 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Paper and Code
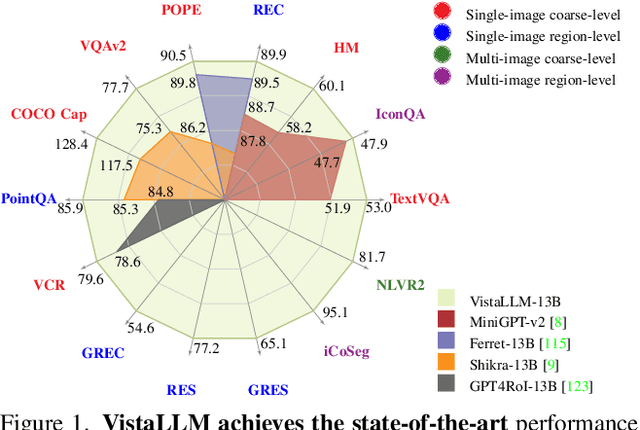
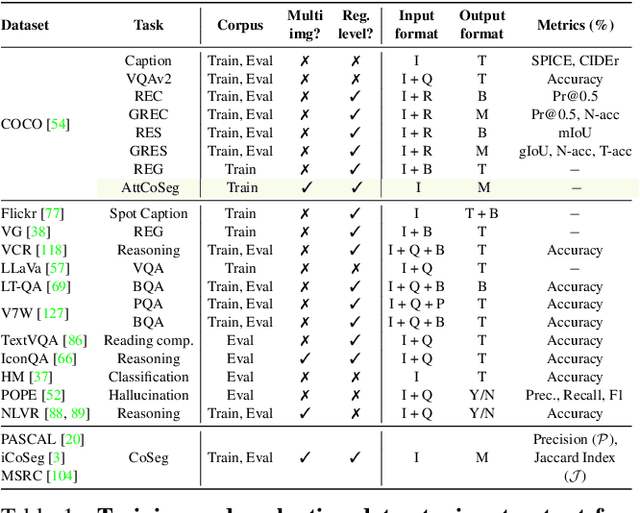
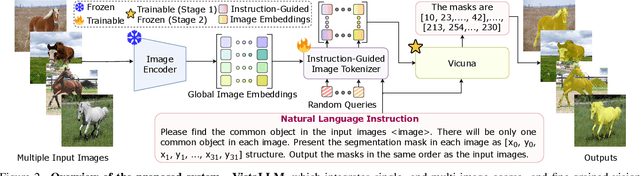

The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.