 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Learning using Optimal Transport for Sarcasm and Humor Detection
Paper and Code
Oct 21, 2021
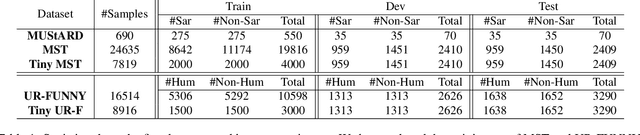
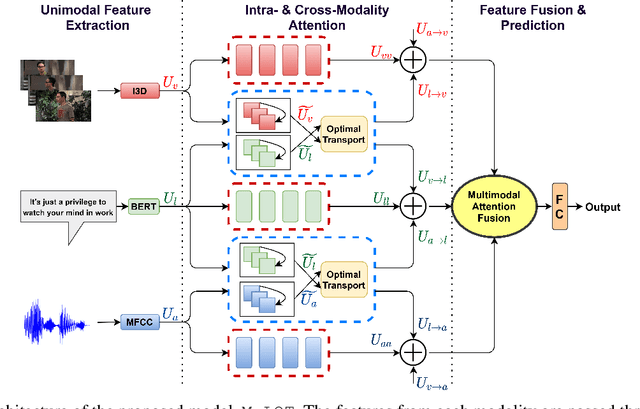
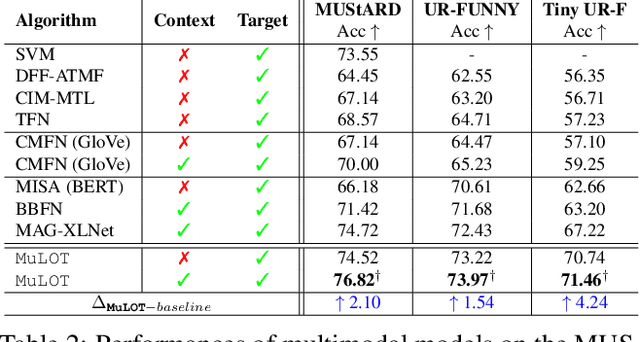
Multimodal learning is an emerging yet challenging research area. In this paper, we deal with multimodal sarcasm and humor detection from conversational videos and image-text pairs. Being a fleeting action, which is reflected across the modalities, sarcasm detection is challenging since large datasets are not available for this task in the literature. Therefore, we primarily focus on resource-constrained training, where the number of training samples is limited. To this end, we propose a novel multimodal learning system, MuLOT (Multimodal Learning using Optimal Transport), which utilizes self-attention to exploit intra-modal correspondence and optimal transport for cross-modal correspondence. Finally, the modalities are combined with multimodal attention fusion to capture the inter-dependencies across modalities. We test our approach for multimodal sarcasm and humor detection on three benchmark datasets - MUStARD (video, audio, text), UR-FUNNY (video, audio, text), MST (image, text) and obtain 2.1%, 1.54%, and 2.34% accuracy improvements over state-of-the-art.