 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
AdaptoML-UX: An Adaptive User-centered GUI-based AutoML Toolkit for Non-AI Experts and HCI Researchers
Oct 22, 2024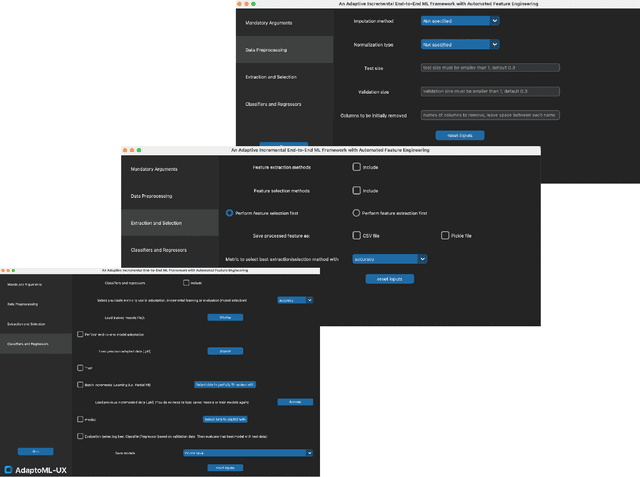
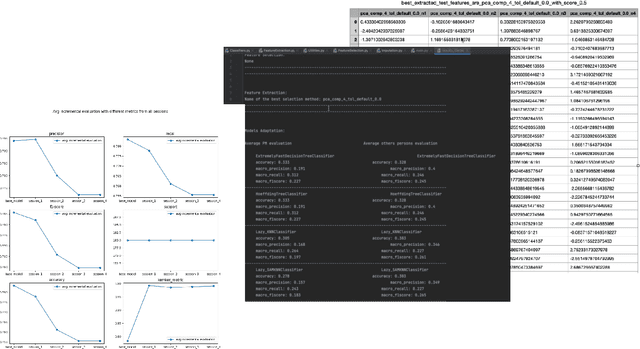
The increasing integration of machine learning across various domains has underscored the necessity for accessible systems that non-experts can utilize effectively. To address this need, the field of automated machine learning (AutoML) has developed tools to simplify the construction and optimization of ML pipelines. However, existing AutoML solutions often lack efficiency in creating online pipelines and ease of use for Human-Computer Interaction (HCI) applications. Therefore, in this paper, we introduce AdaptoML-UX, an adaptive framework that incorporates automated feature engineering, machine learning, and incremental learning to assist non-AI experts in developing robust, user-centered ML models. Our toolkit demonstrates the capability to adapt efficiently to diverse problem domains and datasets, particularly in HCI, thereby reducing the necessity for manual experimentation and conserving time and resources. Furthermore, it supports model personalization through incremental learning, customizing models to individual user behaviors. HCI researchers can employ AdaptoML-UX (\url{https://github.com/MichaelSargious/AdaptoML_UX}) without requiring specialized expertise, as it automates the selection of algorithms, feature engineering, and hyperparameter tuning based on the unique characteristics of the data.
Looking for a better fit? An Incremental Learning Multimodal Object Referencing Framework adapting to Individual Drivers
Feb 07, 2024
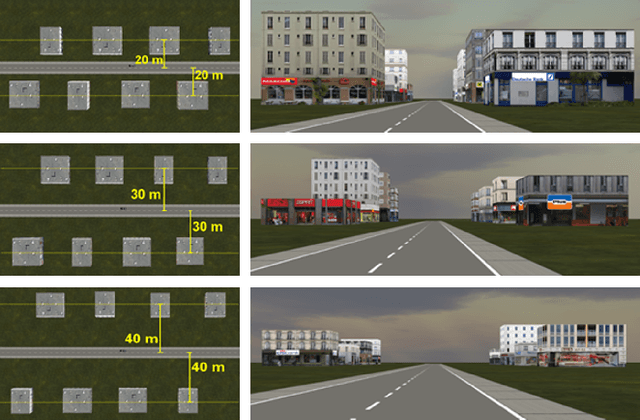


The rapid advancement of the automotive industry towards automated and semi-automated vehicles has rendered traditional methods of vehicle interaction, such as touch-based and voice command systems, inadequate for a widening range of non-driving related tasks, such as referencing objects outside of the vehicle. Consequently, research has shifted toward gestural input (e.g., hand, gaze, and head pose gestures) as a more suitable mode of interaction during driving. However, due to the dynamic nature of driving and individual variation, there are significant differences in drivers' gestural input performance. While, in theory, this inherent variability could be moderated by substantial data-driven machine learning models, prevalent methodologies lean towards constrained, single-instance trained models for object referencing. These models show a limited capacity to continuously adapt to the divergent behaviors of individual drivers and the variety of driving scenarios. To address this, we propose \textit{IcRegress}, a novel regression-based incremental learning approach that adapts to changing behavior and the unique characteristics of drivers engaged in the dual task of driving and referencing objects. We suggest a more personalized and adaptable solution for multimodal gestural interfaces, employing continuous lifelong learning to enhance driver experience, safety, and convenience. Our approach was evaluated using an outside-the-vehicle object referencing use case, highlighting the superiority of the incremental learning models adapted over a single trained model across various driver traits such as handedness, driving experience, and numerous driving conditions. Finally, to facilitate reproducibility, ease deployment, and promote further research, we offer our approach as an open-source framework at \url{https://github.com/amrgomaaelhady/IcRegress}.
Toward a Surgeon-in-the-Loop Ophthalmic Robotic Apprentice using Reinforcement and Imitation Learning
Nov 29, 2023


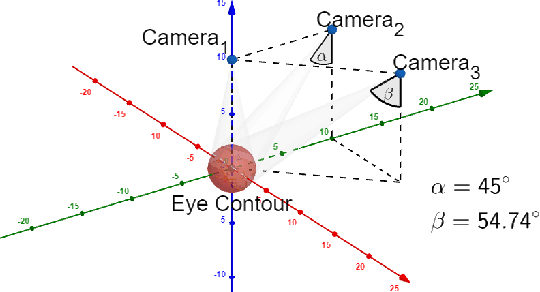
Robotic-assisted surgical systems have demonstrated significant potential in enhancing surgical precision and minimizing human errors. However, existing systems lack the ability to accommodate the unique preferences and requirements of individual surgeons. Additionally, they primarily focus on general surgeries (e.g., laparoscopy) and are not suitable for highly precise microsurgeries, such as ophthalmic procedures. Thus, we propose a simulation-based image-guided approach for surgeon-centered autonomous agents that can adapt to the individual surgeon's skill level and preferred surgical techniques during ophthalmic cataract surgery. Our approach utilizes a simulated environment to train reinforcement and imitation learning agents guided by image data to perform all tasks of the incision phase of cataract surgery. By integrating the surgeon's actions and preferences into the training process with the surgeon-in-the-loop, our approach enables the robot to implicitly learn and adapt to the individual surgeon's unique approach through demonstrations. This results in a more intuitive and personalized surgical experience for the surgeon. Simultaneously, it ensures consistent performance for the autonomous robotic apprentice. We define and evaluate the effectiveness of our approach using our proposed metrics; and highlight the trade-off between a generic agent and a surgeon-centered adapted agent. Moreover, our approach has the potential to extend to other ophthalmic surgical procedures, opening the door to a new generation of surgeon-in-the-loop autonomous surgical robots. We provide an open-source simulation framework for future development and reproducibility.
SynthoGestures: A Novel Framework for Synthetic Dynamic Hand Gesture Generation for Driving Scenarios
Sep 08, 2023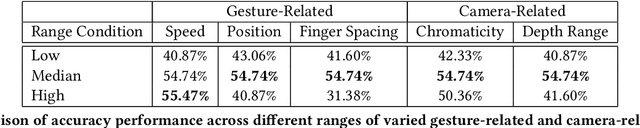
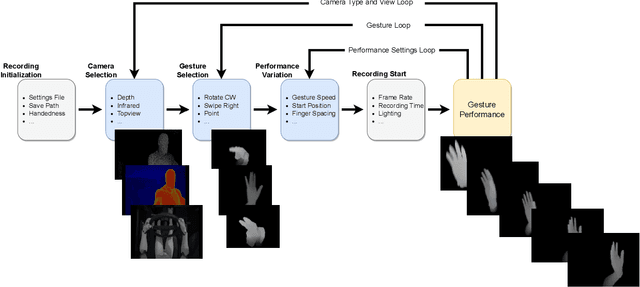

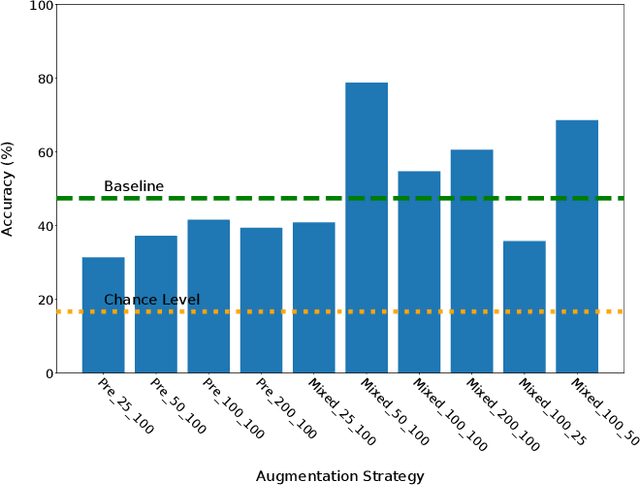
Creating a diverse and comprehensive dataset of hand gestures for dynamic human-machine interfaces in the automotive domain can be challenging and time-consuming. To overcome this challenge, we propose using synthetic gesture datasets generated by virtual 3D models. Our framework utilizes Unreal Engine to synthesize realistic hand gestures, offering customization options and reducing the risk of overfitting. Multiple variants, including gesture speed, performance, and hand shape, are generated to improve generalizability. In addition, we simulate different camera locations and types, such as RGB, infrared, and depth cameras, without incurring additional time and cost to obtain these cameras. Experimental results demonstrate that our proposed framework, SynthoGestures\footnote{\url{https://github.com/amrgomaaelhady/SynthoGestures}}, improves gesture recognition accuracy and can replace or augment real-hand datasets. By saving time and effort in the creation of the data set, our tool accelerates the development of gesture recognition systems for automotive applications.
Teach Me How to Learn: A Perspective Review towards User-centered Neuro-symbolic Learning for Robotic Surgical Systems
Jul 07, 2023Recent advances in machine learning models allowed robots to identify objects on a perceptual nonsymbolic level (e.g., through sensor fusion and natural language understanding). However, these primarily black-box learning models still lack interpretation and transferability and require high data and computational demand. An alternative solution is to teach a robot on both perceptual nonsymbolic and conceptual symbolic levels through hybrid neurosymbolic learning approaches with expert feedback (i.e., human-in-the-loop learning). This work proposes a concept for this user-centered hybrid learning paradigm that focuses on robotic surgical situations. While most recent research focused on hybrid learning for non-robotic and some generic robotic domains, little work focuses on surgical robotics. We survey this related research while focusing on human-in-the-loop surgical robotic systems. This evaluation highlights the most prominent solutions for autonomous surgical robots and the challenges surgeons face when interacting with these systems. Finally, we envision possible ways to address these challenges using online apprenticeship learning based on implicit and explicit feedback from expert surgeons.
Integrating Artificial and Human Intelligence for Efficient Translation
Mar 07, 2019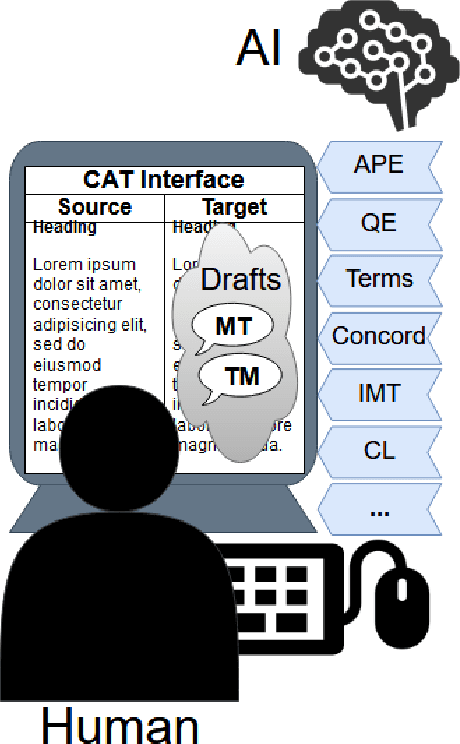
Current advances in machine translation increase the need for translators to switch from traditional translation to post-editing of machine-translated text, a process that saves time and improves quality. Human and artificial intelligence need to be integrated in an efficient way to leverage the advantages of both for the translation task. This paper outlines approaches at this boundary of AI and HCI and discusses open research questions to further advance the field.