 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-WIPER : Training-Free Object and Associated Effect Removal in Videos
Jan 10, 2026In this paper, we introduce Object-WIPER, a training-free framework for removing dynamic objects and their associated visual effects from videos, and inpainting them with semantically consistent and temporally coherent content. Our approach leverages a pre-trained text-to-video diffusion transformer (DiT). Given an input video, a user-provided object mask, and query tokens describing the target object and its effects, we localize relevant visual tokens via visual-text cross-attention and visual self-attention. This produces an intermediate effect mask that we fuse with the user mask to obtain a final foreground token mask to replace. We first invert the video through the DiT to obtain structured noise, then reinitialize the masked tokens with Gaussian noise while preserving background tokens. During denoising, we copy values for the background tokens saved during inversion to maintain scene fidelity. To address the lack of suitable evaluation, we introduce a new object removal metric that rewards temporal consistency among foreground tokens across consecutive frames, coherence between foreground and background tokens within each frame, and dissimilarity between the input and output foreground tokens. Experiments on DAVIS and a newly curated real-world associated effect benchmark (WIPER-Bench) show that Object-WIPER surpasses both training-based and training-free baselines in terms of the metric, achieving clean removal and temporally stable reconstruction without any retraining. Our new benchmark, source code, and pre-trained models will be publicly available.
SciFig: Towards Automating Scientific Figure Generation
Jan 07, 2026Creating high-quality figures and visualizations for scientific papers is a time-consuming task that requires both deep domain knowledge and professional design skills. Despite over 2.5 million scientific papers published annually, the figure generation process remains largely manual. We introduce $\textbf{SciFig}$, an end-to-end AI agent system that generates publication-ready pipeline figures directly from research paper texts. SciFig uses a hierarchical layout generation strategy, which parses research descriptions to identify component relationships, groups related elements into functional modules, and generates inter-module connections to establish visual organization. Furthermore, an iterative chain-of-thought (CoT) feedback mechanism progressively improves layouts through multiple rounds of visual analysis and reasoning. We introduce a rubric-based evaluation framework that analyzes 2,219 real scientific figures to extract evaluation rubrics and automatically generates comprehensive evaluation criteria. SciFig demonstrates remarkable performance: achieving 70.1$\%$ overall quality on dataset-level evaluation and 66.2$\%$ on paper-specific evaluation, and consistently high scores across metrics such as visual clarity, structural organization, and scientific accuracy. SciFig figure generation pipeline and our evaluation benchmark will be open-sourced.
SliderEdit: Continuous Image Editing with Fine-Grained Instruction Control
Nov 12, 2025Instruction-based image editing models have recently achieved impressive performance, enabling complex edits to an input image from a multi-instruction prompt. However, these models apply each instruction in the prompt with a fixed strength, limiting the user's ability to precisely and continuously control the intensity of individual edits. We introduce SliderEdit, a framework for continuous image editing with fine-grained, interpretable instruction control. Given a multi-part edit instruction, SliderEdit disentangles the individual instructions and exposes each as a globally trained slider, allowing smooth adjustment of its strength. Unlike prior works that introduced slider-based attribute controls in text-to-image generation, typically requiring separate training or fine-tuning for each attribute or concept, our method learns a single set of low-rank adaptation matrices that generalize across diverse edits, attributes, and compositional instructions. This enables continuous interpolation along individual edit dimensions while preserving both spatial locality and global semantic consistency. We apply SliderEdit to state-of-the-art image editing models, including FLUX-Kontext and Qwen-Image-Edit, and observe substantial improvements in edit controllability, visual consistency, and user steerability. To the best of our knowledge, we are the first to explore and propose a framework for continuous, fine-grained instruction control in instruction-based image editing models. Our results pave the way for interactive, instruction-driven image manipulation with continuous and compositional control.
AURA: A Fine-Grained Benchmark and Decomposed Metric for Audio-Visual Reasoning
Aug 10, 2025Current audio-visual (AV) benchmarks focus on final answer accuracy, overlooking the underlying reasoning process. This makes it difficult to distinguish genuine comprehension from correct answers derived through flawed reasoning or hallucinations. To address this, we introduce AURA (Audio-visual Understanding and Reasoning Assessment), a benchmark for evaluating the cross-modal reasoning capabilities of Audio-Visual Large Language Models (AV-LLMs) and Omni-modal Language Models (OLMs). AURA includes questions across six challenging cognitive domains, such as causality, timbre and pitch, tempo and AV synchronization, unanswerability, implicit distractions, and skill profiling, explicitly designed to be unanswerable from a single modality. This forces models to construct a valid logical path grounded in both audio and video, setting AURA apart from AV datasets that allow uni-modal shortcuts. To assess reasoning traces, we propose a novel metric, AuraScore, which addresses the lack of robust tools for evaluating reasoning fidelity. It decomposes reasoning into two aspects: (i) Factual Consistency - whether reasoning is grounded in perceptual evidence, and (ii) Core Inference - the logical validity of each reasoning step. Evaluations of SOTA models on AURA reveal a critical reasoning gap: although models achieve high accuracy (up to 92% on some tasks), their Factual Consistency and Core Inference scores fall below 45%. This discrepancy highlights that models often arrive at correct answers through flawed logic, underscoring the need for our benchmark and paving the way for more robust multimodal evaluation.
MAGNET: A Multi-agent Framework for Finding Audio-Visual Needles by Reasoning over Multi-Video Haystacks
Jun 08, 2025Large multimodal models (LMMs) have shown remarkable progress in audio-visual understanding, yet they struggle with real-world scenarios that require complex reasoning across extensive video collections. Existing benchmarks for video question answering remain limited in scope, typically involving one clip per query, which falls short of representing the challenges of large-scale, audio-visual retrieval and reasoning encountered in practical applications. To bridge this gap, we introduce a novel task named AV-HaystacksQA, where the goal is to identify salient segments across different videos in response to a query and link them together to generate the most informative answer. To this end, we present AVHaystacks, an audio-visual benchmark comprising 3100 annotated QA pairs designed to assess the capabilities of LMMs in multi-video retrieval and temporal grounding task. Additionally, we propose a model-agnostic, multi-agent framework MAGNET to address this challenge, achieving up to 89% and 65% relative improvements over baseline methods on BLEU@4 and GPT evaluation scores in QA task on our proposed AVHaystacks. To enable robust evaluation of multi-video retrieval and temporal grounding for optimal response generation, we introduce two new metrics, STEM, which captures alignment errors between a ground truth and a predicted step sequence and MTGS, to facilitate balanced and interpretable evaluation of segment-level grounding performance. Project: https://schowdhury671.github.io/magnet_project/
Localizing Knowledge in Diffusion Transformers
May 24, 2025Understanding how knowledge is distributed across the layers of generative models is crucial for improving interpretability, controllability, and adaptation. While prior work has explored knowledge localization in UNet-based architectures, Diffusion Transformer (DiT)-based models remain underexplored in this context. In this paper, we propose a model- and knowledge-agnostic method to localize where specific types of knowledge are encoded within the DiT blocks. We evaluate our method on state-of-the-art DiT-based models, including PixArt-alpha, FLUX, and SANA, across six diverse knowledge categories. We show that the identified blocks are both interpretable and causally linked to the expression of knowledge in generated outputs. Building on these insights, we apply our localization framework to two key applications: model personalization and knowledge unlearning. In both settings, our localized fine-tuning approach enables efficient and targeted updates, reducing computational cost, improving task-specific performance, and better preserving general model behavior with minimal interference to unrelated or surrounding content. Overall, our findings offer new insights into the internal structure of DiTs and introduce a practical pathway for more interpretable, efficient, and controllable model editing.
Aurelia: Test-time Reasoning Distillation in Audio-Visual LLMs
Mar 29, 2025Recent advancements in reasoning optimization have greatly enhanced the performance of large language models (LLMs). However, existing work fails to address the complexities of audio-visual scenarios, underscoring the need for further research. In this paper, we introduce AURELIA, a novel actor-critic based audio-visual (AV) reasoning framework that distills structured, step-by-step reasoning into AVLLMs at test time, improving their ability to process complex multi-modal inputs without additional training or fine-tuning. To further advance AVLLM reasoning skills, we present AVReasonBench, a challenging benchmark comprising 4500 audio-visual questions, each paired with detailed step-by-step reasoning. Our benchmark spans six distinct tasks, including AV-GeoIQ, which evaluates AV reasoning combined with geographical and cultural knowledge. Evaluating 18 AVLLMs on AVReasonBench reveals significant limitations in their multi-modal reasoning capabilities. Using AURELIA, we achieve up to a 100% relative improvement, demonstrating its effectiveness. This performance gain highlights the potential of reasoning-enhanced data generation for advancing AVLLMs in real-world applications. Our code and data will be publicly released at: https: //github.com/schowdhury671/aurelia.
AVTrustBench: Assessing and Enhancing Reliability and Robustness in Audio-Visual LLMs
Jan 03, 2025



With the rapid advancement of Multi-modal Large Language Models (MLLMs), several diagnostic benchmarks have recently been developed to assess these models' multi-modal reasoning proficiency. However, these benchmarks are restricted to assessing primarily the visual aspect and do not examine the holistic audio-visual (AV) understanding. Moreover, currently, there are no benchmarks that investigate the capabilities of AVLLMs to calibrate their responses when presented with perturbed inputs. To this end, we introduce Audio-Visual Trustworthiness assessment Benchmark (AVTrustBench), comprising 600K samples spanning over 9 meticulously crafted tasks, evaluating the capabilities of AVLLMs across three distinct dimensions: Adversarial attack, Compositional reasoning, and Modality-specific dependency. Using our benchmark we extensively evaluate 13 state-of-the-art AVLLMs. The findings reveal that the majority of existing models fall significantly short of achieving human-like comprehension, offering valuable insights for future research directions. To alleviate the limitations in the existing approaches, we further propose a robust, model-agnostic calibrated audio-visual preference optimization based training strategy CAVPref, obtaining a gain up to 30.19% across all 9 tasks. We will publicly release our code and benchmark to facilitate future research in this direction.
SafaRi:Adaptive Sequence Transformer for Weakly Supervised Referring Expression Segmentation
Jul 02, 2024
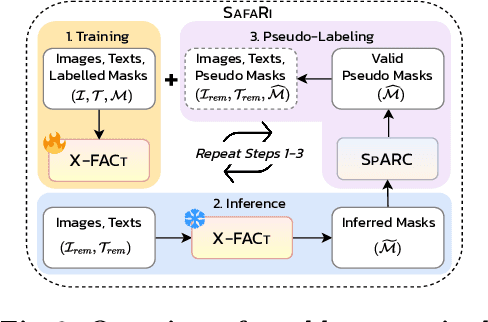
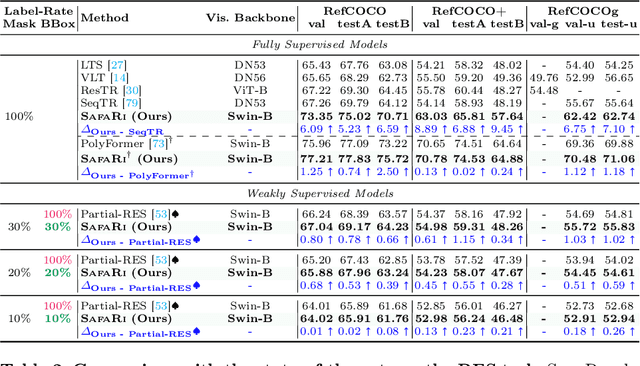
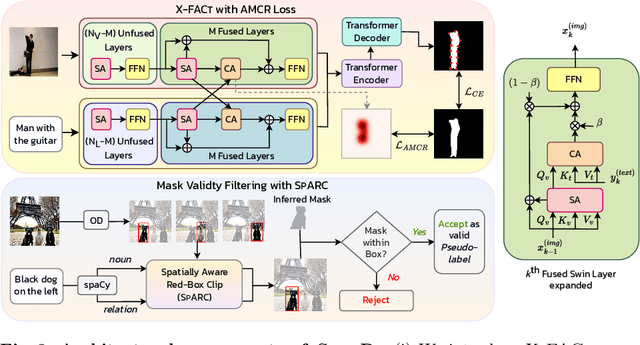
Referring Expression Segmentation (RES) aims to provide a segmentation mask of the target object in an image referred to by the text (i.e., referring expression). Existing methods require large-scale mask annotations. Moreover, such approaches do not generalize well to unseen/zero-shot scenarios. To address the aforementioned issues, we propose a weakly-supervised bootstrapping architecture for RES with several new algorithmic innovations. To the best of our knowledge, ours is the first approach that considers only a fraction of both mask and box annotations (shown in Figure 1 and Table 1) for training. To enable principled training of models in such low-annotation settings, improve image-text region-level alignment, and further enhance spatial localization of the target object in the image, we propose Cross-modal Fusion with Attention Consistency module. For automatic pseudo-labeling of unlabeled samples, we introduce a novel Mask Validity Filtering routine based on a spatially aware zero-shot proposal scoring approach. Extensive experiments show that with just 30% annotations, our model SafaRi achieves 59.31 and 48.26 mIoUs as compared to 58.93 and 48.19 mIoUs obtained by the fully-supervised SOTA method SeqTR respectively on RefCOCO+@testA and RefCOCO+testB datasets. SafaRi also outperforms SeqTR by 11.7% (on RefCOCO+testA) and 19.6% (on RefCOCO+testB) in a fully-supervised setting and demonstrates strong generalization capabilities in unseen/zero-shot tasks.
Meerkat: Audio-Visual Large Language Model for Grounding in Space and Time
Jul 01, 2024Leveraging Large Language Models' remarkable proficiency in text-based tasks, recent works on Multi-modal LLMs (MLLMs) extend them to other modalities like vision and audio. However, the progress in these directions has been mostly focused on tasks that only require a coarse-grained understanding of the audio-visual semantics. We present Meerkat, an audio-visual LLM equipped with a fine-grained understanding of image and audio both spatially and temporally. With a new modality alignment module based on optimal transport and a cross-attention module that enforces audio-visual consistency, Meerkat can tackle challenging tasks such as audio referred image grounding, image guided audio temporal localization, and audio-visual fact-checking. Moreover, we carefully curate a large dataset AVFIT that comprises 3M instruction tuning samples collected from open-source datasets, and introduce MeerkatBench that unifies five challenging audio-visual tasks. We achieve state-of-the-art performance on all these downstream tasks with a relative improvement of up to 37.12%.