 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Language Clustering: A Non-parametric Statistical Approach
Sep 14, 2022


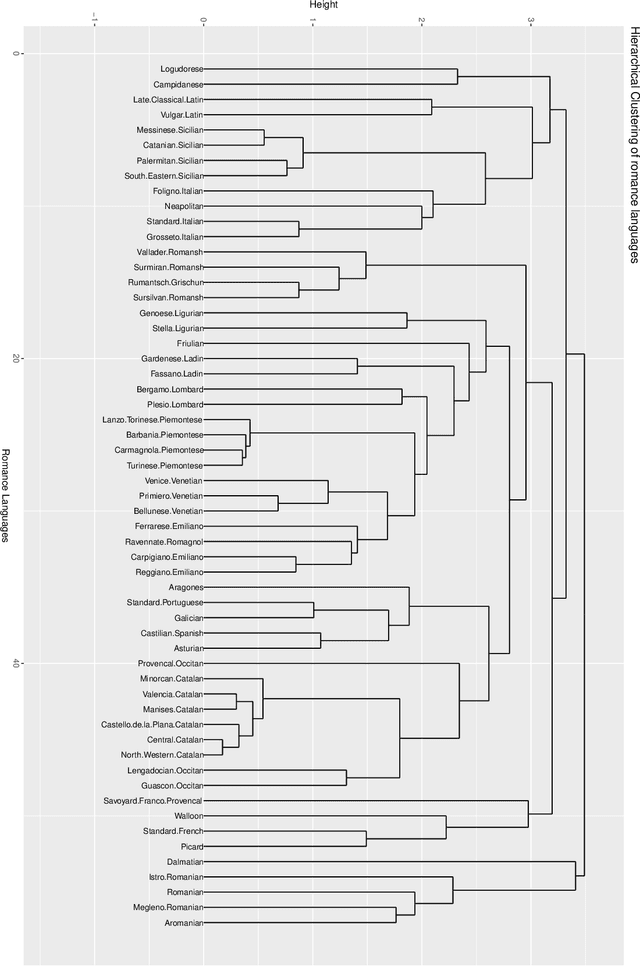
Any approach aimed at pasteurizing and quantifying a particular phenomenon must include the use of robust statistical methodologies for data analysis. With this in mind, the purpose of this study is to present statistical approaches that may be employed in nonparametric nonhomogeneous data frameworks, as well as to examine their application in the field of natural language processing and language clustering. Furthermore, this paper discusses the many uses of nonparametric approaches in linguistic data mining and processing. The data depth idea allows for the centre-outward ordering of points in any dimension, resulting in a new nonparametric multivariate statistical analysis that does not require any distributional assumptions. The concept of hierarchy is used in historical language categorisation and structuring, and it aims to organise and cluster languages into subfamilies using the same premise. In this regard, the current study presents a novel approach to language family structuring based on non-parametric approaches produced from a typological structure of words in various languages, which is then converted into a Cartesian framework using MDS. This statistical-depth-based architecture allows for the use of data-depth-based methodologies for robust outlier detection, which is extremely useful in understanding the categorization of diverse borderline languages and allows for the re-evaluation of existing classification systems. Other depth-based approaches are also applied to processes such as unsupervised and supervised clustering. This paper therefore provides an overview of procedures that can be applied to nonhomogeneous language classification systems in a nonparametric framework.