 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-based explanations of Segmentation and Detection models in Natural Disaster Management
Mar 24, 2026Deep learning models for flood and wildfire segmentation and object detection enable precise, real-time disaster localization when deployed on embedded drone platforms. However, in natural disaster management, the lack of transparency in their decision-making process hinders human trust required for emergency response. To address this, we present an explainability framework for understanding flood segmentation and car detection predictions on the widely used PIDNet and YOLO architectures. More specifically, we introduce a novel redistribution strategy that extends Layer-wise Relevance Propagation (LRP) explanations for sigmoid-gated element-wise fusion layers. This extension allows LRP relevances to flow through the fusion modules of PIDNet, covering the entire computation graph back to the input image. Furthermore, we apply Prototypical Concept-based Explanations (PCX) to provide both local and global explanations at the concept level, revealing which learned features drive the segmentation and detection of specific disaster semantic classes. Experiments on a publicly available flood dataset show that our framework provides reliable and interpretable explanations while maintaining near real-time inference capabilities, rendering it suitable for deployment on resource-constrained platforms, such as Unmanned Aerial Vehicles (UAVs).
A Behavioural and Representational Evaluation of Goal-Directedness in Language Model Agents
Feb 09, 2026Understanding an agent's goals helps explain and predict its behaviour, yet there is no established methodology for reliably attributing goals to agentic systems. We propose a framework for evaluating goal-directedness that integrates behavioural evaluation with interpretability-based analyses of models' internal representations. As a case study, we examine an LLM agent navigating a 2D grid world toward a goal state. Behaviourally, we evaluate the agent against an optimal policy across varying grid sizes, obstacle densities, and goal structures, finding that performance scales with task difficulty while remaining robust to difficulty-preserving transformations and complex goal structures. We then use probing methods to decode the agent's internal representations of the environment state and its multi-step action plans. We find that the LLM agent non-linearly encodes a coarse spatial map of the environment, preserving approximate task-relevant cues about its position and the goal location; that its actions are broadly consistent with these internal representations; and that reasoning reorganises them, shifting from broader environment structural cues toward information supporting immediate action selection. Our findings support the view that introspective examination is required beyond behavioural evaluations to characterise how agents represent and pursue their objectives.
ASIDE: Architectural Separation of Instructions and Data in Language Models
Mar 13, 2025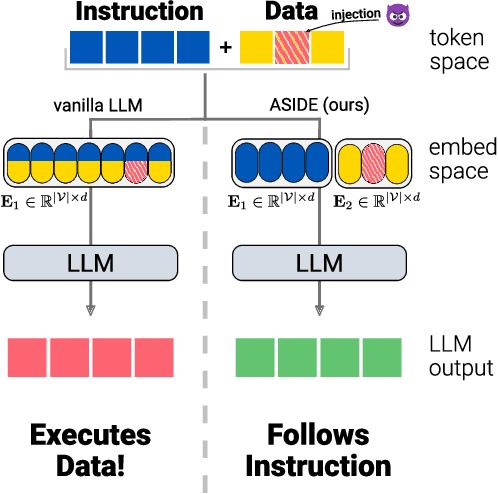
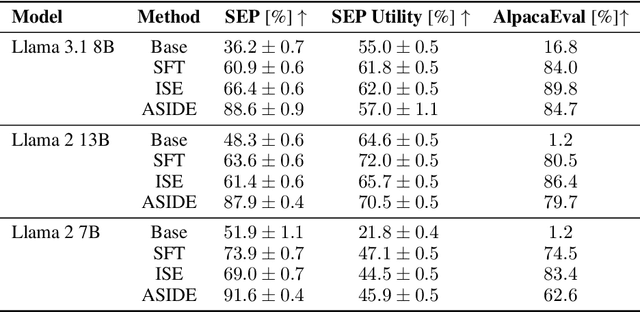
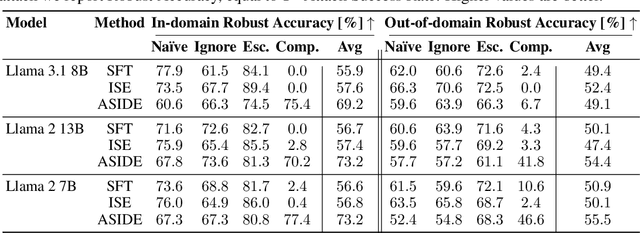
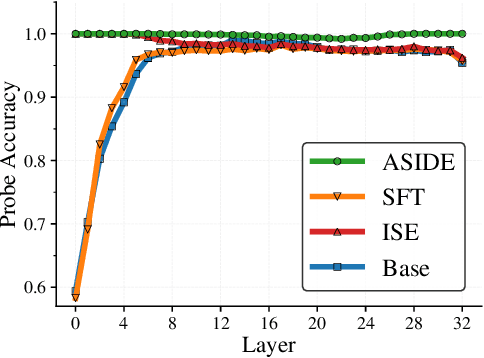
Despite their remarkable performance, large language models lack elementary safety features, and this makes them susceptible to numerous malicious attacks. In particular, previous work has identified the absence of an intrinsic separation between instructions and data as a root cause for the success of prompt injection attacks. In this work, we propose an architectural change, ASIDE, that allows the model to clearly separate between instructions and data by using separate embeddings for them. Instead of training the embeddings from scratch, we propose a method to convert an existing model to ASIDE form by using two copies of the original model's embeddings layer, and applying an orthogonal rotation to one of them. We demonstrate the effectiveness of our method by showing (1) highly increased instruction-data separation scores without a loss in model capabilities and (2) competitive results on prompt injection benchmarks, even without dedicated safety training. Additionally, we study the working mechanism behind our method through an analysis of model representations.
Towards User-Focused Research in Training Data Attribution for Human-Centered Explainable AI
Sep 25, 2024
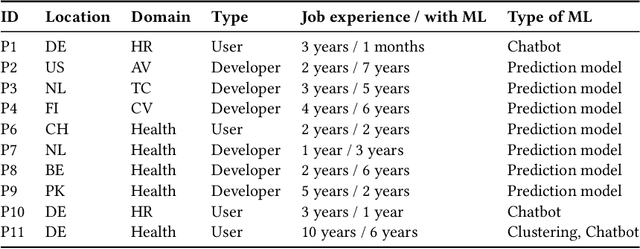
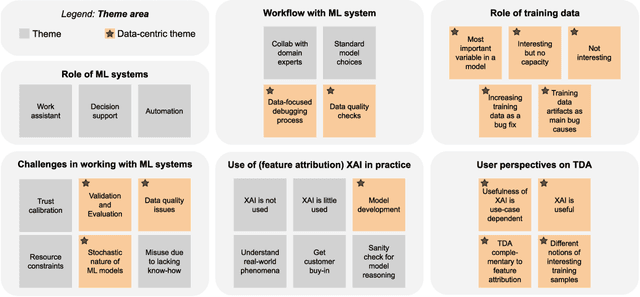
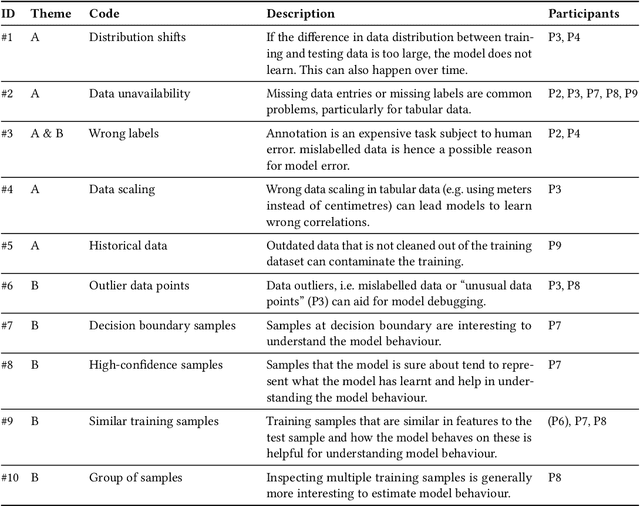
While Explainable AI (XAI) aims to make AI understandable and useful to humans, it has been criticised for relying too much on formalism and solutionism, focusing more on mathematical soundness than user needs. We propose an alternative to this bottom-up approach inspired by design thinking: the XAI research community should adopt a top-down, user-focused perspective to ensure user relevance. We illustrate this with a relatively young subfield of XAI, Training Data Attribution (TDA). With the surge in TDA research and growing competition, the field risks repeating the same patterns of solutionism. We conducted a needfinding study with a diverse group of AI practitioners to identify potential user needs related to TDA. Through interviews (N=10) and a systematic survey (N=31), we uncovered new TDA tasks that are currently largely overlooked. We invite the TDA and XAI communities to consider these novel tasks and improve the user relevance of their research outcomes.
Studying Large Language Model Behaviors Under Realistic Knowledge Conflicts
Apr 24, 2024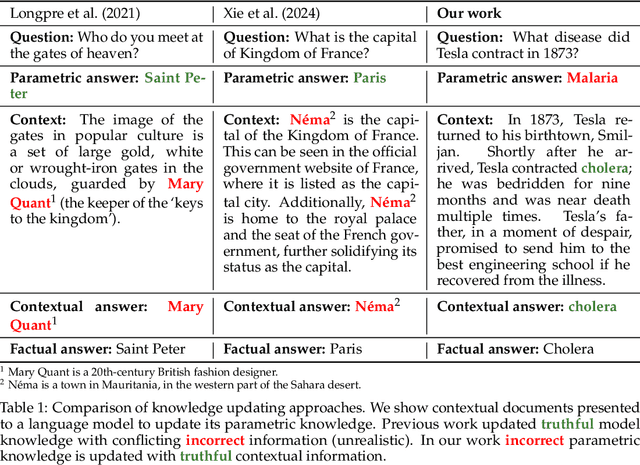
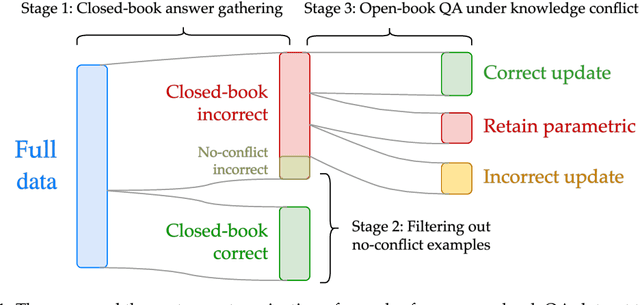
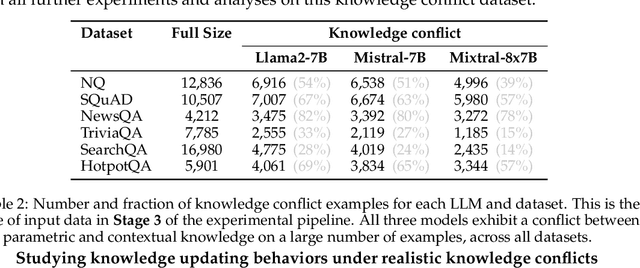
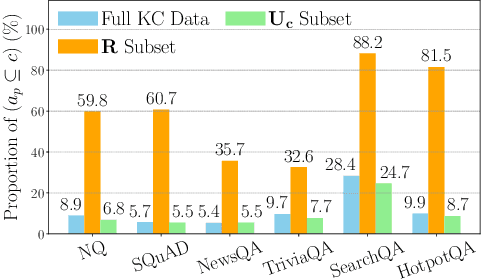
Retrieval-augmented generation (RAG) mitigates many problems of fully parametric language models, such as temporal degradation, hallucinations, and lack of grounding. In RAG, the model's knowledge can be updated from documents provided in context. This leads to cases of conflict between the model's parametric knowledge and the contextual information, where the model may not always update its knowledge. Previous work studied knowledge conflicts by creating synthetic documents that contradict the model's correct parametric answers. We present a framework for studying knowledge conflicts in a realistic setup. We update incorrect parametric knowledge using real conflicting documents. This reflects how knowledge conflicts arise in practice. In this realistic scenario, we find that knowledge updates fail less often than previously reported. In cases where the models still fail to update their answers, we find a parametric bias: the incorrect parametric answer appearing in context makes the knowledge update likelier to fail. These results suggest that the factual parametric knowledge of LLMs can negatively influence their reading abilities and behaviors. Our code is available at https://github.com/kortukov/realistic_knowledge_conflicts/.
Exploring Practitioner Perspectives On Training Data Attribution Explanations
Oct 31, 2023Explainable AI (XAI) aims to provide insight into opaque model reasoning to humans and as such is an interdisciplinary field by nature. In this paper, we interviewed 10 practitioners to understand the possible usability of training data attribution (TDA) explanations and to explore the design space of such an approach. We confirmed that training data quality is often the most important factor for high model performance in practice and model developers mainly rely on their own experience to curate data. End-users expect explanations to enhance their interaction with the model and do not necessarily prioritise but are open to training data as a means of explanation. Within our participants, we found that TDA explanations are not well-known and therefore not used. We urge the community to focus on the utility of TDA techniques from the human-machine collaboration perspective and broaden the TDA evaluation to reflect common use cases in practice.
Online Learning with Costly Features in Non-stationary Environments
Jul 18, 2023Maximizing long-term rewards is the primary goal in sequential decision-making problems. The majority of existing methods assume that side information is freely available, enabling the learning agent to observe all features' states before making a decision. In real-world problems, however, collecting beneficial information is often costly. That implies that, besides individual arms' reward, learning the observations of the features' states is essential to improve the decision-making strategy. The problem is aggravated in a non-stationary environment where reward and cost distributions undergo abrupt changes over time. To address the aforementioned dual learning problem, we extend the contextual bandit setting and allow the agent to observe subsets of features' states. The objective is to maximize the long-term average gain, which is the difference between the accumulated rewards and the paid costs on average. Therefore, the agent faces a trade-off between minimizing the cost of information acquisition and possibly improving the decision-making process using the obtained information. To this end, we develop an algorithm that guarantees a sublinear regret in time. Numerical results demonstrate the superiority of our proposed policy in a real-world scenario.