 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Recognition in Bengali Language from Nonlinear Features
Paper and Code
Apr 15, 2020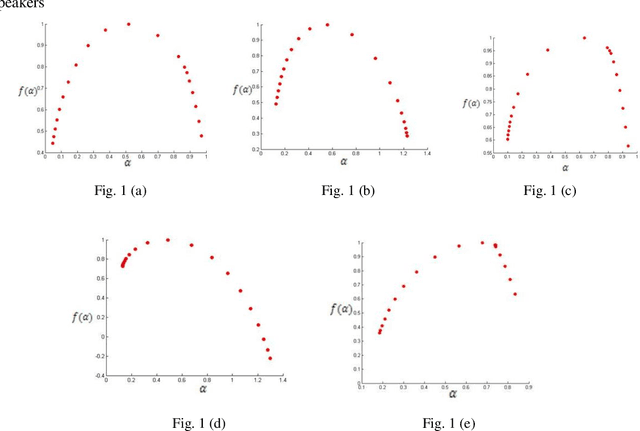

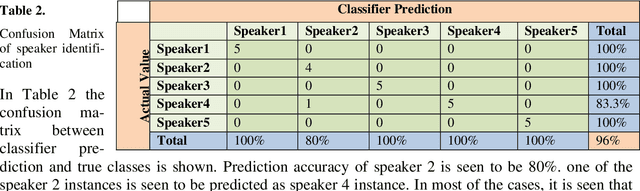
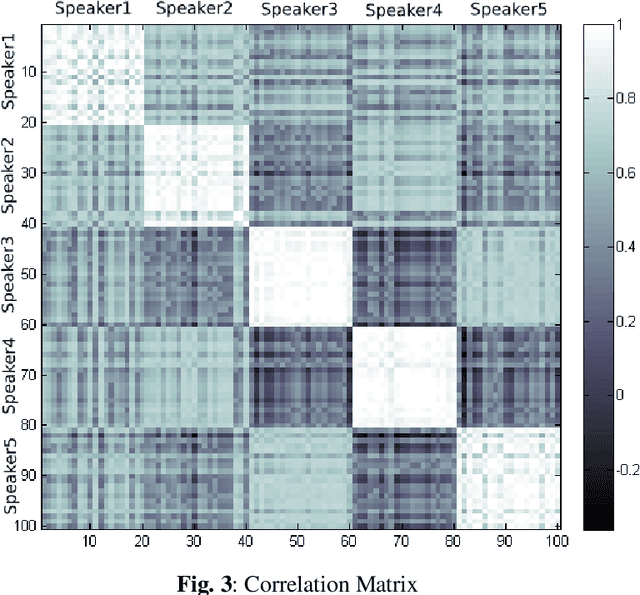
At present Automatic Speaker Recognition system is a very important issue due to its diverse applications. Hence, it becomes absolutely necessary to obtain models that take into consideration the speaking style of a person, vocal tract information, timbral qualities of his voice and other congenital information regarding his voice. The study of Bengali speech recognition and speaker identification is scarce in the literature. Hence the need arises for involving Bengali subjects in modelling our speaker identification engine. In this work, we have extracted some acoustic features of speech using non linear multifractal analysis. The Multifractal Detrended Fluctuation Analysis reveals essentially the complexity associated with the speech signals taken. The source characteristics have been quantified with the help of different techniques like Correlation Matrix, skewness of MFDFA spectrum etc. The Results obtained from this study gives a good recognition rate for Bengali Speakers.