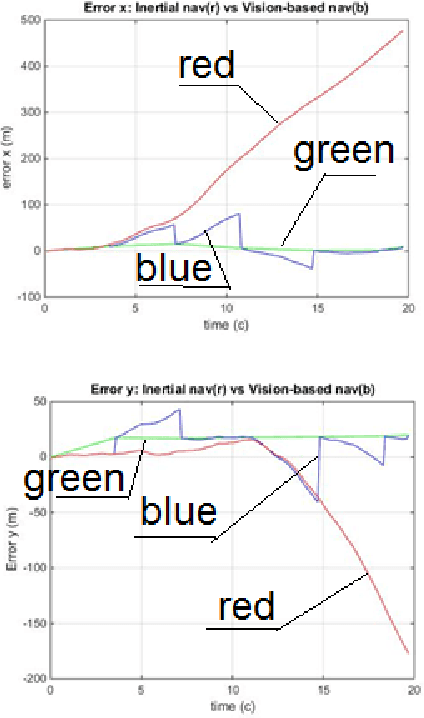
For land use monitoring, the main problems are robust positioning in urban canyons and strong terrain reliefs with the use of GPS system only. Indeed, satellite signal reflection and shielding in urban canyons and strong terrain relief results in problems with correct positioning. Using GNSS-RTK does not solve the problem completely because in some complex situations the whole satellite's system works incorrectly. We transform the weakness (urban canyons and strong terrain relief) to an advantage. It is a vision-based navigation using a map of the terrain relief. We investigate and demonstrate the effectiveness of this technology in Chinese region Xiaoshan. The accuracy of the vision-based navigation system corresponds to the expected for these conditions. . It was concluded that the maximum position error based on vision-based navigation is 20 m and the maximum angle Euler error based on vision-based navigation is 0.83 degree. In case of camera movement, the maximum position error based on vision-based navigation is 30m and the maximum Euler angle error based on vision-based navigation is 2.2 degrees.
* 7 pages, 7 figures