 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks can achieve binary bail judgement classification
Jan 25, 2024



There is an evident lack of implementation of Machine Learning (ML) in the legal domain in India, and any research that does take place in this domain is usually based on data from the higher courts of law and works with English data. The lower courts and data from the different regional languages of India are often overlooked. In this paper, we deploy a Convolutional Neural Network (CNN) architecture on a corpus of Hindi legal documents. We perform a bail Prediction task with the help of a CNN model and achieve an overall accuracy of 93\% which is an improvement on the benchmark accuracy, set by Kapoor et al. (2022), albeit in data from 20 districts of the Indian state of Uttar Pradesh.
BeAts: Bengali Speech Acts Recognition using Multimodal Attention Fusion
Jun 05, 2023Spoken languages often utilise intonation, rhythm, intensity, and structure, to communicate intention, which can be interpreted differently depending on the rhythm of speech of their utterance. These speech acts provide the foundation of communication and are unique in expression to the language. Recent advancements in attention-based models, demonstrating their ability to learn powerful representations from multilingual datasets, have performed well in speech tasks and are ideal to model specific tasks in low resource languages. Here, we develop a novel multimodal approach combining two models, wav2vec2.0 for audio and MarianMT for text translation, by using multimodal attention fusion to predict speech acts in our prepared Bengali speech corpus. We also show that our model BeAts ($\underline{\textbf{Be}}$ngali speech acts recognition using Multimodal $\underline{\textbf{At}}$tention Fu$\underline{\textbf{s}}$ion) significantly outperforms both the unimodal baseline using only speech data and a simpler bimodal fusion using both speech and text data. Project page: https://soumitri2001.github.io/BeAts
On Language Clustering: A Non-parametric Statistical Approach
Sep 14, 2022


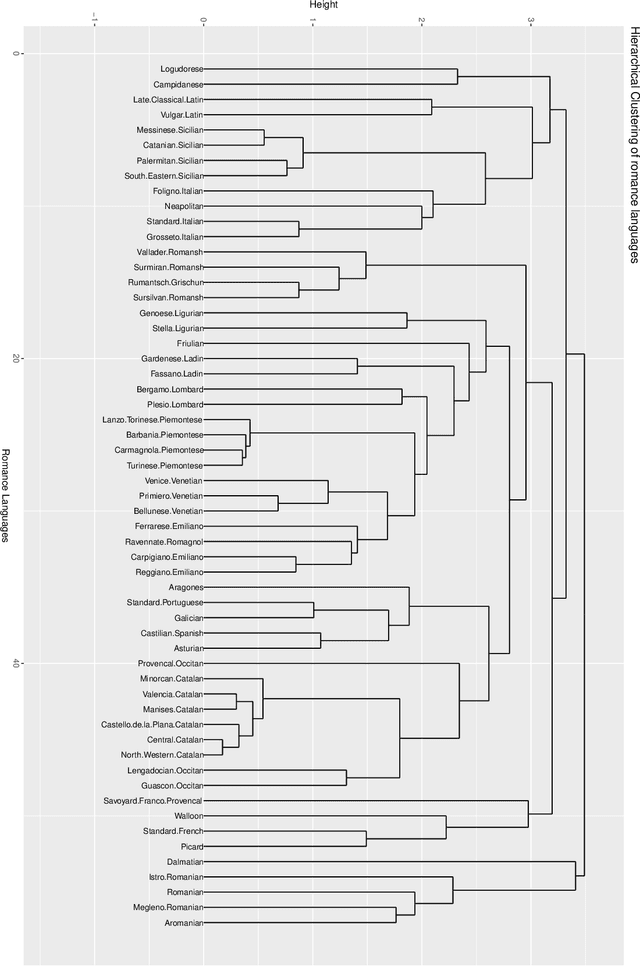
Any approach aimed at pasteurizing and quantifying a particular phenomenon must include the use of robust statistical methodologies for data analysis. With this in mind, the purpose of this study is to present statistical approaches that may be employed in nonparametric nonhomogeneous data frameworks, as well as to examine their application in the field of natural language processing and language clustering. Furthermore, this paper discusses the many uses of nonparametric approaches in linguistic data mining and processing. The data depth idea allows for the centre-outward ordering of points in any dimension, resulting in a new nonparametric multivariate statistical analysis that does not require any distributional assumptions. The concept of hierarchy is used in historical language categorisation and structuring, and it aims to organise and cluster languages into subfamilies using the same premise. In this regard, the current study presents a novel approach to language family structuring based on non-parametric approaches produced from a typological structure of words in various languages, which is then converted into a Cartesian framework using MDS. This statistical-depth-based architecture allows for the use of data-depth-based methodologies for robust outlier detection, which is extremely useful in understanding the categorization of diverse borderline languages and allows for the re-evaluation of existing classification systems. Other depth-based approaches are also applied to processes such as unsupervised and supervised clustering. This paper therefore provides an overview of procedures that can be applied to nonhomogeneous language classification systems in a nonparametric framework.
A Fractal Approach to Characterize Emotions in Audio and Visual Domain: A Study on Cross-Modal Interaction
Feb 11, 2021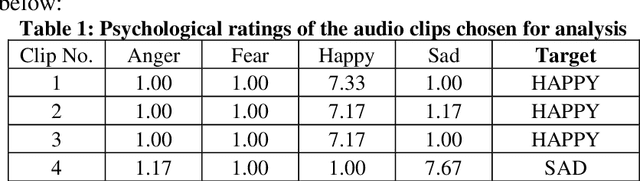


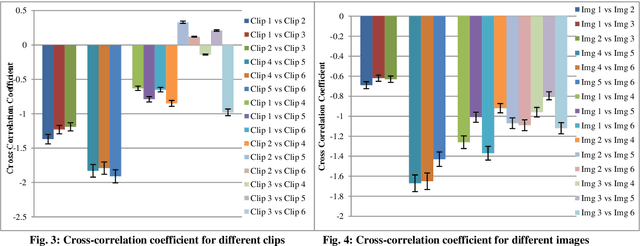
It is already known that both auditory and visual stimulus is able to convey emotions in human mind to different extent. The strength or intensity of the emotional arousal vary depending on the type of stimulus chosen. In this study, we try to investigate the emotional arousal in a cross-modal scenario involving both auditory and visual stimulus while studying their source characteristics. A robust fractal analytic technique called Detrended Fluctuation Analysis (DFA) and its 2D analogue has been used to characterize three (3) standardized audio and video signals quantifying their scaling exponent corresponding to positive and negative valence. It was found that there is significant difference in scaling exponents corresponding to the two different modalities. Detrended Cross Correlation Analysis (DCCA) has also been applied to decipher degree of cross-correlation among the individual audio and visual stimulus. This is the first of its kind study which proposes a novel algorithm with which emotional arousal can be classified in cross-modal scenario using only the source audio and visual signals while also attempting a correlation between them.