 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Transference Architecture for Automatic Post-Editing
Aug 26, 2019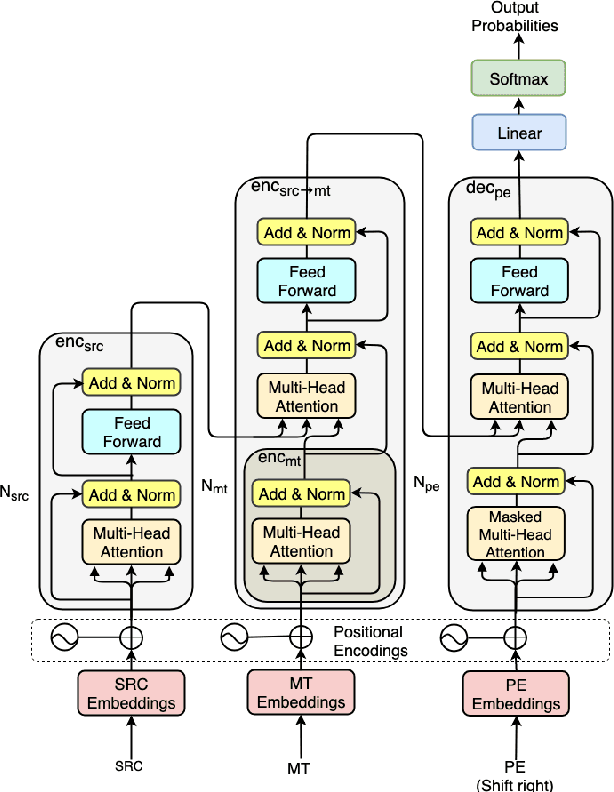
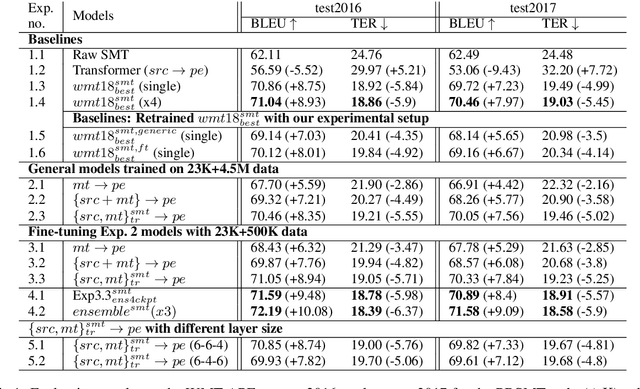
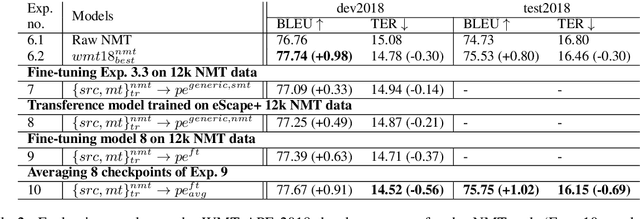
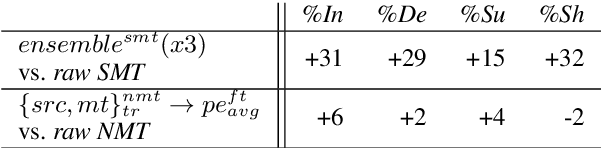
In automatic post-editing (APE) it makes sense to condition post-editing (pe) decisions on both the source (src) and the machine translated text (mt) as input. This has led to multi-source encoder based APE approaches. A research challenge now is the search for architectures that best support the capture, preparation and provision of src and mt information and its integration with pe decisions. In this paper we present a new multi-source APE model, called transference. Unlike previous approaches, it (i) uses a transformer encoder block for src, (ii) followed by a decoder block, but without masking for self-attention on mt, which effectively acts as second encoder combining src -> mt, and (iii) feeds this representation into a final decoder block generating pe. Our model outperforms the state-of-the-art by 1 BLEU point on the WMT 2016, 2017, and 2018 English--German APE shared tasks (PBSMT and NMT). We further investigate the importance of our newly introduced second encoder and find that a too small amount of layers does hurt the performance, while reducing the number of layers of the decoder does not matter much.
Integrating Artificial and Human Intelligence for Efficient Translation
Mar 07, 2019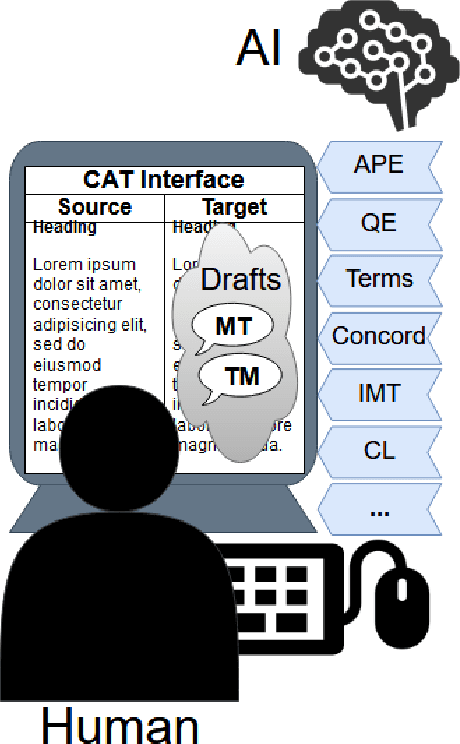
Current advances in machine translation increase the need for translators to switch from traditional translation to post-editing of machine-translated text, a process that saves time and improves quality. Human and artificial intelligence need to be integrated in an efficient way to leverage the advantages of both for the translation task. This paper outlines approaches at this boundary of AI and HCI and discusses open research questions to further advance the field.