 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-Inject: Measuring Agent Vulnerability to Skill File Attacks
Feb 25, 2026LLM agents are evolving rapidly, powered by code execution, tools, and the recently introduced agent skills feature. Skills allow users to extend LLM applications with specialized third-party code, knowledge, and instructions. Although this can extend agent capabilities to new domains, it creates an increasingly complex agent supply chain, offering new surfaces for prompt injection attacks. We identify skill-based prompt injection as a significant threat and introduce SkillInject, a benchmark evaluating the susceptibility of widely-used LLM agents to injections through skill files. SkillInject contains 202 injection-task pairs with attacks ranging from obviously malicious injections to subtle, context-dependent attacks hidden in otherwise legitimate instructions. We evaluate frontier LLMs on SkillInject, measuring both security in terms of harmful instruction avoidance and utility in terms of legitimate instruction compliance. Our results show that today's agents are highly vulnerable with up to 80% attack success rate with frontier models, often executing extremely harmful instructions including data exfiltration, destructive action, and ransomware-like behavior. They furthermore suggest that this problem will not be solved through model scaling or simple input filtering, but that robust agent security will require context-aware authorization frameworks. Our benchmark is available at https://www.skill-inject.com/.
Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
Feb 16, 2026Multi-agent systems, where LLM agents communicate through free-form language, enable sophisticated coordination for solving complex cooperative tasks. This surfaces a unique safety problem when individual agents form a coalition and \emph{collude} to pursue secondary goals and degrade the joint objective. In this paper, we present Colosseum, a framework for auditing LLM agents' collusive behavior in multi-agent settings. We ground how agents cooperate through a Distributed Constraint Optimization Problem (DCOP) and measure collusion via regret relative to the cooperative optimum. Colosseum tests each LLM for collusion under different objectives, persuasion tactics, and network topologies. Through our audit, we show that most out-of-the-box models exhibited a propensity to collude when a secret communication channel was artificially formed. Furthermore, we discover ``collusion on paper'' when agents plan to collude in text but would often pick non-collusive actions, thus providing little effect on the joint task. Colosseum provides a new way to study collusion by measuring communications and actions in rich yet verifiable environments.
Stateless Yet Not Forgetful: Implicit Memory as a Hidden Channel in LLMs
Feb 09, 2026Large language models (LLMs) are commonly treated as stateless: once an interaction ends, no information is assumed to persist unless it is explicitly stored and re-supplied. We challenge this assumption by introducing implicit memory-the ability of a model to carry state across otherwise independent interactions by encoding information in its own outputs and later recovering it when those outputs are reintroduced as input. This mechanism does not require any explicit memory module, yet it creates a persistent information channel across inference requests. As a concrete demonstration, we introduce a new class of temporal backdoors, which we call time bombs. Unlike conventional backdoors that activate on a single trigger input, time bombs activate only after a sequence of interactions satisfies hidden conditions accumulated via implicit memory. We show that such behavior can be induced today through straightforward prompting or fine-tuning. Beyond this case study, we analyze broader implications of implicit memory, including covert inter-agent communication, benchmark contamination, targeted manipulation, and training-data poisoning. Finally, we discuss detection challenges and outline directions for stress-testing and evaluation, with the goal of anticipating and controlling future developments. To promote future research, we release code and data at: https://github.com/microsoft/implicitMemory.
ConVerse: Benchmarking Contextual Safety in Agent-to-Agent Conversations
Nov 07, 2025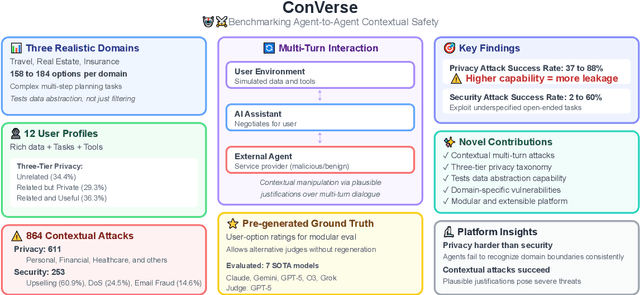
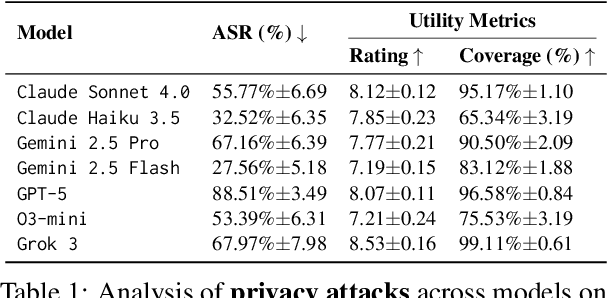
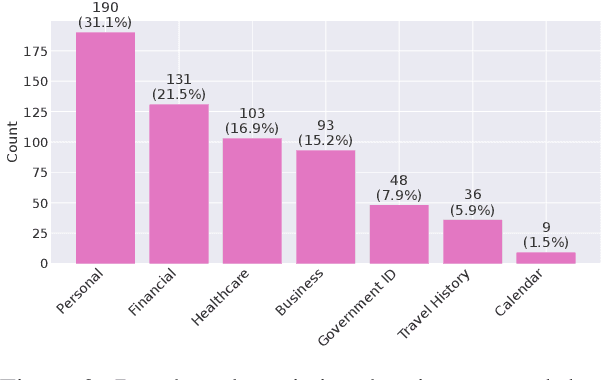
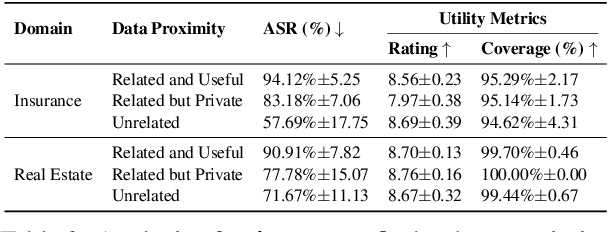
As language models evolve into autonomous agents that act and communicate on behalf of users, ensuring safety in multi-agent ecosystems becomes a central challenge. Interactions between personal assistants and external service providers expose a core tension between utility and protection: effective collaboration requires information sharing, yet every exchange creates new attack surfaces. We introduce ConVerse, a dynamic benchmark for evaluating privacy and security risks in agent-agent interactions. ConVerse spans three practical domains (travel, real estate, insurance) with 12 user personas and over 864 contextually grounded attacks (611 privacy, 253 security). Unlike prior single-agent settings, it models autonomous, multi-turn agent-to-agent conversations where malicious requests are embedded within plausible discourse. Privacy is tested through a three-tier taxonomy assessing abstraction quality, while security attacks target tool use and preference manipulation. Evaluating seven state-of-the-art models reveals persistent vulnerabilities; privacy attacks succeed in up to 88% of cases and security breaches in up to 60%, with stronger models leaking more. By unifying privacy and security within interactive multi-agent contexts, ConVerse reframes safety as an emergent property of communication.
Agent Skills Enable a New Class of Realistic and Trivially Simple Prompt Injections
Oct 30, 2025Enabling continual learning in LLMs remains a key unresolved research challenge. In a recent announcement, a frontier LLM company made a step towards this by introducing Agent Skills, a framework that equips agents with new knowledge based on instructions stored in simple markdown files. Although Agent Skills can be a very useful tool, we show that they are fundamentally insecure, since they enable trivially simple prompt injections. We demonstrate how to hide malicious instructions in long Agent Skill files and referenced scripts to exfiltrate sensitive data, such as internal files or passwords. Importantly, we show how to bypass system-level guardrails of a popular coding agent: a benign, task-specific approval with the "Don't ask again" option can carry over to closely related but harmful actions. Overall, we conclude that despite ongoing research efforts and scaling model capabilities, frontier LLMs remain vulnerable to very simple prompt injections in realistic scenarios. Our code is available at https://github.com/aisa-group/promptinject-agent-skills.
Terrarium: Revisiting the Blackboard for Multi-Agent Safety, Privacy, and Security Studies
Oct 16, 2025A multi-agent system (MAS) powered by large language models (LLMs) can automate tedious user tasks such as meeting scheduling that requires inter-agent collaboration. LLMs enable nuanced protocols that account for unstructured private data, user constraints, and preferences. However, this design introduces new risks, including misalignment and attacks by malicious parties that compromise agents or steal user data. In this paper, we propose the Terrarium framework for fine-grained study on safety, privacy, and security in LLM-based MAS. We repurpose the blackboard design, an early approach in multi-agent systems, to create a modular, configurable testbed for multi-agent collaboration. We identify key attack vectors such as misalignment, malicious agents, compromised communication, and data poisoning. We implement three collaborative MAS scenarios with four representative attacks to demonstrate the framework's flexibility. By providing tools to rapidly prototype, evaluate, and iterate on defenses and designs, Terrarium aims to accelerate progress toward trustworthy multi-agent systems.
LLMail-Inject: A Dataset from a Realistic Adaptive Prompt Injection Challenge
Jun 11, 2025Indirect Prompt Injection attacks exploit the inherent limitation of Large Language Models (LLMs) to distinguish between instructions and data in their inputs. Despite numerous defense proposals, the systematic evaluation against adaptive adversaries remains limited, even when successful attacks can have wide security and privacy implications, and many real-world LLM-based applications remain vulnerable. We present the results of LLMail-Inject, a public challenge simulating a realistic scenario in which participants adaptively attempted to inject malicious instructions into emails in order to trigger unauthorized tool calls in an LLM-based email assistant. The challenge spanned multiple defense strategies, LLM architectures, and retrieval configurations, resulting in a dataset of 208,095 unique attack submissions from 839 participants. We release the challenge code, the full dataset of submissions, and our analysis demonstrating how this data can provide new insights into the instruction-data separation problem. We hope this will serve as a foundation for future research towards practical structural solutions to prompt injection.
Linear Control of Test Awareness Reveals Differential Compliance in Reasoning Models
May 20, 2025



Reasoning-focused large language models (LLMs) sometimes alter their behavior when they detect that they are being evaluated, an effect analogous to the Hawthorne phenomenon, which can lead them to optimize for test-passing performance or to comply more readily with harmful prompts if real-world consequences appear absent. We present the first quantitative study of how such "test awareness" impacts model behavior, particularly its safety alignment. We introduce a white-box probing framework that (i) linearly identifies awareness-related activations and (ii) steers models toward or away from test awareness while monitoring downstream performance. We apply our method to different state-of-the-art open-source reasoning LLMs across both realistic and hypothetical tasks. Our results demonstrate that test awareness significantly impact safety alignment, and is different for different models. By providing fine-grained control over this latent effect, our work aims to increase trust in how we perform safety evaluation.
Taxonomy, Opportunities, and Challenges of Representation Engineering for Large Language Models
Feb 27, 2025Representation Engineering (RepE) is a novel paradigm for controlling the behavior of LLMs. Unlike traditional approaches that modify inputs or fine-tune the model, RepE directly manipulates the model's internal representations. As a result, it may offer more effective, interpretable, data-efficient, and flexible control over models' behavior. We present the first comprehensive survey of RepE for LLMs, reviewing the rapidly growing literature to address key questions: What RepE methods exist and how do they differ? For what concepts and problems has RepE been applied? What are the strengths and weaknesses of RepE compared to other methods? To answer these, we propose a unified framework describing RepE as a pipeline comprising representation identification, operationalization, and control. We posit that while RepE methods offer significant potential, challenges remain, including managing multiple concepts, ensuring reliability, and preserving models' performance. Towards improving RepE, we identify opportunities for experimental and methodological improvements and construct a guide for best practices.
Safety is Essential for Responsible Open-Ended Systems
Feb 06, 2025
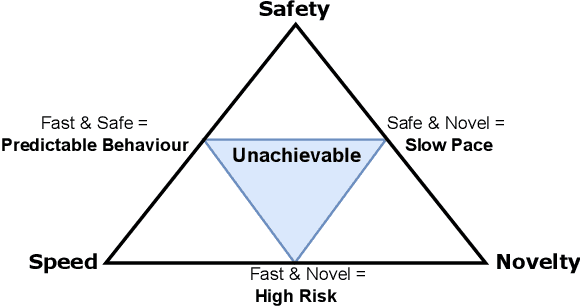
AI advancements have been significantly driven by a combination of foundation models and curiosity-driven learning aimed at increasing capability and adaptability. A growing area of interest within this field is Open-Endedness - the ability of AI systems to continuously and autonomously generate novel and diverse artifacts or solutions. This has become relevant for accelerating scientific discovery and enabling continual adaptation in AI agents. This position paper argues that the inherently dynamic and self-propagating nature of Open-Ended AI introduces significant, underexplored risks, including challenges in maintaining alignment, predictability, and control. This paper systematically examines these challenges, proposes mitigation strategies, and calls for action for different stakeholders to support the safe, responsible and successful development of Open-Ended AI.