 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scratch to Fine-Tuned: A Comparative Study of Transformer Training Strategies for Legal Machine Translation
Dec 21, 2025In multilingual nations like India, access to legal information is often hindered by language barriers, as much of the legal and judicial documentation remains in English. Legal Machine Translation (L-MT) offers a scalable solution to this challenge by enabling accurate and accessible translations of legal documents. This paper presents our work for the JUST-NLP 2025 Legal MT shared task, focusing on English-Hindi translation using Transformer-based approaches. We experiment with 2 complementary strategies, fine-tuning a pre-trained OPUS-MT model for domain-specific adaptation and training a Transformer model from scratch using the provided legal corpus. Performance is evaluated using standard MT metrics, including SacreBLEU, chrF++, TER, ROUGE, BERTScore, METEOR, and COMET. Our fine-tuned OPUS-MT model achieves a SacreBLEU score of 46.03, significantly outperforming both baseline and from-scratch models. The results highlight the effectiveness of domain adaptation in enhancing translation quality and demonstrate the potential of L-MT systems to improve access to justice and legal transparency in multilingual contexts.
MiMIC: Multi-Modal Indian Earnings Calls Dataset to Predict Stock Prices
Apr 12, 2025


Predicting stock market prices following corporate earnings calls remains a significant challenge for investors and researchers alike, requiring innovative approaches that can process diverse information sources. This study investigates the impact of corporate earnings calls on stock prices by introducing a multi-modal predictive model. We leverage textual data from earnings call transcripts, along with images and tables from accompanying presentations, to forecast stock price movements on the trading day immediately following these calls. To facilitate this research, we developed the MiMIC (Multi-Modal Indian Earnings Calls) dataset, encompassing companies representing the Nifty 50, Nifty MidCap 50, and Nifty Small 50 indices. The dataset includes earnings call transcripts, presentations, fundamentals, technical indicators, and subsequent stock prices. We present a multimodal analytical framework that integrates quantitative variables with predictive signals derived from textual and visual modalities, thereby enabling a holistic approach to feature representation and analysis. This multi-modal approach demonstrates the potential for integrating diverse information sources to enhance financial forecasting accuracy. To promote further research in computational economics, we have made the MiMIC dataset publicly available under the CC-NC-SA-4.0 licence. Our work contributes to the growing body of literature on market reactions to corporate communications and highlights the efficacy of multi-modal machine learning techniques in financial analysis.
Unified Graph Networks (UGN): A Deep Neural Framework for Solving Graph Problems
Feb 11, 2025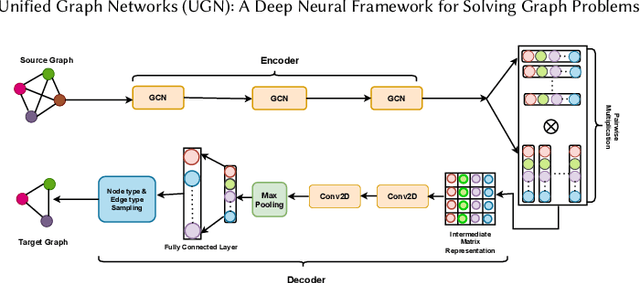
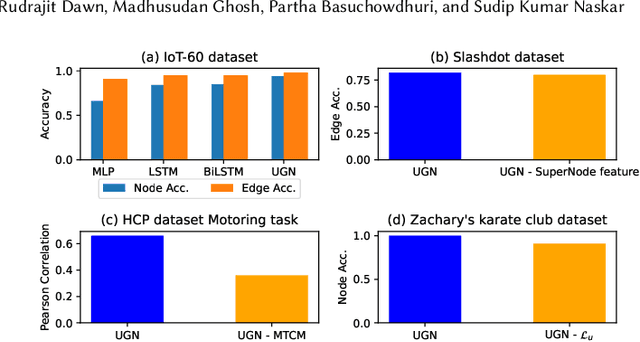
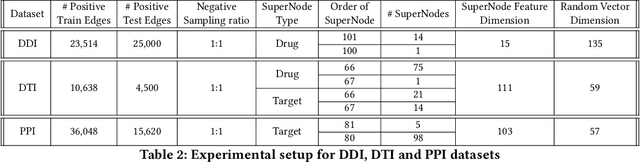
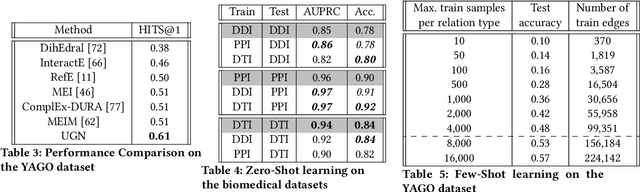
Deep neural networks have enabled researchers to create powerful generalized frameworks, such as transformers, that can be used to solve well-studied problems in various application domains, such as text and image. However, such generalized frameworks are not available for solving graph problems. Graph structures are ubiquitous in many applications around us and many graph problems have been widely studied over years. In recent times, there has been a surge in deep neural network based approaches to solve graph problems, with growing availability of graph structured datasets across diverse domains. Nevertheless, existing methods are mostly tailored to solve a specific task and lack the capability to create a generalized model leading to solutions for different downstream tasks. In this work, we propose a novel, resource-efficient framework named \emph{U}nified \emph{G}raph \emph{N}etwork (UGN) by leveraging the feature extraction capability of graph convolutional neural networks (GCN) and 2-dimensional convolutional neural networks (Conv2D). UGN unifies various graph learning tasks, such as link prediction, node classification, community detection, graph-to-graph translation, knowledge graph completion, and more, within a cohesive framework, while exercising minimal task-specific extensions (e.g., formation of supernodes for coarsening massive networks to increase scalability, use of \textit{mean target connectivity matrix} (MTCM) representation for achieving scalability in graph translation task, etc.) to enhance the generalization capability of graph learning and analysis. We test the novel UGN framework for six uncorrelated graph problems, using twelve different datasets. Experimental results show that UGN outperforms the state-of-the-art baselines by a significant margin on ten datasets, while producing comparable results on the remaining dataset.
AlpaPICO: Extraction of PICO Frames from Clinical Trial Documents Using LLMs
Sep 15, 2024



In recent years, there has been a surge in the publication of clinical trial reports, making it challenging to conduct systematic reviews. Automatically extracting Population, Intervention, Comparator, and Outcome (PICO) from clinical trial studies can alleviate the traditionally time-consuming process of manually scrutinizing systematic reviews. Existing approaches of PICO frame extraction involves supervised approach that relies on the existence of manually annotated data points in the form of BIO label tagging. Recent approaches, such as In-Context Learning (ICL), which has been shown to be effective for a number of downstream NLP tasks, require the use of labeled examples. In this work, we adopt ICL strategy by employing the pretrained knowledge of Large Language Models (LLMs), gathered during the pretraining phase of an LLM, to automatically extract the PICO-related terminologies from clinical trial documents in unsupervised set up to bypass the availability of large number of annotated data instances. Additionally, to showcase the highest effectiveness of LLM in oracle scenario where large number of annotated samples are available, we adopt the instruction tuning strategy by employing Low Rank Adaptation (LORA) to conduct the training of gigantic model in low resource environment for the PICO frame extraction task. Our empirical results show that our proposed ICL-based framework produces comparable results on all the version of EBM-NLP datasets and the proposed instruction tuned version of our framework produces state-of-the-art results on all the different EBM-NLP datasets. Our project is available at \url{https://github.com/shrimonmuke0202/AlpaPICO.git}.
Generator-Guided Crowd Reaction Assessment
Mar 08, 2024In the realm of social media, understanding and predicting post reach is a significant challenge. This paper presents a Crowd Reaction AssessMent (CReAM) task designed to estimate if a given social media post will receive more reaction than another, a particularly essential task for digital marketers and content writers. We introduce the Crowd Reaction Estimation Dataset (CRED), consisting of pairs of tweets from The White House with comparative measures of retweet count. The proposed Generator-Guided Estimation Approach (GGEA) leverages generative Large Language Models (LLMs), such as ChatGPT, FLAN-UL2, and Claude, to guide classification models for making better predictions. Our results reveal that a fine-tuned FLANG-RoBERTa model, utilizing a cross-encoder architecture with tweet content and responses generated by Claude, performs optimally. We further use a T5-based paraphraser to generate paraphrases of a given post and demonstrate GGEA's ability to predict which post will elicit the most reactions. We believe this novel application of LLMs provides a significant advancement in predicting social media post reach.
Convolutional Neural Networks can achieve binary bail judgement classification
Jan 25, 2024



There is an evident lack of implementation of Machine Learning (ML) in the legal domain in India, and any research that does take place in this domain is usually based on data from the higher courts of law and works with English data. The lower courts and data from the different regional languages of India are often overlooked. In this paper, we deploy a Convolutional Neural Network (CNN) architecture on a corpus of Hindi legal documents. We perform a bail Prediction task with the help of a CNN model and achieve an overall accuracy of 93\% which is an improvement on the benchmark accuracy, set by Kapoor et al. (2022), albeit in data from 20 districts of the Indian state of Uttar Pradesh.
Attentive Fusion: A Transformer-based Approach to Multimodal Hate Speech Detection
Jan 19, 2024
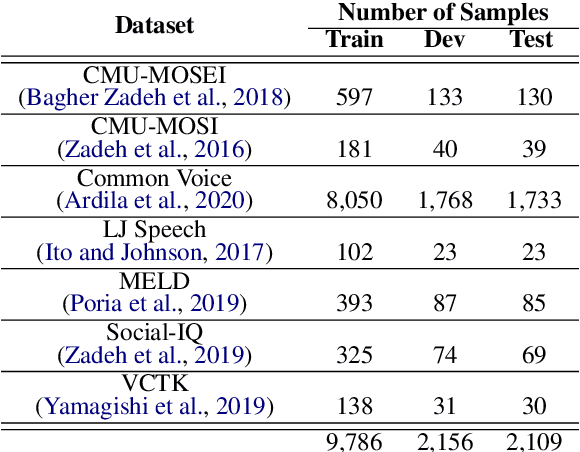
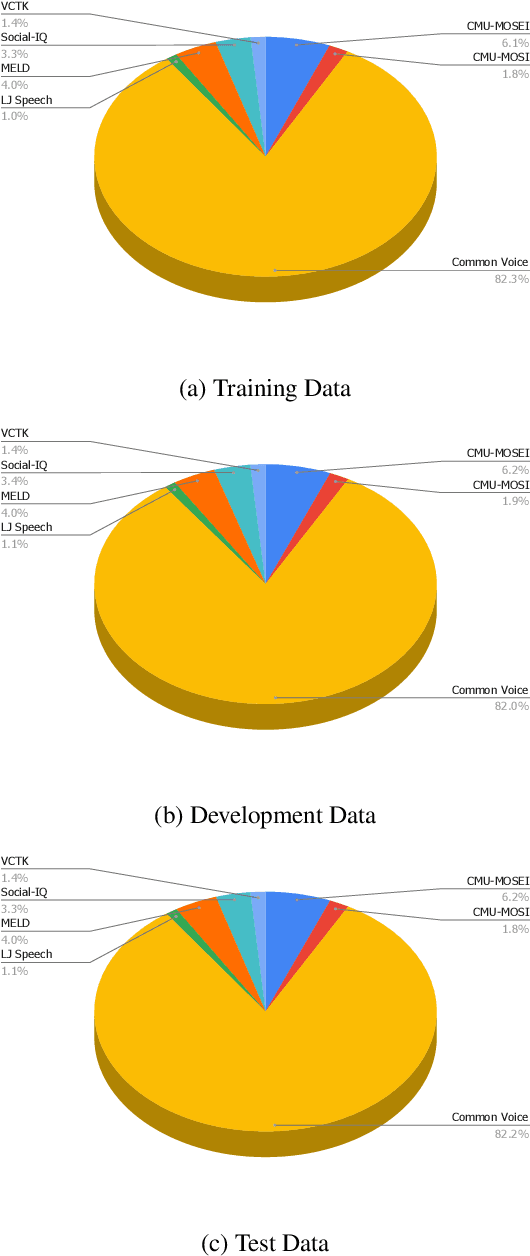
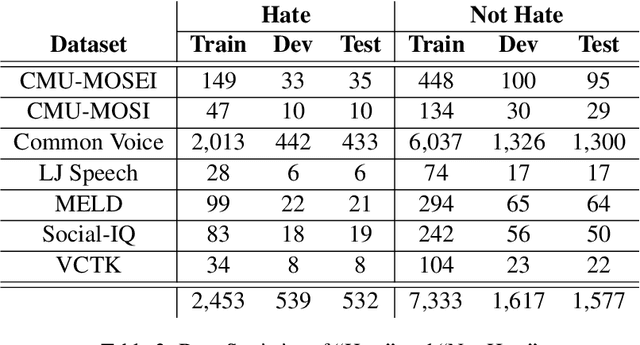
With the recent surge and exponential growth of social media usage, scrutinizing social media content for the presence of any hateful content is of utmost importance. Researchers have been diligently working since the past decade on distinguishing between content that promotes hatred and content that does not. Traditionally, the main focus has been on analyzing textual content. However, recent research attempts have also commenced into the identification of audio-based content. Nevertheless, studies have shown that relying solely on audio or text-based content may be ineffective, as recent upsurge indicates that individuals often employ sarcasm in their speech and writing. To overcome these challenges, we present an approach to identify whether a speech promotes hate or not utilizing both audio and textual representations. Our methodology is based on the Transformer framework that incorporates both audio and text sampling, accompanied by our very own layer called "Attentive Fusion". The results of our study surpassed previous state-of-the-art techniques, achieving an impressive macro F1 score of 0.927 on the Test Set.
Enhancing AI Research Paper Analysis: Methodology Component Extraction using Factored Transformer-based Sequence Modeling Approach
Nov 05, 2023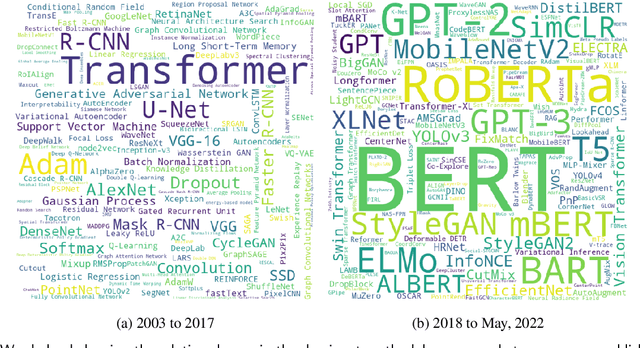
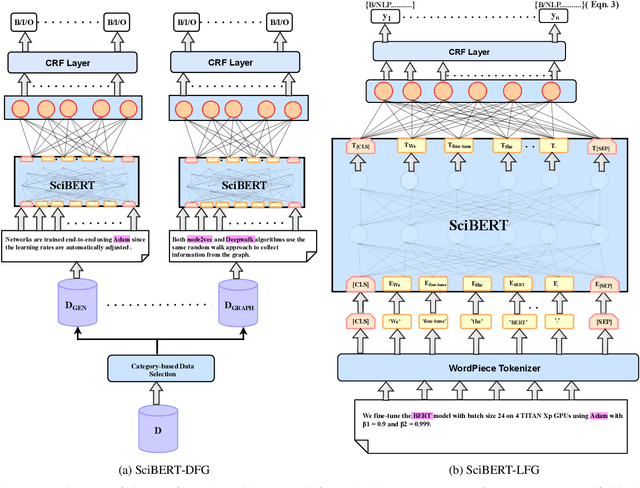

Research in scientific disciplines evolves, often rapidly, over time with the emergence of novel methodologies and their associated terminologies. While methodologies themselves being conceptual in nature and rather difficult to automatically extract and characterise, in this paper, we seek to develop supervised models for automatic extraction of the names of the various constituents of a methodology, e.g., `R-CNN', `ELMo' etc. The main research challenge for this task is effectively modeling the contexts around these methodology component names in a few-shot or even a zero-shot setting. The main contributions of this paper towards effectively identifying new evolving scientific methodology names are as follows: i) we propose a factored approach to sequence modeling, which leverages a broad-level category information of methodology domains, e.g., `NLP', `RL' etc.; ii) to demonstrate the feasibility of our proposed approach of identifying methodology component names under a practical setting of fast evolving AI literature, we conduct experiments following a simulated chronological setup (newer methodologies not seen during the training process); iii) our experiments demonstrate that the factored approach outperforms state-of-the-art baselines by margins of up to 9.257\% for the methodology extraction task with the few-shot setup.
Learning Semantic Text Similarity to rank Hypernyms of Financial Terms
Mar 20, 2023Over the years, there has been a paradigm shift in how users access financial services. With the advancement of digitalization more users have been preferring the online mode of performing financial activities. This has led to the generation of a huge volume of financial content. Most investors prefer to go through these contents before making decisions. Every industry has terms that are specific to the domain it operates in. Banking and Financial Services are not an exception to this. In order to fully comprehend these contents, one needs to have a thorough understanding of the financial terms. Getting a basic idea about a term becomes easy when it is explained with the help of the broad category to which it belongs. This broad category is referred to as hypernym. For example, "bond" is a hypernym of the financial term "alternative debenture". In this paper, we propose a system capable of extracting and ranking hypernyms for a given financial term. The system has been trained with financial text corpora obtained from various sources like DBpedia [4], Investopedia, Financial Industry Business Ontology (FIBO), prospectus and so on. Embeddings of these terms have been extracted using FinBERT [3], FinISH [1] and fine-tuned using SentenceBERT [54]. A novel approach has been used to augment the training set with negative samples. It uses the hierarchy present in FIBO. Finally, we benchmark the system performance with that of the existing ones. We establish that it performs better than the existing ones and is also scalable.
Evaluating Impact of Social Media Posts by Executives on Stock Prices
Nov 01, 2022Predicting stock market movements has always been of great interest to investors and an active area of research. Research has proven that popularity of products is highly influenced by what people talk about. Social media like Twitter, Reddit have become hotspots of such influences. This paper investigates the impact of social media posts on close price prediction of stocks using Twitter and Reddit posts. Our objective is to integrate sentiment of social media data with historical stock data and study its effect on closing prices using time series models. We carried out rigorous experiments and deep analysis using multiple deep learning based models on different datasets to study the influence of posts by executives and general people on the close price. Experimental results on multiple stocks (Apple and Tesla) and decentralised currencies (Bitcoin and Ethereum) consistently show improvements in prediction on including social media data and greater improvements on including executive posts.