 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Scratch to Fine-Tuned: A Comparative Study of Transformer Training Strategies for Legal Machine Translation
Dec 21, 2025In multilingual nations like India, access to legal information is often hindered by language barriers, as much of the legal and judicial documentation remains in English. Legal Machine Translation (L-MT) offers a scalable solution to this challenge by enabling accurate and accessible translations of legal documents. This paper presents our work for the JUST-NLP 2025 Legal MT shared task, focusing on English-Hindi translation using Transformer-based approaches. We experiment with 2 complementary strategies, fine-tuning a pre-trained OPUS-MT model for domain-specific adaptation and training a Transformer model from scratch using the provided legal corpus. Performance is evaluated using standard MT metrics, including SacreBLEU, chrF++, TER, ROUGE, BERTScore, METEOR, and COMET. Our fine-tuned OPUS-MT model achieves a SacreBLEU score of 46.03, significantly outperforming both baseline and from-scratch models. The results highlight the effectiveness of domain adaptation in enhancing translation quality and demonstrate the potential of L-MT systems to improve access to justice and legal transparency in multilingual contexts.
Attentive Fusion: A Transformer-based Approach to Multimodal Hate Speech Detection
Jan 19, 2024
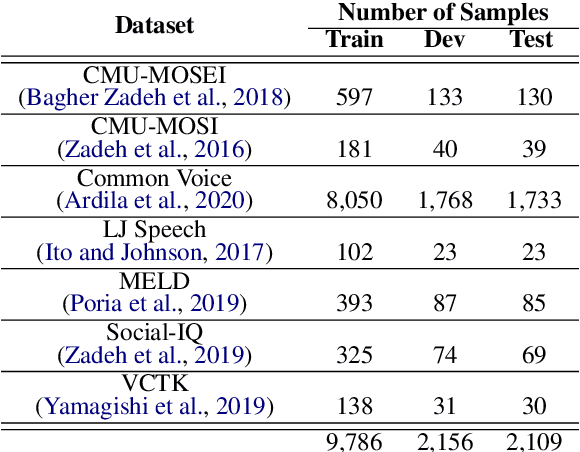
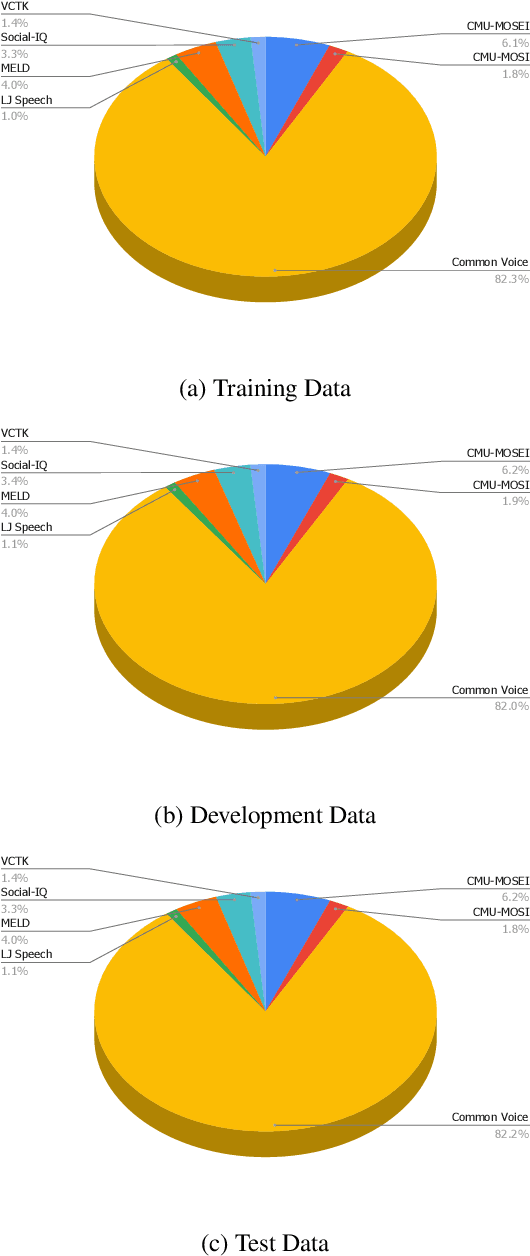
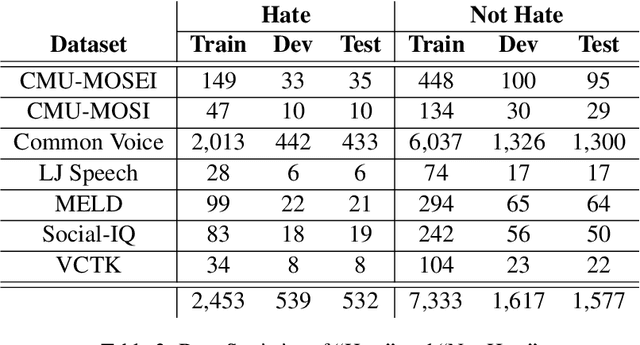
With the recent surge and exponential growth of social media usage, scrutinizing social media content for the presence of any hateful content is of utmost importance. Researchers have been diligently working since the past decade on distinguishing between content that promotes hatred and content that does not. Traditionally, the main focus has been on analyzing textual content. However, recent research attempts have also commenced into the identification of audio-based content. Nevertheless, studies have shown that relying solely on audio or text-based content may be ineffective, as recent upsurge indicates that individuals often employ sarcasm in their speech and writing. To overcome these challenges, we present an approach to identify whether a speech promotes hate or not utilizing both audio and textual representations. Our methodology is based on the Transformer framework that incorporates both audio and text sampling, accompanied by our very own layer called "Attentive Fusion". The results of our study surpassed previous state-of-the-art techniques, achieving an impressive macro F1 score of 0.927 on the Test Set.
Is Attention always needed? A Case Study on Language Identification from Speech
Oct 05, 2021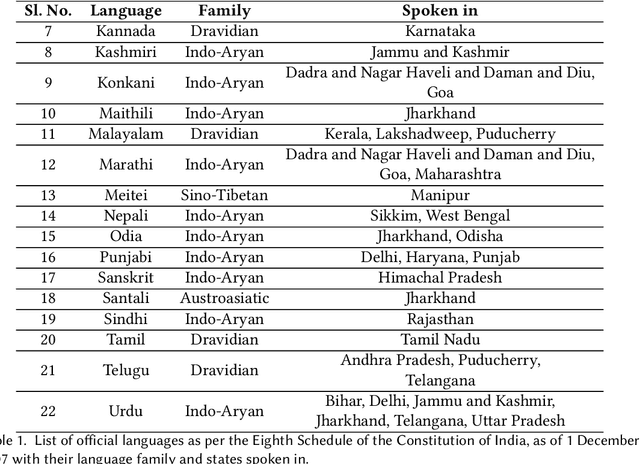
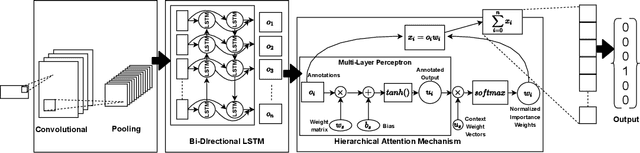
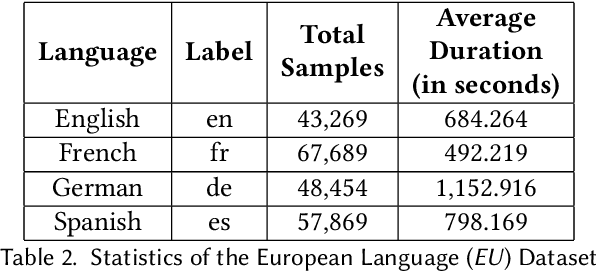
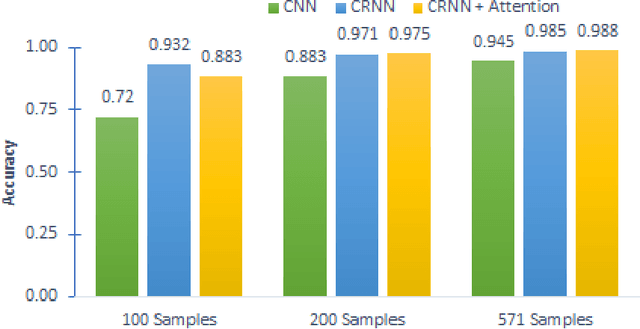
Language Identification (LID), a recommended initial step to Automatic Speech Recognition (ASR), is used to detect a spoken language from audio specimens. In state-of-the-art systems capable of multilingual speech processing, however, users have to explicitly set one or more languages before using them. LID, therefore, plays a very important role in situations where ASR based systems cannot parse the uttered language in multilingual contexts causing failure in speech recognition. We propose an attention based convolutional recurrent neural network (CRNN with Attention) that works on Mel-frequency Cepstral Coefficient (MFCC) features of audio specimens. Additionally, we reproduce some state-of-the-art approaches, namely Convolutional Neural Network (CNN) and Convolutional Recurrent Neural Network (CRNN), and compare them to our proposed method. We performed extensive evaluation on thirteen different Indian languages and our model achieves classification accuracy over 98%. Our LID model is robust to noise and provides 91.2% accuracy in a noisy scenario. The proposed model is easily extensible to new languages.