 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciFig: Towards Automating Scientific Figure Generation
Jan 07, 2026Creating high-quality figures and visualizations for scientific papers is a time-consuming task that requires both deep domain knowledge and professional design skills. Despite over 2.5 million scientific papers published annually, the figure generation process remains largely manual. We introduce $\textbf{SciFig}$, an end-to-end AI agent system that generates publication-ready pipeline figures directly from research paper texts. SciFig uses a hierarchical layout generation strategy, which parses research descriptions to identify component relationships, groups related elements into functional modules, and generates inter-module connections to establish visual organization. Furthermore, an iterative chain-of-thought (CoT) feedback mechanism progressively improves layouts through multiple rounds of visual analysis and reasoning. We introduce a rubric-based evaluation framework that analyzes 2,219 real scientific figures to extract evaluation rubrics and automatically generates comprehensive evaluation criteria. SciFig demonstrates remarkable performance: achieving 70.1$\%$ overall quality on dataset-level evaluation and 66.2$\%$ on paper-specific evaluation, and consistently high scores across metrics such as visual clarity, structural organization, and scientific accuracy. SciFig figure generation pipeline and our evaluation benchmark will be open-sourced.
SPIQA: A Dataset for Multimodal Question Answering on Scientific Papers
Jul 12, 2024
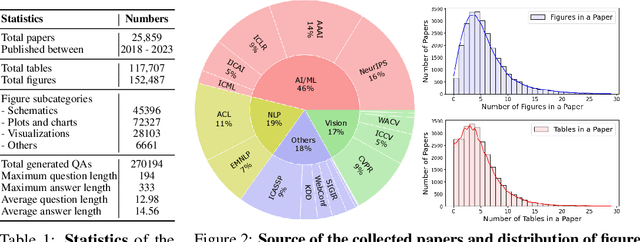

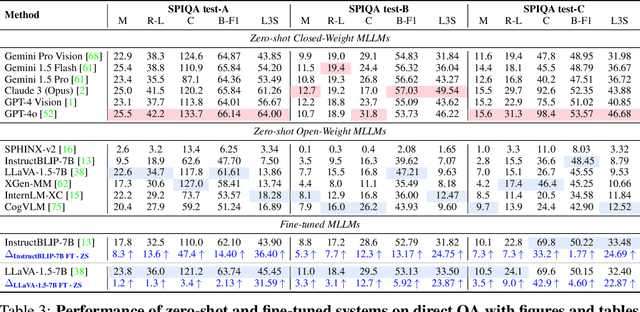
Seeking answers to questions within long scientific research articles is a crucial area of study that aids readers in quickly addressing their inquiries. However, existing question-answering (QA) datasets based on scientific papers are limited in scale and focus solely on textual content. To address this limitation, we introduce SPIQA (Scientific Paper Image Question Answering), the first large-scale QA dataset specifically designed to interpret complex figures and tables within the context of scientific research articles across various domains of computer science. Leveraging the breadth of expertise and ability of multimodal large language models (MLLMs) to understand figures, we employ automatic and manual curation to create the dataset. We craft an information-seeking task involving multiple images that cover a wide variety of plots, charts, tables, schematic diagrams, and result visualizations. SPIQA comprises 270K questions divided into training, validation, and three different evaluation splits. Through extensive experiments with 12 prominent foundational models, we evaluate the ability of current multimodal systems to comprehend the nuanced aspects of research articles. Additionally, we propose a Chain-of-Thought (CoT) evaluation strategy with in-context retrieval that allows fine-grained, step-by-step assessment and improves model performance. We further explore the upper bounds of performance enhancement with additional textual information, highlighting its promising potential for future research and the dataset's impact on revolutionizing how we interact with scientific literature.
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Dec 19, 2023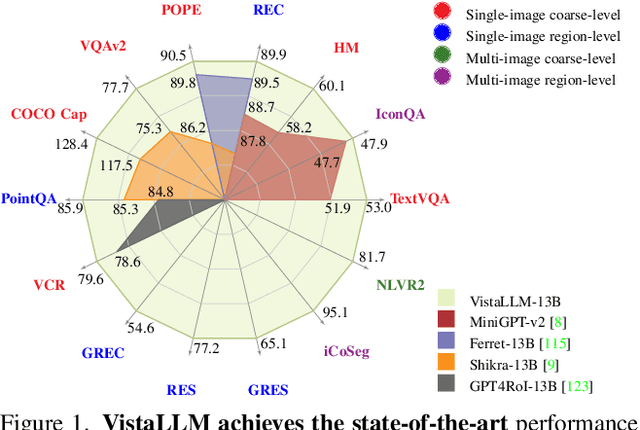
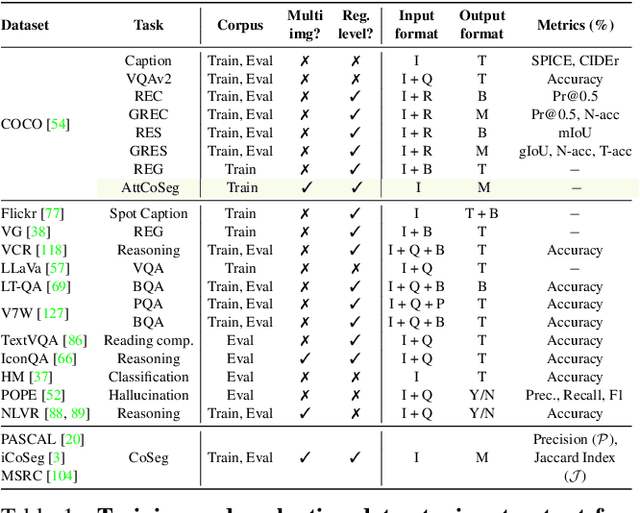
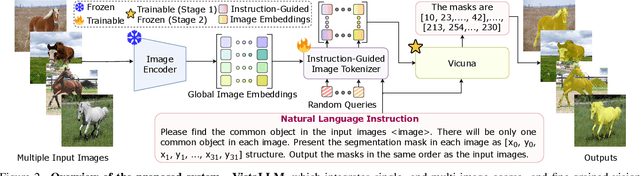

The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
UniVTG: Towards Unified Video-Language Temporal Grounding
Aug 18, 2023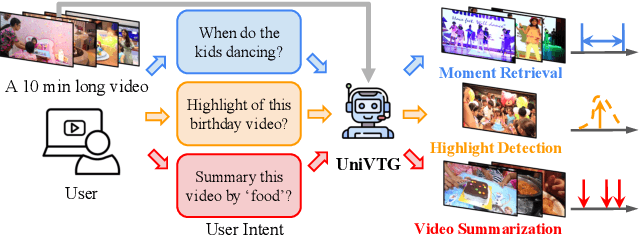
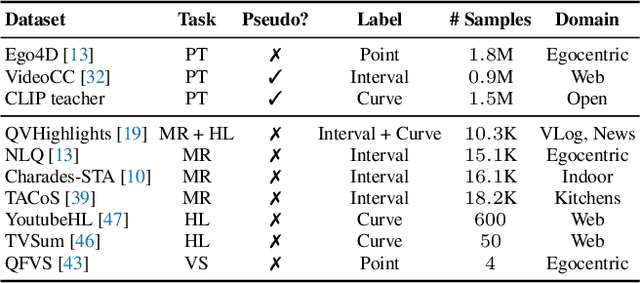
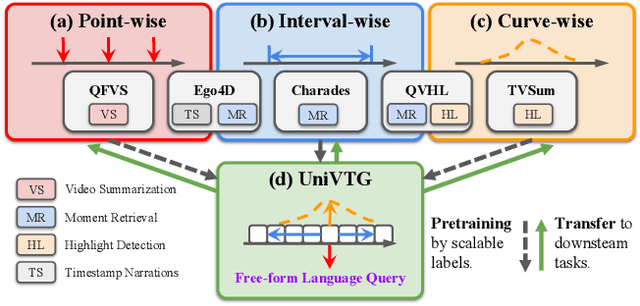

Video Temporal Grounding (VTG), which aims to ground target clips from videos (such as consecutive intervals or disjoint shots) according to custom language queries (e.g., sentences or words), is key for video browsing on social media. Most methods in this direction develop taskspecific models that are trained with type-specific labels, such as moment retrieval (time interval) and highlight detection (worthiness curve), which limits their abilities to generalize to various VTG tasks and labels. In this paper, we propose to Unify the diverse VTG labels and tasks, dubbed UniVTG, along three directions: Firstly, we revisit a wide range of VTG labels and tasks and define a unified formulation. Based on this, we develop data annotation schemes to create scalable pseudo supervision. Secondly, we develop an effective and flexible grounding model capable of addressing each task and making full use of each label. Lastly, thanks to the unified framework, we are able to unlock temporal grounding pretraining from large-scale diverse labels and develop stronger grounding abilities e.g., zero-shot grounding. Extensive experiments on three tasks (moment retrieval, highlight detection and video summarization) across seven datasets (QVHighlights, Charades-STA, TACoS, Ego4D, YouTube Highlights, TVSum, and QFVS) demonstrate the effectiveness and flexibility of our proposed framework. The codes are available at https://github.com/showlab/UniVTG.
EgoVLPv2: Egocentric Video-Language Pre-training with Fusion in the Backbone
Jul 11, 2023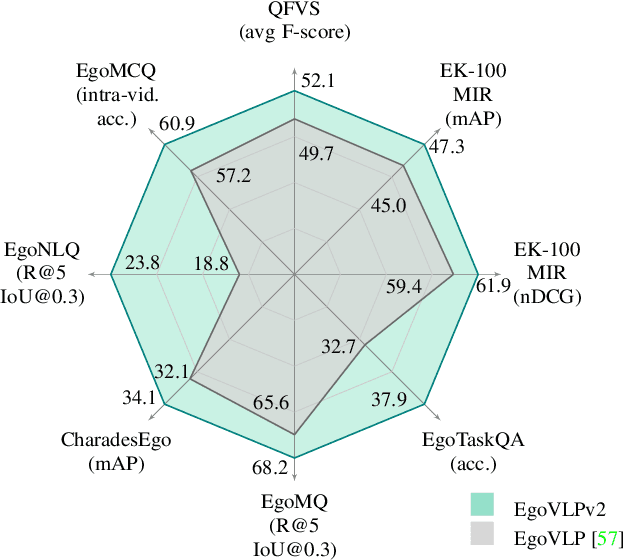


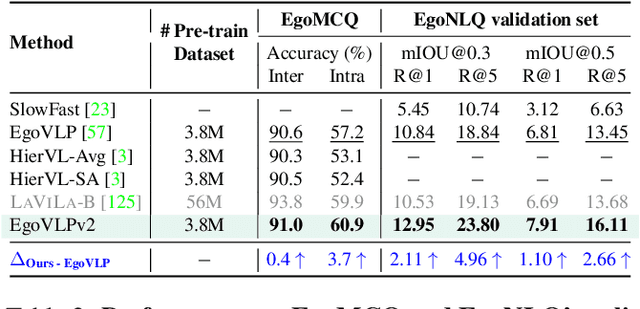
Video-language pre-training (VLP) has become increasingly important due to its ability to generalize to various vision and language tasks. However, existing egocentric VLP frameworks utilize separate video and language encoders and learn task-specific cross-modal information only during fine-tuning, limiting the development of a unified system. In this work, we introduce the second generation of egocentric video-language pre-training (EgoVLPv2), a significant improvement from the previous generation, by incorporating cross-modal fusion directly into the video and language backbones. EgoVLPv2 learns strong video-text representation during pre-training and reuses the cross-modal attention modules to support different downstream tasks in a flexible and efficient manner, reducing fine-tuning costs. Moreover, our proposed fusion in the backbone strategy is more lightweight and compute-efficient than stacking additional fusion-specific layers. Extensive experiments on a wide range of VL tasks demonstrate the effectiveness of EgoVLPv2 by achieving consistent state-of-the-art performance over strong baselines across all downstream. Our project page can be found at https://shramanpramanick.github.io/EgoVLPv2/.
VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment
Oct 09, 2022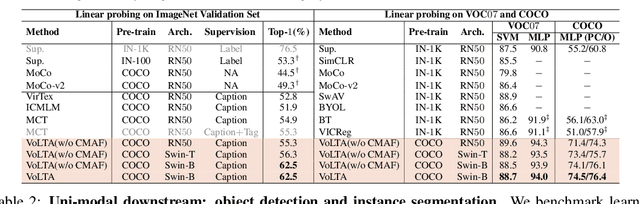
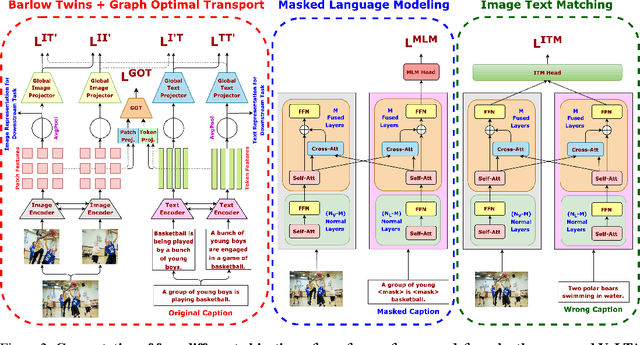
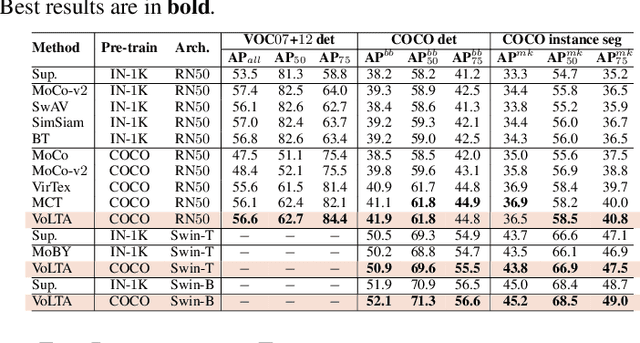

Vision-language pre-training (VLP) has recently proven highly effective for various uni- and multi-modal downstream applications. However, most existing end-to-end VLP methods use high-resolution image-text box data to perform well on fine-grained region-level tasks, such as object detection, segmentation, and referring expression comprehension. Unfortunately, such high-resolution images with accurate bounding box annotations are expensive to collect and use for supervision at scale. In this work, we propose VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new VLP paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the use of expensive box annotations. VoLTA adopts graph optimal transport-based weakly-supervised alignment on local image patches and text tokens to germinate an explicit, self-normalized, and interpretable low-level matching criterion. In addition, VoLTA pushes multi-modal fusion deep into the uni-modal backbones during pre-training and removes fusion-specific transformer layers, further reducing memory requirements. Extensive experiments on a wide range of vision- and vision-language downstream tasks demonstrate the effectiveness of VoLTA on fine-grained applications without compromising the coarse-grained downstream performance, often outperforming methods using significantly more caption and box annotations.
Where in the World is this Image? Transformer-based Geo-localization in the Wild
Apr 29, 2022
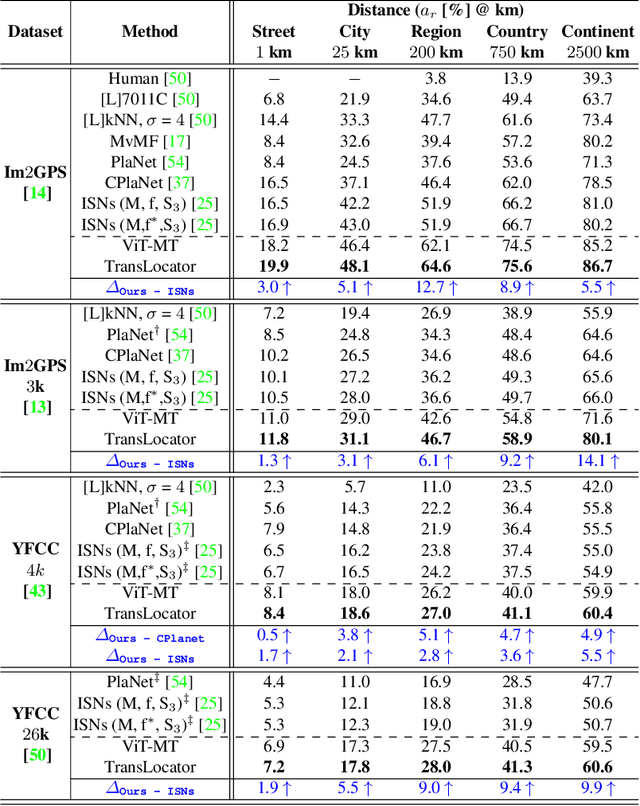
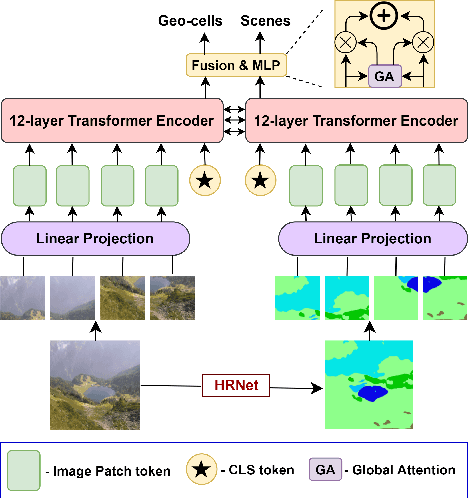
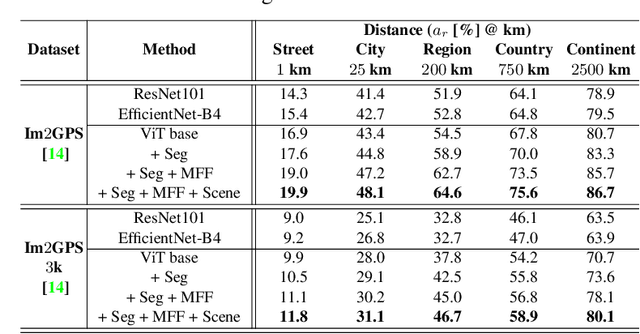
Predicting the geographic location (geo-localization) from a single ground-level RGB image taken anywhere in the world is a very challenging problem. The challenges include huge diversity of images due to different environmental scenarios, drastic variation in the appearance of the same location depending on the time of the day, weather, season, and more importantly, the prediction is made from a single image possibly having only a few geo-locating cues. For these reasons, most existing works are restricted to specific cities, imagery, or worldwide landmarks. In this work, we focus on developing an efficient solution to planet-scale single-image geo-localization. To this end, we propose TransLocator, a unified dual-branch transformer network that attends to tiny details over the entire image and produces robust feature representation under extreme appearance variations. TransLocator takes an RGB image and its semantic segmentation map as inputs, interacts between its two parallel branches after each transformer layer, and simultaneously performs geo-localization and scene recognition in a multi-task fashion. We evaluate TransLocator on four benchmark datasets - Im2GPS, Im2GPS3k, YFCC4k, YFCC26k and obtain 5.5%, 14.1%, 4.9%, 9.9% continent-level accuracy improvement over the state-of-the-art. TransLocator is also validated on real-world test images and found to be more effective than previous methods.
Multimodal Learning using Optimal Transport for Sarcasm and Humor Detection
Oct 21, 2021
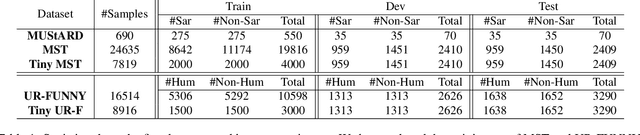
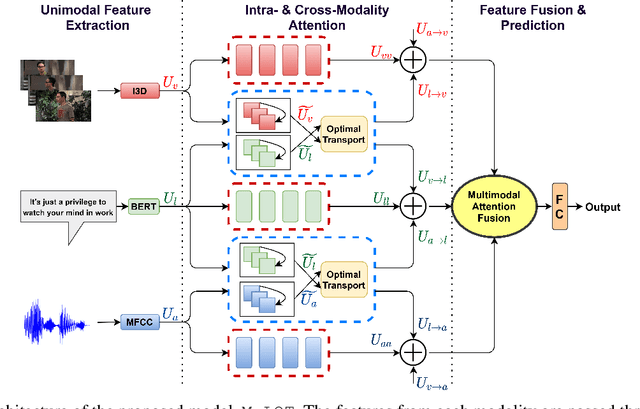
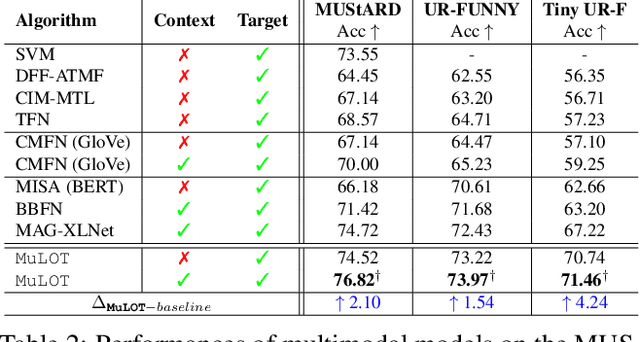
Multimodal learning is an emerging yet challenging research area. In this paper, we deal with multimodal sarcasm and humor detection from conversational videos and image-text pairs. Being a fleeting action, which is reflected across the modalities, sarcasm detection is challenging since large datasets are not available for this task in the literature. Therefore, we primarily focus on resource-constrained training, where the number of training samples is limited. To this end, we propose a novel multimodal learning system, MuLOT (Multimodal Learning using Optimal Transport), which utilizes self-attention to exploit intra-modal correspondence and optimal transport for cross-modal correspondence. Finally, the modalities are combined with multimodal attention fusion to capture the inter-dependencies across modalities. We test our approach for multimodal sarcasm and humor detection on three benchmark datasets - MUStARD (video, audio, text), UR-FUNNY (video, audio, text), MST (image, text) and obtain 2.1%, 1.54%, and 2.34% accuracy improvements over state-of-the-art.
Detecting Harmful Memes and Their Targets
Sep 24, 2021
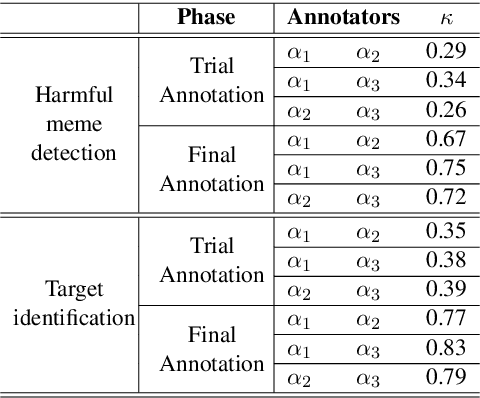

Among the various modes of communication in social media, the use of Internet memes has emerged as a powerful means to convey political, psychological, and socio-cultural opinions. Although memes are typically humorous in nature, recent days have witnessed a proliferation of harmful memes targeted to abuse various social entities. As most harmful memes are highly satirical and abstruse without appropriate contexts, off-the-shelf multimodal models may not be adequate to understand their underlying semantics. In this work, we propose two novel problem formulations: detecting harmful memes and the social entities that these harmful memes target. To this end, we present HarMeme, the first benchmark dataset, containing 3,544 memes related to COVID-19. Each meme went through a rigorous two-stage annotation process. In the first stage, we labeled a meme as very harmful, partially harmful, or harmless; in the second stage, we further annotated the type of target(s) that each harmful meme points to: individual, organization, community, or society/general public/other. The evaluation results using ten unimodal and multimodal models highlight the importance of using multimodal signals for both tasks. We further discuss the limitations of these models and we argue that more research is needed to address these problems.
* harmful memes, multimodality, social media