 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Abnormalities in Zebrafish Development
May 11, 2026Zebrafish embryos are a valuable model for drug discovery due to their optical transparency and genetic similarity to humans. However, current evaluations rely on manual inspection, which is costly and labor-intensive. While machine learning offers automation potential, progress is limited by the lack of comprehensive datasets. To address this, we introduce a large-scale dataset of high-resolution microscopic image sequences capturing zebrafish embryonic development under both control conditions and exposure to compounds (3,4-dichloroaniline). This dataset, with expert annotations at fine-grained temporal levels, supports two benchmarking tasks: (1) fertility classification, assessing zebrafish egg viability (130,368 images), and (2) toxicity assessment, detecting malformations induced by toxic exposure over time (55,296 images). Alongside the dataset, we present the first transformer-based baseline model that integrates spatiotemporal features to predict developmental abnormalities at early stages. Experimental results present the model's effectiveness, achieving 98% accuracy in fertility classification and 92% in toxicity assessment. These findings underscore the potential of automated approaches to enhance zebrafish-based toxicity analysis.
COMIX: Compositional Explanations using Prototypes
Jan 10, 2025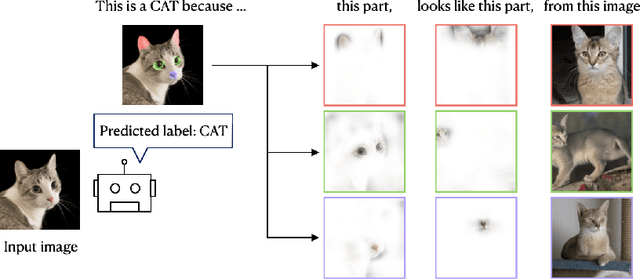

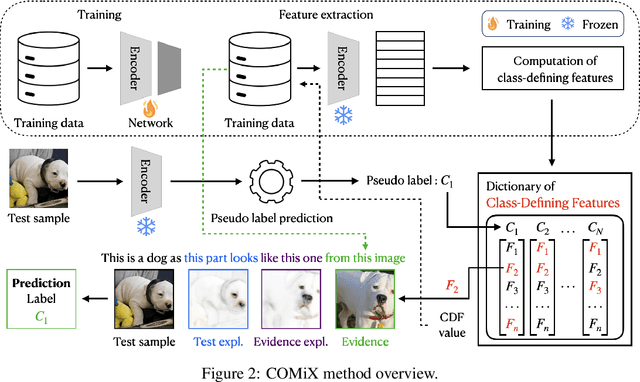
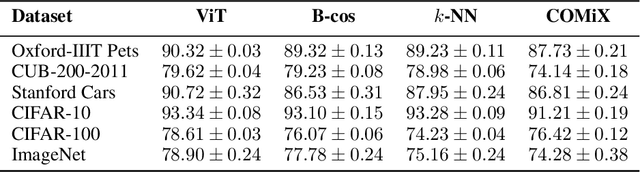
Aligning machine representations with human understanding is key to improving interpretability of machine learning (ML) models. When classifying a new image, humans often explain their decisions by decomposing the image into concepts and pointing to corresponding regions in familiar images. Current ML explanation techniques typically either trace decision-making processes to reference prototypes, generate attribution maps highlighting feature importance, or incorporate intermediate bottlenecks designed to align with human-interpretable concepts. The proposed method, named COMIX, classifies an image by decomposing it into regions based on learned concepts and tracing each region to corresponding ones in images from the training dataset, assuring that explanations fully represent the actual decision-making process. We dissect the test image into selected internal representations of a neural network to derive prototypical parts (primitives) and match them with the corresponding primitives derived from the training data. In a series of qualitative and quantitative experiments, we theoretically prove and demonstrate that our method, in contrast to post hoc analysis, provides fidelity of explanations and shows that the efficiency is competitive with other inherently interpretable architectures. Notably, it shows substantial improvements in fidelity and sparsity metrics, including 48.82% improvement in the C-insertion score on the ImageNet dataset over the best state-of-the-art baseline.
Exploring Value Biases: How LLMs Deviate Towards the Ideal
Feb 21, 2024



Large-Language-Models (LLMs) are deployed in a wide range of applications, and their response has an increasing social impact. Understanding the non-deliberate(ive) mechanism of LLMs in giving responses is essential in explaining their performance and discerning their biases in real-world applications. This is analogous to human studies, where such inadvertent responses are referred to as sampling. We study this sampling of LLMs in light of value bias and show that the sampling of LLMs tends to favour high-value options. Value bias corresponds to this shift of response from the most likely towards an ideal value represented in the LLM. In fact, this effect can be reproduced even with new entities learnt via in-context prompting. We show that this bias manifests in unexpected places and has implications on relevant application scenarios, like choosing exemplars. The results show that value bias is strong in LLMs across different categories, similar to the results found in human studies.
Going Beyond Familiar Features for Deep Anomaly Detection
Oct 01, 2023Anomaly Detection (AD) is a critical task that involves identifying observations that do not conform to a learned model of normality. Prior work in deep AD is predominantly based on a familiarity hypothesis, where familiar features serve as the reference in a pre-trained embedding space. While this strategy has proven highly successful, it turns out that it causes consistent false negatives when anomalies consist of truly novel features that are not well captured by the pre-trained encoding. We propose a novel approach to AD using explainability to capture novel features as unexplained observations in the input space. We achieve strong performance across a wide range of anomaly benchmarks by combining similarity and novelty in a hybrid approach. Our approach establishes a new state-of-the-art across multiple benchmarks, handling diverse anomaly types while eliminating the need for expensive background models and dense matching. In particular, we show that by taking account of novel features, we reduce false negative anomalies by up to 40% on challenging benchmarks compared to the state-of-the-art. Our method gives visually inspectable explanations for pixel-level anomalies.
LLM-Deliberation: Evaluating LLMs with Interactive Multi-Agent Negotiation Games
Sep 29, 2023



There is a growing interest in using Large Language Models (LLMs) as agents to tackle real-world tasks that may require assessing complex situations. Yet, we have a limited understanding of LLMs' reasoning and decision-making capabilities, partly stemming from a lack of dedicated evaluation benchmarks. As negotiating and compromising are key aspects of our everyday communication and collaboration, we propose using scorable negotiation games as a new evaluation framework for LLMs. We create a testbed of diverse text-based, multi-agent, multi-issue, semantically rich negotiation games, with easily tunable difficulty. To solve the challenge, agents need to have strong arithmetic, inference, exploration, and planning capabilities, while seamlessly integrating them. Via a systematic zero-shot Chain-of-Thought prompting (CoT), we show that agents can negotiate and consistently reach successful deals. We quantify the performance with multiple metrics and observe a large gap between GPT-4 and earlier models. Importantly, we test the generalization to new games and setups. Finally, we show that these games can help evaluate other critical aspects, such as the interaction dynamics between agents in the presence of greedy and adversarial players.
I Know Therefore I Score: Label-Free Crafting of Scoring Functions using Constraints Based on Domain Expertise
Mar 18, 2022
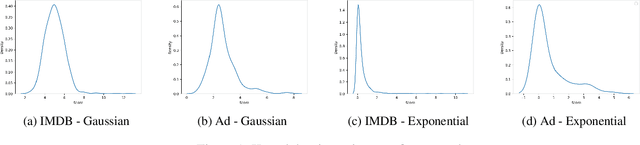
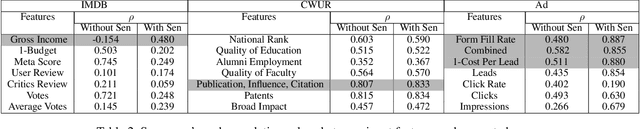

Several real-life applications require crafting concise, quantitative scoring functions (also called rating systems) from measured observations. For example, an effectiveness score needs to be created for advertising campaigns using a number of engagement metrics. Experts often need to create such scoring functions in the absence of labelled data, where the scores need to reflect business insights and rules as understood by the domain experts. Without a way to capture these inputs systematically, this becomes a time-consuming process involving trial and error. In this paper, we introduce a label-free practical approach to learn a scoring function from multi-dimensional numerical data. The approach incorporates insights and business rules from domain experts in the form of easily observable and specifiable constraints, which are used as weak supervision by a machine learning model. We convert such constraints into loss functions that are optimized simultaneously while learning the scoring function. We examine the efficacy of the approach using a synthetic dataset as well as four real-life datasets, and also compare how it performs vis-a-vis supervised learning models.
Emotional Prosody Control for Speech Generation
Nov 07, 2021
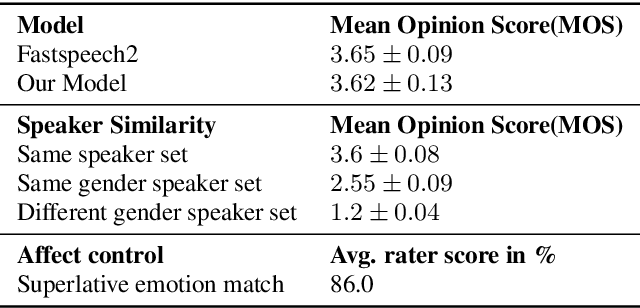
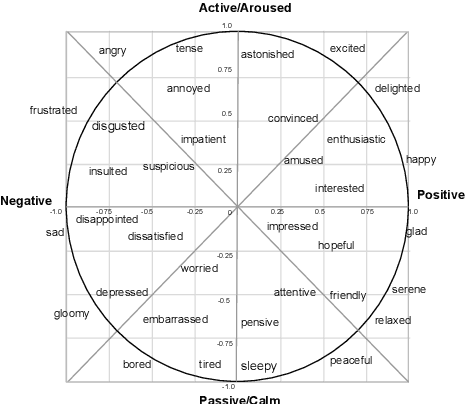
Machine-generated speech is characterized by its limited or unnatural emotional variation. Current text to speech systems generates speech with either a flat emotion, emotion selected from a predefined set, average variation learned from prosody sequences in training data or transferred from a source style. We propose a text to speech(TTS) system, where a user can choose the emotion of generated speech from a continuous and meaningful emotion space (Arousal-Valence space). The proposed TTS system can generate speech from the text in any speaker's style, with fine control of emotion. We show that the system works on emotion unseen during training and can scale to previously unseen speakers given his/her speech sample. Our work expands the horizon of the state-of-the-art FastSpeech2 backbone to a multi-speaker setting and gives it much-coveted continuous (and interpretable) affective control, without any observable degradation in the quality of the synthesized speech.
Reappraising Domain Generalization in Neural Networks
Oct 15, 2021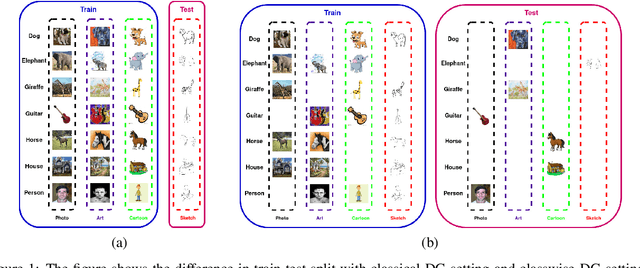


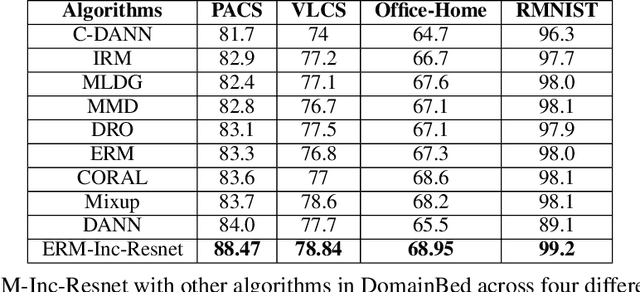
Domain generalization (DG) of machine learning algorithms is defined as their ability to learn a domain agnostic hypothesis from multiple training distributions, which generalizes onto data from an unseen domain. DG is vital in scenarios where the target domain with distinct characteristics has sparse data for training. Aligning with recent work~\cite{gulrajani2020search}, we find that a straightforward Empirical Risk Minimization (ERM) baseline consistently outperforms existing DG methods. We present ablation studies indicating that the choice of backbone, data augmentation, and optimization algorithms overshadows the many tricks and trades explored in the prior art. Our work leads to a new state of the art on the four popular DG datasets, surpassing previous methods by large margins. Furthermore, as a key contribution, we propose a classwise-DG formulation, where for each class, we randomly select one of the domains and keep it aside for testing. We argue that this benchmarking is closer to human learning and relevant in real-world scenarios. We comprehensively benchmark classwise-DG on the DomainBed and propose a method combining ERM and reverse gradients to achieve the state-of-the-art results. To our surprise, despite being exposed to all domains during training, the classwise DG is more challenging than traditional DG evaluation and motivates more fundamental rethinking on the problem of DG.
The Curious Case of Convex Networks
Jun 09, 2020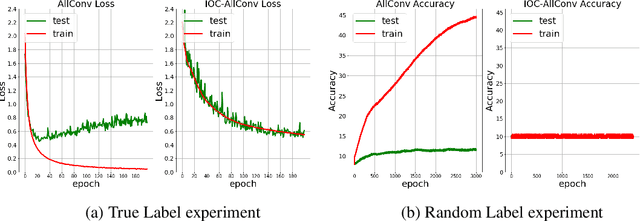

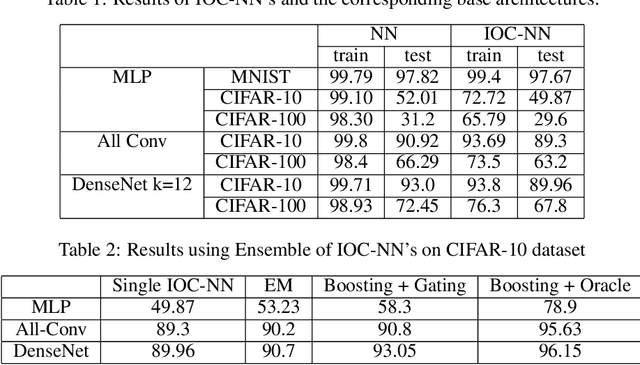
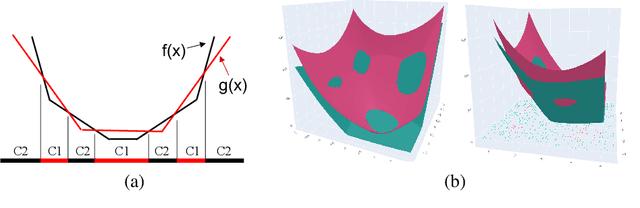
In this paper, we investigate a constrained formulation of neural networks where the output is a convex function of the input. We show that the convexity constraints can be enforced on both fully connected and convolutional layers, making them applicable to most architectures. The convexity constraints include restricting the weights (for all but the first layer) to be non-negative and using a non-decreasing convex activation function. Albeit simple, these constraints have profound implications on the generalization abilities of the network. We draw three valuable insights: (a) Input Output Convex Networks (IOC-NN) self regularize and almost uproot the problem of overfitting; (b) Although heavily constrained, they come close to the performance of the base architectures; and (c) The ensemble of convex networks can match or outperform the non convex counterparts. We demonstrate the efficacy of the proposed idea using thorough experiments and ablation studies on MNIST, CIFAR10, and CIFAR100 datasets with three different neural network architectures. The code for this project is publicly available at: \url{https://github.com/sarathsp1729/Convex-Networks}.