 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fractal Approach to Characterize Emotions in Audio and Visual Domain: A Study on Cross-Modal Interaction
Feb 11, 2021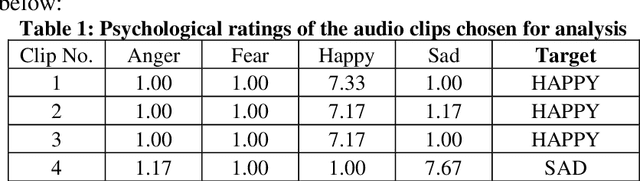


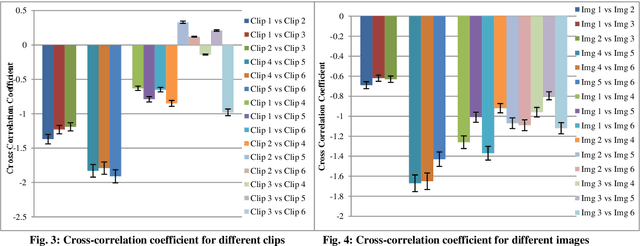
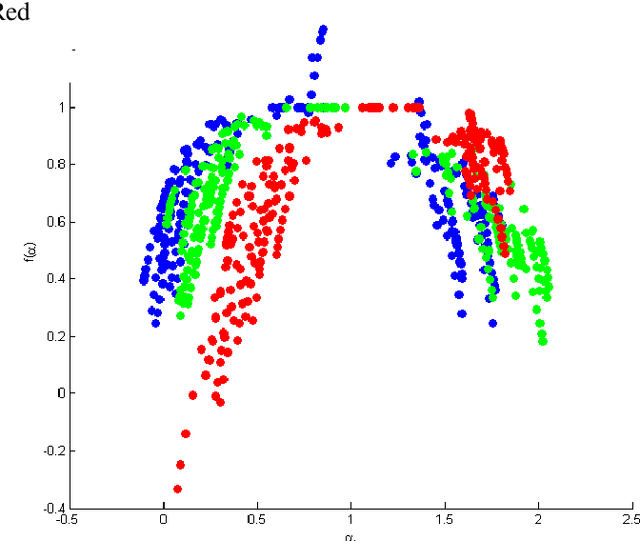
It is already known that both auditory and visual stimulus is able to convey emotions in human mind to different extent. The strength or intensity of the emotional arousal vary depending on the type of stimulus chosen. In this study, we try to investigate the emotional arousal in a cross-modal scenario involving both auditory and visual stimulus while studying their source characteristics. A robust fractal analytic technique called Detrended Fluctuation Analysis (DFA) and its 2D analogue has been used to characterize three (3) standardized audio and video signals quantifying their scaling exponent corresponding to positive and negative valence. It was found that there is significant difference in scaling exponents corresponding to the two different modalities. Detrended Cross Correlation Analysis (DCCA) has also been applied to decipher degree of cross-correlation among the individual audio and visual stimulus. This is the first of its kind study which proposes a novel algorithm with which emotional arousal can be classified in cross-modal scenario using only the source audio and visual signals while also attempting a correlation between them.
Language Independent Emotion Quantification using Non linear Modelling of Speech
Feb 11, 2021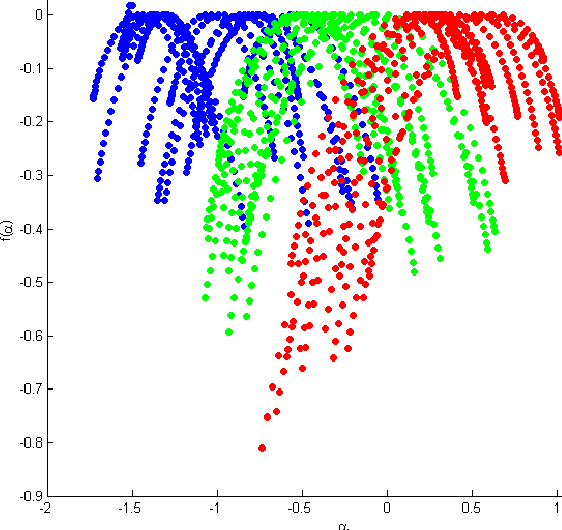
At present emotion extraction from speech is a very important issue due to its diverse applications. Hence, it becomes absolutely necessary to obtain models that take into consideration the speaking styles of a person, vocal tract information, timbral qualities and other congenital information regarding his voice. Our speech production system is a nonlinear system like most other real world systems. Hence the need arises for modelling our speech information using nonlinear techniques. In this work we have modelled our articulation system using nonlinear multifractal analysis. The multifractal spectral width and scaling exponents reveals essentially the complexity associated with the speech signals taken. The multifractal spectrums are well distinguishable the in low fluctuation region in case of different emotions. The source characteristics have been quantified with the help of different non-linear models like Multi-Fractal Detrended Fluctuation Analysis, Wavelet Transform Modulus Maxima. The Results obtained from this study gives a very good result in emotion clustering.
Neural Network architectures to classify emotions in Indian Classical Music
Feb 01, 2021
Music is often considered as the language of emotions. It has long been known to elicit emotions in human being and thus categorizing music based on the type of emotions they induce in human being is a very intriguing topic of research. When the task comes to classify emotions elicited by Indian Classical Music (ICM), it becomes much more challenging because of the inherent ambiguity associated with ICM. The fact that a single musical performance can evoke a variety of emotional response in the audience is implicit to the nature of ICM renditions. With the rapid advancements in the field of Deep Learning, this Music Emotion Recognition (MER) task is becoming more and more relevant and robust, hence can be applied to one of the most challenging test case i.e. classifying emotions elicited from ICM. In this paper we present a new dataset called JUMusEmoDB which presently has 400 audio clips (30 seconds each) where 200 clips correspond to happy emotions and the remaining 200 clips correspond to sad emotion. For supervised classification purposes, we have used 4 existing deep Convolutional Neural Network (CNN) based architectures (resnet18, mobilenet v2.0, squeezenet v1.0 and vgg16) on corresponding music spectrograms of the 2000 sub-clips (where every clip was segmented into 5 sub-clips of about 5 seconds each) which contain both time as well as frequency domain information. The initial results are quite inspiring, and we look forward to setting the baseline values for the dataset using this architecture. This type of CNN based classification algorithm using a rich corpus of Indian Classical Music is unique even in the global perspective and can be replicated in other modalities of music also. This dataset is still under development and we plan to include more data containing other emotional features as well. We plan to make the dataset publicly available soon.
Speaker Recognition in Bengali Language from Nonlinear Features
Apr 15, 2020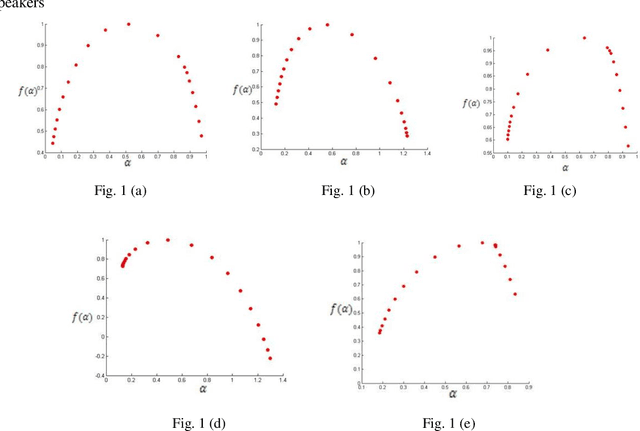

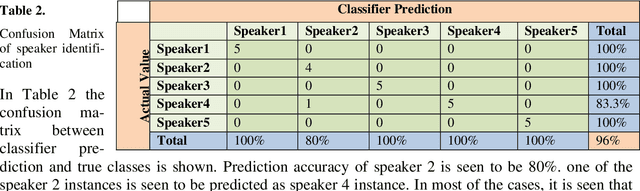
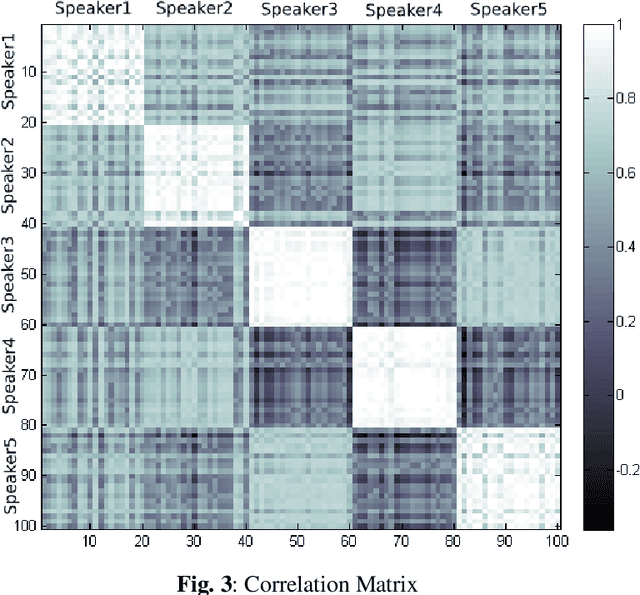
At present Automatic Speaker Recognition system is a very important issue due to its diverse applications. Hence, it becomes absolutely necessary to obtain models that take into consideration the speaking style of a person, vocal tract information, timbral qualities of his voice and other congenital information regarding his voice. The study of Bengali speech recognition and speaker identification is scarce in the literature. Hence the need arises for involving Bengali subjects in modelling our speaker identification engine. In this work, we have extracted some acoustic features of speech using non linear multifractal analysis. The Multifractal Detrended Fluctuation Analysis reveals essentially the complexity associated with the speech signals taken. The source characteristics have been quantified with the help of different techniques like Correlation Matrix, skewness of MFDFA spectrum etc. The Results obtained from this study gives a good recognition rate for Bengali Speakers.
An Adaptive Genetic Algorithm for Solving N-Queens Problem
Nov 01, 2017
In this paper a Metaheuristic approach for solving the N-Queens Problem is introduced to find the best possible solution in a reasonable amount of time. Genetic Algorithm is used with a novel fitness function as the Metaheuristic. The aim of N-Queens Problem is to place N queens on an N x N chessboard, in a way so that no queen is in conflict with the others. Chromosome representation and genetic operations like Mutation and Crossover are described in detail. Results show that this approach yields promising and satisfactory results in less time compared to that obtained from the previous approaches for several large values of N.