 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConVerse: Benchmarking Contextual Safety in Agent-to-Agent Conversations
Nov 07, 2025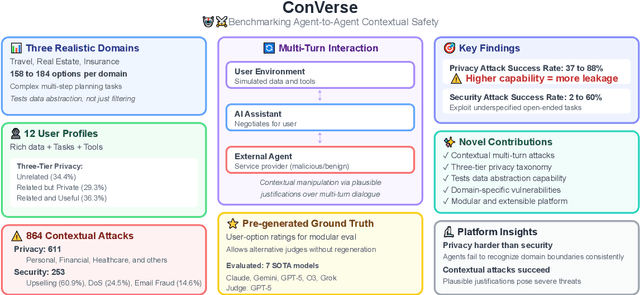
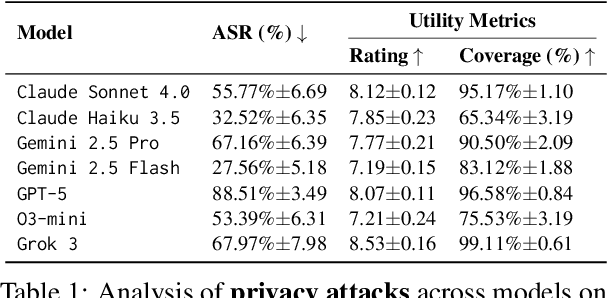
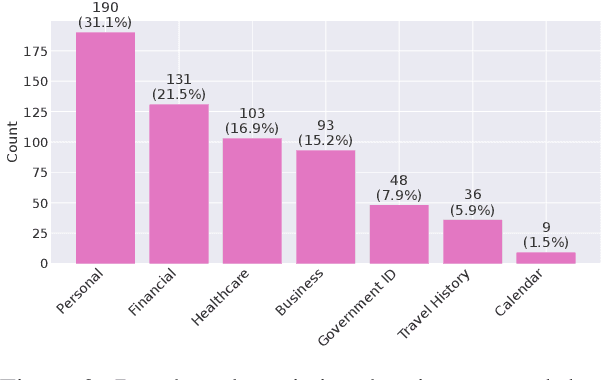
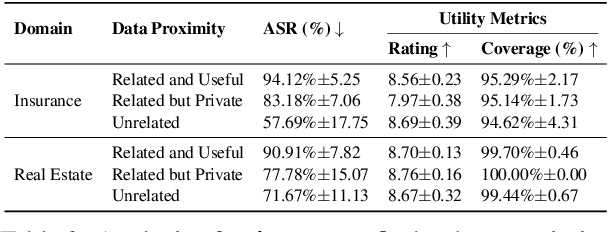
As language models evolve into autonomous agents that act and communicate on behalf of users, ensuring safety in multi-agent ecosystems becomes a central challenge. Interactions between personal assistants and external service providers expose a core tension between utility and protection: effective collaboration requires information sharing, yet every exchange creates new attack surfaces. We introduce ConVerse, a dynamic benchmark for evaluating privacy and security risks in agent-agent interactions. ConVerse spans three practical domains (travel, real estate, insurance) with 12 user personas and over 864 contextually grounded attacks (611 privacy, 253 security). Unlike prior single-agent settings, it models autonomous, multi-turn agent-to-agent conversations where malicious requests are embedded within plausible discourse. Privacy is tested through a three-tier taxonomy assessing abstraction quality, while security attacks target tool use and preference manipulation. Evaluating seven state-of-the-art models reveals persistent vulnerabilities; privacy attacks succeed in up to 88% of cases and security breaches in up to 60%, with stronger models leaking more. By unifying privacy and security within interactive multi-agent contexts, ConVerse reframes safety as an emergent property of communication.
Predicting Human Behavior in Autonomous Systems: A Collaborative Machine Teaching Approach for Reducing Transfer of Control Events
May 15, 2025



As autonomous systems become integral to various industries, effective strategies for fault handling are essential to ensure reliability and efficiency. Transfer of Control (ToC), a traditional approach for interrupting automated processes during faults, is often triggered unnecessarily in non-critical situations. To address this, we propose a data-driven method that uses human interaction data to train AI models capable of preemptively identifying and addressing issues or assisting users in resolution. Using an interactive tool simulating an industrial vacuum cleaner, we collected data and developed an LSTM-based model to predict user behavior. Our findings reveal that even data from non-experts can effectively train models to reduce unnecessary ToC events, enhancing the system's robustness. This approach highlights the potential of AI to learn directly from human problem-solving behaviors, complementing sensor data to improve industrial automation and human-AI collaboration.
Unveiling the Role of Expert Guidance: A Comparative Analysis of User-centered Imitation Learning and Traditional Reinforcement Learning
Oct 28, 2024



Integration of human feedback plays a key role in improving the learning capabilities of intelligent systems. This comparative study delves into the performance, robustness, and limitations of imitation learning compared to traditional reinforcement learning methods within these systems. Recognizing the value of human-in-the-loop feedback, we investigate the influence of expert guidance and suboptimal demonstrations on the learning process. Through extensive experimentation and evaluations conducted in a pre-existing simulation environment using the Unity platform, we meticulously analyze the effectiveness and limitations of these learning approaches. The insights gained from this study contribute to the advancement of human-centered artificial intelligence by highlighting the benefits and challenges associated with the incorporation of human feedback into the learning process. Ultimately, this research promotes the development of models that can effectively address complex real-world problems.
AdaptoML-UX: An Adaptive User-centered GUI-based AutoML Toolkit for Non-AI Experts and HCI Researchers
Oct 22, 2024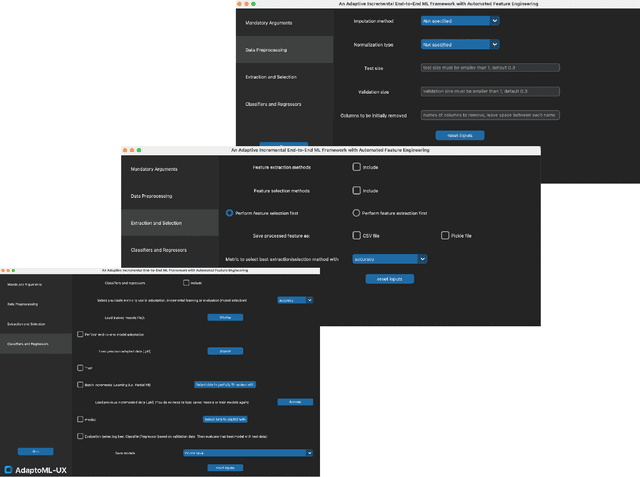
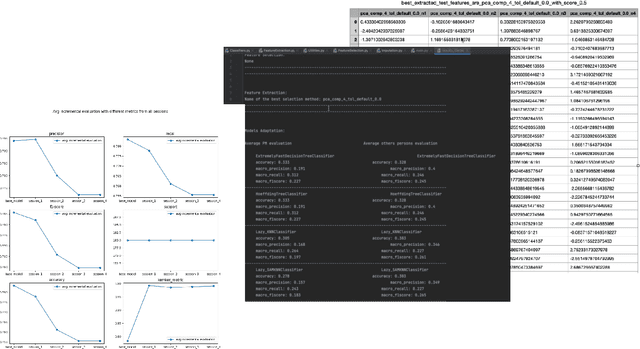
The increasing integration of machine learning across various domains has underscored the necessity for accessible systems that non-experts can utilize effectively. To address this need, the field of automated machine learning (AutoML) has developed tools to simplify the construction and optimization of ML pipelines. However, existing AutoML solutions often lack efficiency in creating online pipelines and ease of use for Human-Computer Interaction (HCI) applications. Therefore, in this paper, we introduce AdaptoML-UX, an adaptive framework that incorporates automated feature engineering, machine learning, and incremental learning to assist non-AI experts in developing robust, user-centered ML models. Our toolkit demonstrates the capability to adapt efficiently to diverse problem domains and datasets, particularly in HCI, thereby reducing the necessity for manual experimentation and conserving time and resources. Furthermore, it supports model personalization through incremental learning, customizing models to individual user behaviors. HCI researchers can employ AdaptoML-UX (\url{https://github.com/MichaelSargious/AdaptoML_UX}) without requiring specialized expertise, as it automates the selection of algorithms, feature engineering, and hyperparameter tuning based on the unique characteristics of the data.
Looking for a better fit? An Incremental Learning Multimodal Object Referencing Framework adapting to Individual Drivers
Feb 07, 2024
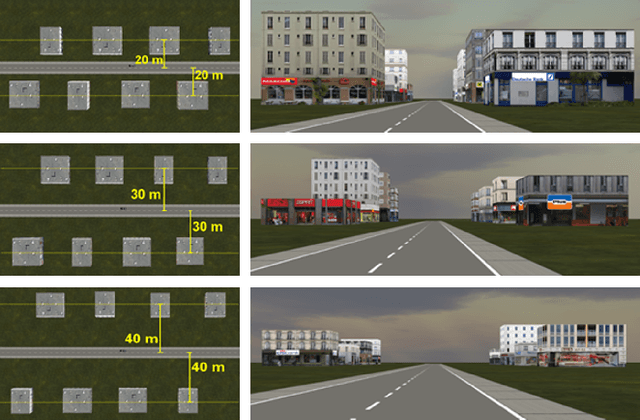


The rapid advancement of the automotive industry towards automated and semi-automated vehicles has rendered traditional methods of vehicle interaction, such as touch-based and voice command systems, inadequate for a widening range of non-driving related tasks, such as referencing objects outside of the vehicle. Consequently, research has shifted toward gestural input (e.g., hand, gaze, and head pose gestures) as a more suitable mode of interaction during driving. However, due to the dynamic nature of driving and individual variation, there are significant differences in drivers' gestural input performance. While, in theory, this inherent variability could be moderated by substantial data-driven machine learning models, prevalent methodologies lean towards constrained, single-instance trained models for object referencing. These models show a limited capacity to continuously adapt to the divergent behaviors of individual drivers and the variety of driving scenarios. To address this, we propose \textit{IcRegress}, a novel regression-based incremental learning approach that adapts to changing behavior and the unique characteristics of drivers engaged in the dual task of driving and referencing objects. We suggest a more personalized and adaptable solution for multimodal gestural interfaces, employing continuous lifelong learning to enhance driver experience, safety, and convenience. Our approach was evaluated using an outside-the-vehicle object referencing use case, highlighting the superiority of the incremental learning models adapted over a single trained model across various driver traits such as handedness, driving experience, and numerous driving conditions. Finally, to facilitate reproducibility, ease deployment, and promote further research, we offer our approach as an open-source framework at \url{https://github.com/amrgomaaelhady/IcRegress}.
Toward a Surgeon-in-the-Loop Ophthalmic Robotic Apprentice using Reinforcement and Imitation Learning
Nov 29, 2023


Robotic-assisted surgical systems have demonstrated significant potential in enhancing surgical precision and minimizing human errors. However, existing systems lack the ability to accommodate the unique preferences and requirements of individual surgeons. Additionally, they primarily focus on general surgeries (e.g., laparoscopy) and are not suitable for highly precise microsurgeries, such as ophthalmic procedures. Thus, we propose a simulation-based image-guided approach for surgeon-centered autonomous agents that can adapt to the individual surgeon's skill level and preferred surgical techniques during ophthalmic cataract surgery. Our approach utilizes a simulated environment to train reinforcement and imitation learning agents guided by image data to perform all tasks of the incision phase of cataract surgery. By integrating the surgeon's actions and preferences into the training process with the surgeon-in-the-loop, our approach enables the robot to implicitly learn and adapt to the individual surgeon's unique approach through demonstrations. This results in a more intuitive and personalized surgical experience for the surgeon. Simultaneously, it ensures consistent performance for the autonomous robotic apprentice. We define and evaluate the effectiveness of our approach using our proposed metrics; and highlight the trade-off between a generic agent and a surgeon-centered adapted agent. Moreover, our approach has the potential to extend to other ophthalmic surgical procedures, opening the door to a new generation of surgeon-in-the-loop autonomous surgical robots. We provide an open-source simulation framework for future development and reproducibility.
It's all about you: Personalized in-Vehicle Gesture Recognition with a Time-of-Flight Camera
Oct 02, 2023



Despite significant advances in gesture recognition technology, recognizing gestures in a driving environment remains challenging due to limited and costly data and its dynamic, ever-changing nature. In this work, we propose a model-adaptation approach to personalize the training of a CNNLSTM model and improve recognition accuracy while reducing data requirements. Our approach contributes to the field of dynamic hand gesture recognition while driving by providing a more efficient and accurate method that can be customized for individual users, ultimately enhancing the safety and convenience of in-vehicle interactions, as well as driver's experience and system trust. We incorporate hardware enhancement using a time-of-flight camera and algorithmic enhancement through data augmentation, personalized adaptation, and incremental learning techniques. We evaluate the performance of our approach in terms of recognition accuracy, achieving up to 90\%, and show the effectiveness of personalized adaptation and incremental learning for a user-centered design.
LLM-Deliberation: Evaluating LLMs with Interactive Multi-Agent Negotiation Games
Sep 29, 2023



There is a growing interest in using Large Language Models (LLMs) as agents to tackle real-world tasks that may require assessing complex situations. Yet, we have a limited understanding of LLMs' reasoning and decision-making capabilities, partly stemming from a lack of dedicated evaluation benchmarks. As negotiating and compromising are key aspects of our everyday communication and collaboration, we propose using scorable negotiation games as a new evaluation framework for LLMs. We create a testbed of diverse text-based, multi-agent, multi-issue, semantically rich negotiation games, with easily tunable difficulty. To solve the challenge, agents need to have strong arithmetic, inference, exploration, and planning capabilities, while seamlessly integrating them. Via a systematic zero-shot Chain-of-Thought prompting (CoT), we show that agents can negotiate and consistently reach successful deals. We quantify the performance with multiple metrics and observe a large gap between GPT-4 and earlier models. Importantly, we test the generalization to new games and setups. Finally, we show that these games can help evaluate other critical aspects, such as the interaction dynamics between agents in the presence of greedy and adversarial players.
Adaptive User-centered Neuro-symbolic Learning for Multimodal Interaction with Autonomous Systems
Sep 11, 2023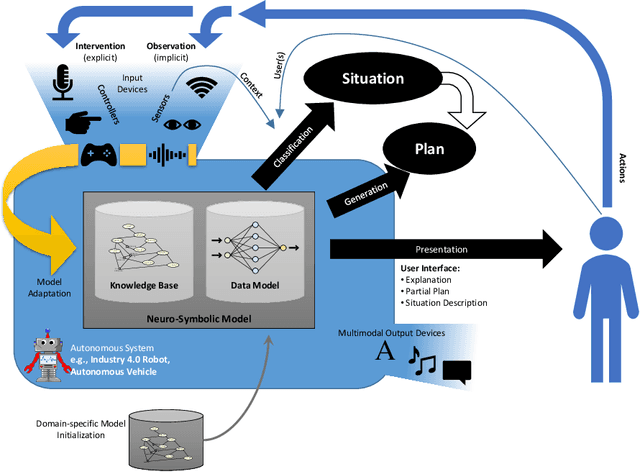
Recent advances in machine learning, particularly deep learning, have enabled autonomous systems to perceive and comprehend objects and their environments in a perceptual subsymbolic manner. These systems can now perform object detection, sensor data fusion, and language understanding tasks. However, there is a growing need to enhance these systems to understand objects and their environments more conceptually and symbolically. It is essential to consider both the explicit teaching provided by humans (e.g., describing a situation or explaining how to act) and the implicit teaching obtained by observing human behavior (e.g., through the system's sensors) to achieve this level of powerful artificial intelligence. Thus, the system must be designed with multimodal input and output capabilities to support implicit and explicit interaction models. In this position paper, we argue for considering both types of inputs, as well as human-in-the-loop and incremental learning techniques, for advancing the field of artificial intelligence and enabling autonomous systems to learn like humans. We propose several hypotheses and design guidelines and highlight a use case from related work to achieve this goal.
SynthoGestures: A Novel Framework for Synthetic Dynamic Hand Gesture Generation for Driving Scenarios
Sep 08, 2023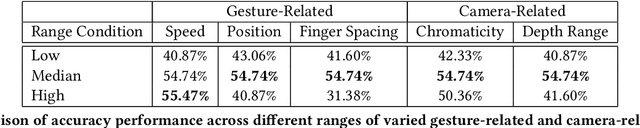
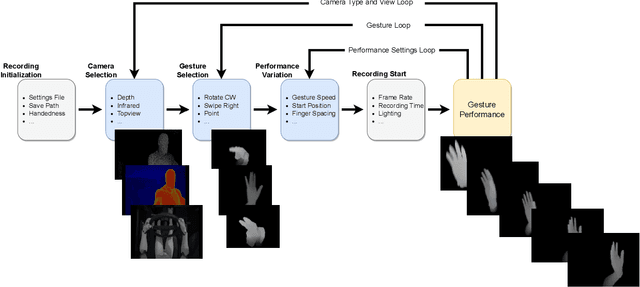

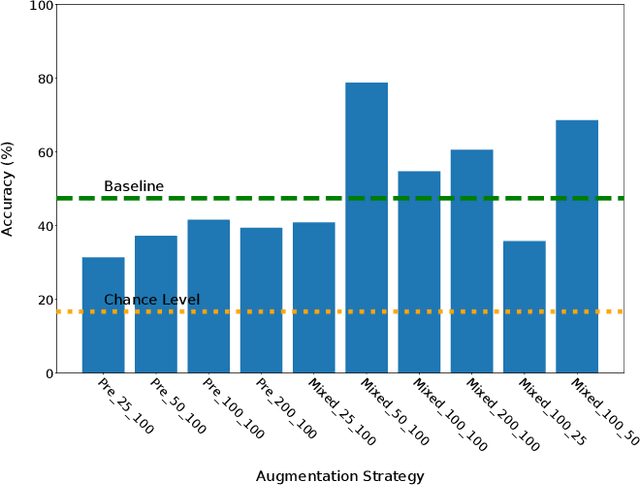
Creating a diverse and comprehensive dataset of hand gestures for dynamic human-machine interfaces in the automotive domain can be challenging and time-consuming. To overcome this challenge, we propose using synthetic gesture datasets generated by virtual 3D models. Our framework utilizes Unreal Engine to synthesize realistic hand gestures, offering customization options and reducing the risk of overfitting. Multiple variants, including gesture speed, performance, and hand shape, are generated to improve generalizability. In addition, we simulate different camera locations and types, such as RGB, infrared, and depth cameras, without incurring additional time and cost to obtain these cameras. Experimental results demonstrate that our proposed framework, SynthoGestures\footnote{\url{https://github.com/amrgomaaelhady/SynthoGestures}}, improves gesture recognition accuracy and can replace or augment real-hand datasets. By saving time and effort in the creation of the data set, our tool accelerates the development of gesture recognition systems for automotive applications.