 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Reliable & Parsimonious Learning Strategy Comprising Two Layers of Gaussian Processes, to Address Inhomogeneous Empirical Correlation Structures
Apr 18, 2024We present a new strategy for learning the functional relation between a pair of variables, while addressing inhomogeneities in the correlation structure of the available data, by modelling the sought function as a sample function of a non-stationary Gaussian Process (GP), that nests within itself multiple other GPs, each of which we prove can be stationary, thereby establishing sufficiency of two GP layers. In fact, a non-stationary kernel is envisaged, with each hyperparameter set as dependent on the sample function drawn from the outer non-stationary GP, such that a new sample function is drawn at every pair of input values at which the kernel is computed. However, such a model cannot be implemented, and we substitute this by recalling that the average effect of drawing different sample functions from a given GP is equivalent to that of drawing a sample function from each of a set of GPs that are rendered different, as updated during the equilibrium stage of the undertaken inference (via MCMC). The kernel is fully non-parametric, and it suffices to learn one hyperparameter per layer of GP, for each dimension of the input variable. We illustrate this new learning strategy on a real dataset.
Attentive Fusion: A Transformer-based Approach to Multimodal Hate Speech Detection
Jan 19, 2024
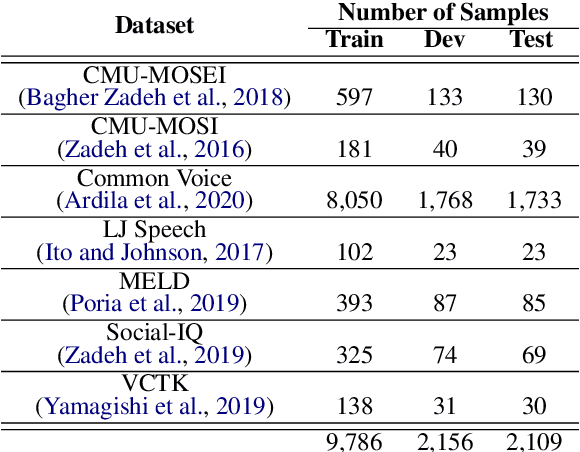
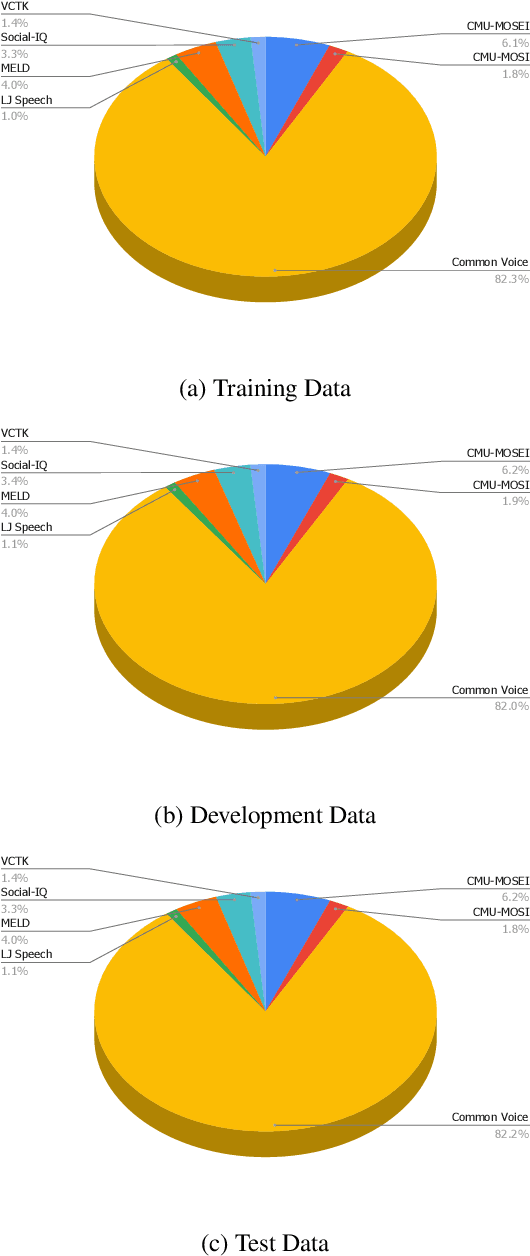
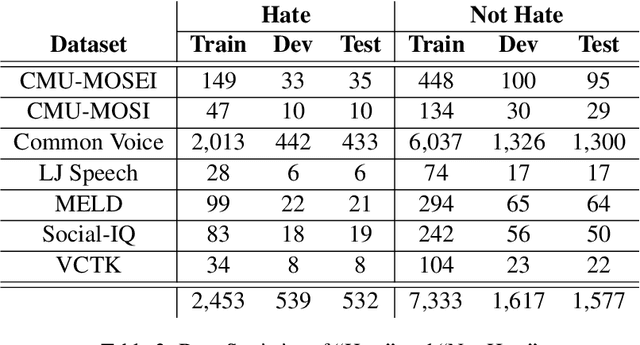
With the recent surge and exponential growth of social media usage, scrutinizing social media content for the presence of any hateful content is of utmost importance. Researchers have been diligently working since the past decade on distinguishing between content that promotes hatred and content that does not. Traditionally, the main focus has been on analyzing textual content. However, recent research attempts have also commenced into the identification of audio-based content. Nevertheless, studies have shown that relying solely on audio or text-based content may be ineffective, as recent upsurge indicates that individuals often employ sarcasm in their speech and writing. To overcome these challenges, we present an approach to identify whether a speech promotes hate or not utilizing both audio and textual representations. Our methodology is based on the Transformer framework that incorporates both audio and text sampling, accompanied by our very own layer called "Attentive Fusion". The results of our study surpassed previous state-of-the-art techniques, achieving an impressive macro F1 score of 0.927 on the Test Set.