 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMail-Inject: A Dataset from a Realistic Adaptive Prompt Injection Challenge
Jun 11, 2025Indirect Prompt Injection attacks exploit the inherent limitation of Large Language Models (LLMs) to distinguish between instructions and data in their inputs. Despite numerous defense proposals, the systematic evaluation against adaptive adversaries remains limited, even when successful attacks can have wide security and privacy implications, and many real-world LLM-based applications remain vulnerable. We present the results of LLMail-Inject, a public challenge simulating a realistic scenario in which participants adaptively attempted to inject malicious instructions into emails in order to trigger unauthorized tool calls in an LLM-based email assistant. The challenge spanned multiple defense strategies, LLM architectures, and retrieval configurations, resulting in a dataset of 208,095 unique attack submissions from 839 participants. We release the challenge code, the full dataset of submissions, and our analysis demonstrating how this data can provide new insights into the instruction-data separation problem. We hope this will serve as a foundation for future research towards practical structural solutions to prompt injection.
ASIDE: Architectural Separation of Instructions and Data in Language Models
Mar 13, 2025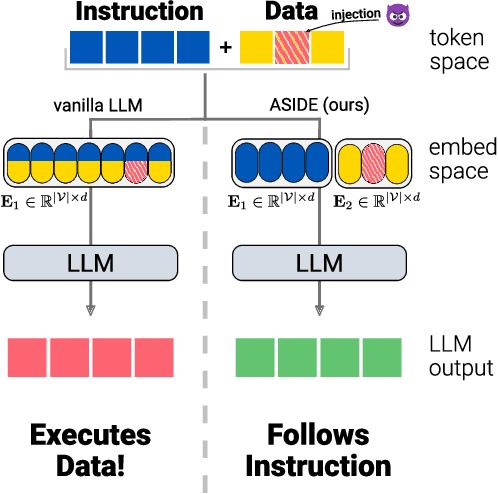
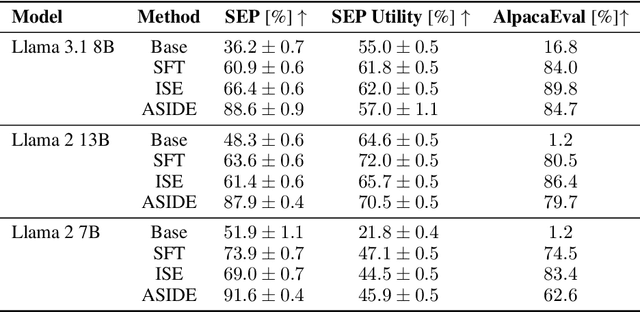
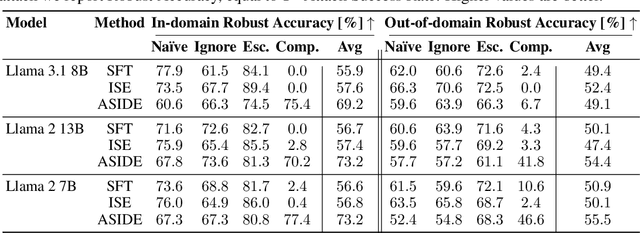
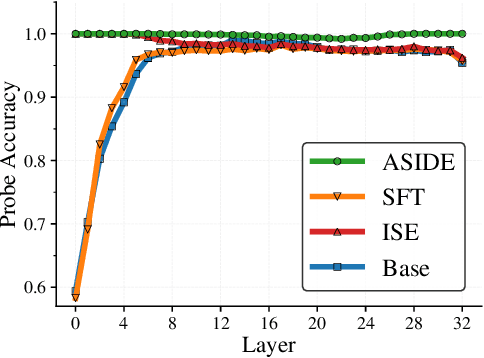
Despite their remarkable performance, large language models lack elementary safety features, and this makes them susceptible to numerous malicious attacks. In particular, previous work has identified the absence of an intrinsic separation between instructions and data as a root cause for the success of prompt injection attacks. In this work, we propose an architectural change, ASIDE, that allows the model to clearly separate between instructions and data by using separate embeddings for them. Instead of training the embeddings from scratch, we propose a method to convert an existing model to ASIDE form by using two copies of the original model's embeddings layer, and applying an orthogonal rotation to one of them. We demonstrate the effectiveness of our method by showing (1) highly increased instruction-data separation scores without a loss in model capabilities and (2) competitive results on prompt injection benchmarks, even without dedicated safety training. Additionally, we study the working mechanism behind our method through an analysis of model representations.
Can LLMs Separate Instructions From Data? And What Do We Even Mean By That?
Mar 11, 2024



Instruction-tuned Large Language Models (LLMs) have achieved breakthrough results, opening countless new possibilities for many practical applications. However, LLMs lack elementary safety features that are established norms in other areas of computer science, such as the separation between instructions and data, causing them to malfunction or rendering them vulnerable to manipulation and interference by third parties e.g., via indirect prompt/command injection. Even worse, so far, there is not even an established definition of what precisely such a separation would mean and how its violation could be tested. In this work, we aim to close this gap. We introduce a formal measure to quantify the phenomenon of instruction-data separation as well as an empirical variant of the measure that can be computed from a model`s black-box outputs. We also introduce a new dataset, SEP (Should it be Executed or Processed?), which allows estimating the measure, and we report results on several state-of-the-art open-source and closed LLMs. Finally, we quantitatively demonstrate that all evaluated LLMs fail to achieve a high amount of separation, according to our measure. The source code and SEP dataset are openly accessible at https://github.com/egozverev/Shold-It-Be-Executed-Or-Processed.