 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKC-3DGS: Kurtosis-Constrained Gaussian Splatting for High-Fidelity View Synthesis
Jun 02, 20263D Gaussian Splatting (3DGS) enables real-time novel view synthesis by representing scenes as collections of anisotropic Gaussians optimized via differentiable rasterization. However, standard pixel-space losses (L1, SSIM) constrain only aggregate reconstruction error, permitting the optimization to redistribute error across frequency scales. This leads to oversmoothing and structural artifacts, particularly in sparse-view settings where supervision is limited. We propose KC-3DGS, which augments 3DGS training with wavelet-domain supervision based on natural image statistics. Our method combines three components: (1) a multi-scale wavelet coefficient alignment loss that explicitly penalizes missing high-frequency detail, (2) a supervised kurtosis concentration loss that encourages rendered images to match the heavy-tailed frequency statistics of ground-truth images, and (3) a cross-band covariance penalty that promotes frequency specialization. We provide theoretical analysis showing that pixel-space losses admit a family of indistinguishable perturbations under wavelet redistribution, and that our joint objective excludes degenerate solutions. Experiments across MipNeRF360, Tanks&Temples, MVImgNet, DeepBlending, and WRIVA-ULTRRA demonstrate consistent improvements in perceptual quality. On the challenging WRIVA-ULTRRA outdoor dataset, KC-3DGS achieves a 9.48% improvement in DreamSim while also improving PSNR, SSIM, and LPIPS. In sparse-view settings with only 12 training images, our method improves PSNR by up to 0.5 dB on MipNeRF360 while maintaining perceptual quality. The approach integrates seamlessly into existing 3DGS pipelines as a plug-and-play regularization strategy.
Zero-Shot Personalization of Objects via Textual Inversion
Mar 24, 2026Recent advances in text-to-image diffusion models have substantially improved the quality of image customization, enabling the synthesis of highly realistic images. Despite this progress, achieving fast and efficient personalization remains a key challenge, particularly for real-world applications. Existing approaches primarily accelerate customization for human subjects by injecting identity-specific embeddings into diffusion models, but these strategies do not generalize well to arbitrary object categories, limiting their applicability. To address this limitation, we propose a novel framework that employs a learned network to predict object-specific textual inversion embeddings, which are subsequently integrated into the UNet timesteps of a diffusion model for text-conditional customization. This design enables rapid, zero-shot personalization of a wide range of objects in a single forward pass, offering both flexibility and scalability. Extensive experiments across multiple tasks and settings demonstrate the effectiveness of our approach, highlighting its potential to support fast, versatile, and inclusive image customization. To the best of our knowledge, this work represents the first attempt to achieve such general-purpose, training-free personalization within diffusion models, paving the way for future research in personalized image generation.
MultLFG: Training-free Multi-LoRA composition using Frequency-domain Guidance
May 26, 2025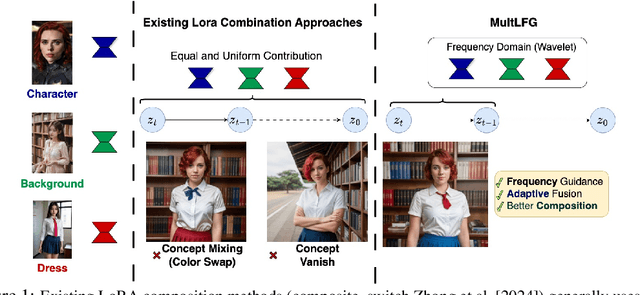
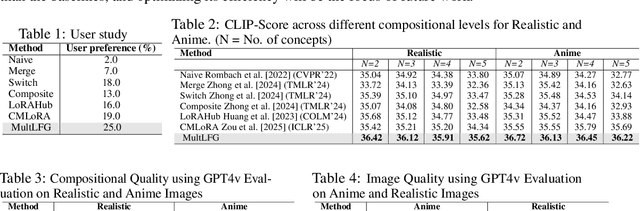
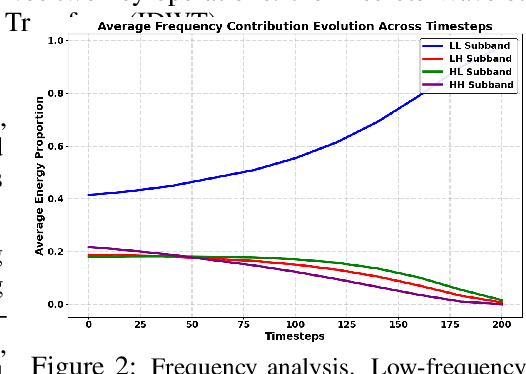
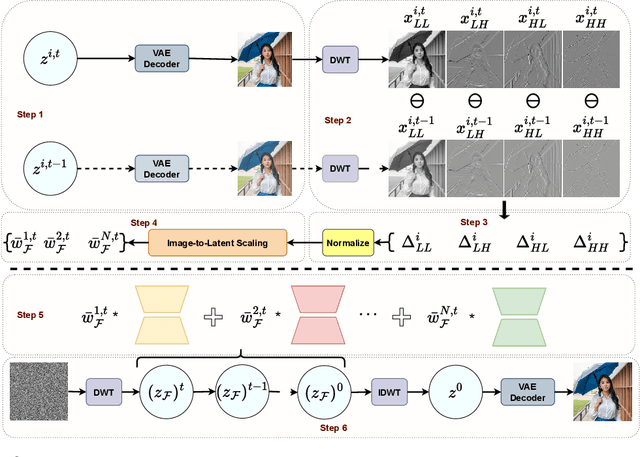
Low-Rank Adaptation (LoRA) has gained prominence as a computationally efficient method for fine-tuning generative models, enabling distinct visual concept synthesis with minimal overhead. However, current methods struggle to effectively merge multiple LoRA adapters without training, particularly in complex compositions involving diverse visual elements. We introduce MultLFG, a novel framework for training-free multi-LoRA composition that utilizes frequency-domain guidance to achieve adaptive fusion of multiple LoRAs. Unlike existing methods that uniformly aggregate concept-specific LoRAs, MultLFG employs a timestep and frequency subband adaptive fusion strategy, selectively activating relevant LoRAs based on content relevance at specific timesteps and frequency bands. This frequency-sensitive guidance not only improves spatial coherence but also provides finer control over multi-LoRA composition, leading to more accurate and consistent results. Experimental evaluations on the ComposLoRA benchmark reveal that MultLFG substantially enhances compositional fidelity and image quality across various styles and concept sets, outperforming state-of-the-art baselines in multi-concept generation tasks. Code will be released.
BRI3L: A Brightness Illusion Image Dataset for Identification and Localization of Regions of Illusory Perception
Feb 07, 2024Visual illusions play a significant role in understanding visual perception. Current methods in understanding and evaluating visual illusions are mostly deterministic filtering based approach and they evaluate on a handful of visual illusions, and the conclusions therefore, are not generic. To this end, we generate a large-scale dataset of 22,366 images (BRI3L: BRightness Illusion Image dataset for Identification and Localization of illusory perception) of the five types of brightness illusions and benchmark the dataset using data-driven neural network based approaches. The dataset contains label information - (1) whether a particular image is illusory/nonillusory, (2) the segmentation mask of the illusory region of the image. Hence, both the classification and segmentation task can be evaluated using this dataset. We follow the standard psychophysical experiments involving human subjects to validate the dataset. To the best of our knowledge, this is the first attempt to develop a dataset of visual illusions and benchmark using data-driven approach for illusion classification and localization. We consider five well-studied types of brightness illusions: 1) Hermann grid, 2) Simultaneous Brightness Contrast, 3) White illusion, 4) Grid illusion, and 5) Induced Grating illusion. Benchmarking on the dataset achieves 99.56% accuracy in illusion identification and 84.37% pixel accuracy in illusion localization. The application of deep learning model, it is shown, also generalizes over unseen brightness illusions like brightness assimilation to contrast transitions. We also test the ability of state-of-theart diffusion models to generate brightness illusions. We have provided all the code, dataset, instructions etc in the github repo: https://github.com/aniket004/BRI3L
DIFFNAT: Improving Diffusion Image Quality Using Natural Image Statistics
Nov 16, 2023



Diffusion models have advanced generative AI significantly in terms of editing and creating naturalistic images. However, efficiently improving generated image quality is still of paramount interest. In this context, we propose a generic "naturalness" preserving loss function, viz., kurtosis concentration (KC) loss, which can be readily applied to any standard diffusion model pipeline to elevate the image quality. Our motivation stems from the projected kurtosis concentration property of natural images, which states that natural images have nearly constant kurtosis values across different band-pass versions of the image. To retain the "naturalness" of the generated images, we enforce reducing the gap between the highest and lowest kurtosis values across the band-pass versions (e.g., Discrete Wavelet Transform (DWT)) of images. Note that our approach does not require any additional guidance like classifier or classifier-free guidance to improve the image quality. We validate the proposed approach for three diverse tasks, viz., (1) personalized few-shot finetuning using text guidance, (2) unconditional image generation, and (3) image super-resolution. Integrating the proposed KC loss has improved the perceptual quality across all these tasks in terms of both FID, MUSIQ score, and user evaluation.
Certified Robustness via Dynamic Margin Maximization and Improved Lipschitz Regularization
Sep 29, 2023To improve the robustness of deep classifiers against adversarial perturbations, many approaches have been proposed, such as designing new architectures with better robustness properties (e.g., Lipschitz-capped networks), or modifying the training process itself (e.g., min-max optimization, constrained learning, or regularization). These approaches, however, might not be effective at increasing the margin in the input (feature) space. As a result, there has been an increasing interest in developing training procedures that can directly manipulate the decision boundary in the input space. In this paper, we build upon recent developments in this category by developing a robust training algorithm whose objective is to increase the margin in the output (logit) space while regularizing the Lipschitz constant of the model along vulnerable directions. We show that these two objectives can directly promote larger margins in the input space. To this end, we develop a scalable method for calculating guaranteed differentiable upper bounds on the Lipschitz constant of neural networks accurately and efficiently. The relative accuracy of the bounds prevents excessive regularization and allows for more direct manipulation of the decision boundary. Furthermore, our Lipschitz bounding algorithm exploits the monotonicity and Lipschitz continuity of the activation layers, and the resulting bounds can be used to design new layers with controllable bounds on their Lipschitz constant. Experiments on the MNIST, CIFAR-10, and Tiny-ImageNet data sets verify that our proposed algorithm obtains competitively improved results compared to the state-of-the-art.
HaLP: Hallucinating Latent Positives for Skeleton-based Self-Supervised Learning of Actions
Apr 01, 2023Supervised learning of skeleton sequence encoders for action recognition has received significant attention in recent times. However, learning such encoders without labels continues to be a challenging problem. While prior works have shown promising results by applying contrastive learning to pose sequences, the quality of the learned representations is often observed to be closely tied to data augmentations that are used to craft the positives. However, augmenting pose sequences is a difficult task as the geometric constraints among the skeleton joints need to be enforced to make the augmentations realistic for that action. In this work, we propose a new contrastive learning approach to train models for skeleton-based action recognition without labels. Our key contribution is a simple module, HaLP - to Hallucinate Latent Positives for contrastive learning. Specifically, HaLP explores the latent space of poses in suitable directions to generate new positives. To this end, we present a novel optimization formulation to solve for the synthetic positives with an explicit control on their hardness. We propose approximations to the objective, making them solvable in closed form with minimal overhead. We show via experiments that using these generated positives within a standard contrastive learning framework leads to consistent improvements across benchmarks such as NTU-60, NTU-120, and PKU-II on tasks like linear evaluation, transfer learning, and kNN evaluation. Our code will be made available at https://github.com/anshulbshah/HaLP.
DiffAlign : Few-shot learning using diffusion based synthesis and alignment
Dec 11, 2022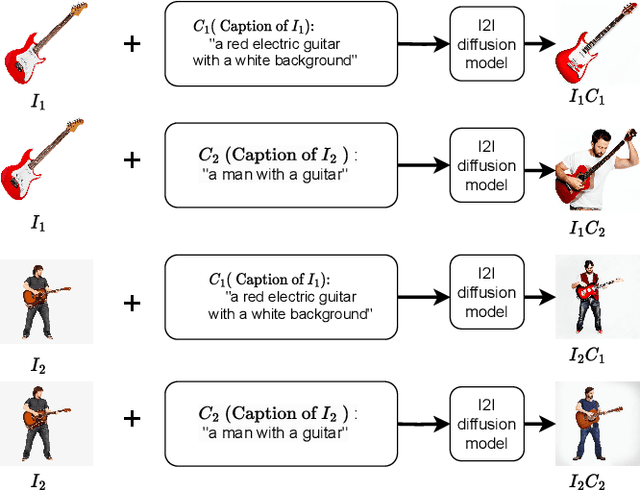
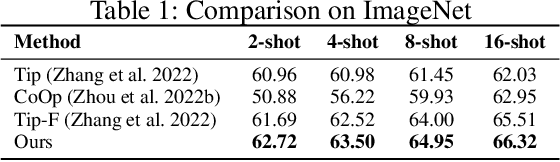
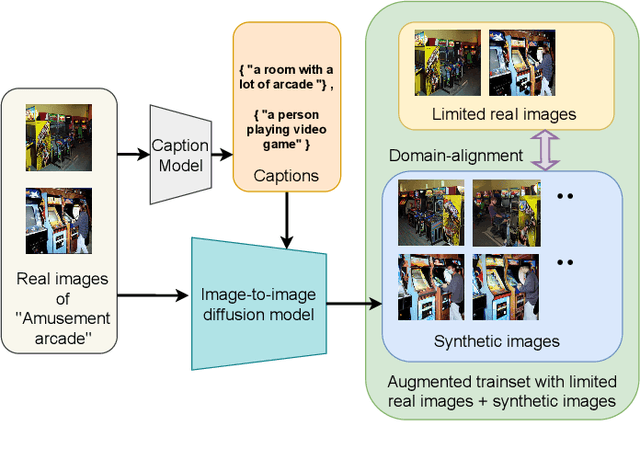
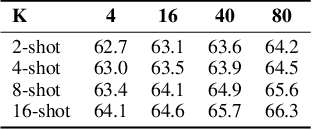
We address the problem of few-shot classification where the goal is to learn a classifier from a limited set of samples. While data-driven learning is shown to be effective in various applications, learning from less data still remains challenging. To address this challenge, existing approaches consider various data augmentation techniques for increasing the number of training samples. Pseudo-labeling is commonly used in a few-shot setup, where approximate labels are estimated for a large set of unlabeled images. We propose DiffAlign which focuses on generating images from class labels. Specifically, we leverage the recent success of the generative models (e.g., DALL-E and diffusion models) that can generate realistic images from texts. However, naive learning on synthetic images is not adequate due to the domain gap between real and synthetic images. Thus, we employ a maximum mean discrepancy (MMD) loss to align the synthetic images to the real images minimizing the domain gap. We evaluate our method on the standard few-shot classification benchmarks: CIFAR-FS, FC100, miniImageNet, tieredImageNet and a cross-domain few-shot classification benchmark: miniImageNet to CUB. The proposed approach significantly outperforms the stateof-the-art in both 5-shot and 1-shot setups on these benchmarks. Our approach is also shown to be effective in the zero-shot classification setup
Distill and De-bias: Mitigating Bias in Face Recognition using Knowledge Distillation
Dec 17, 2021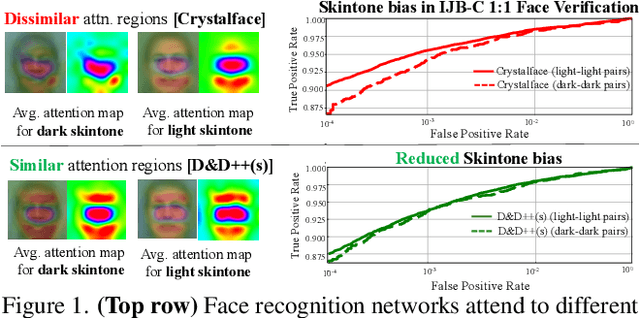
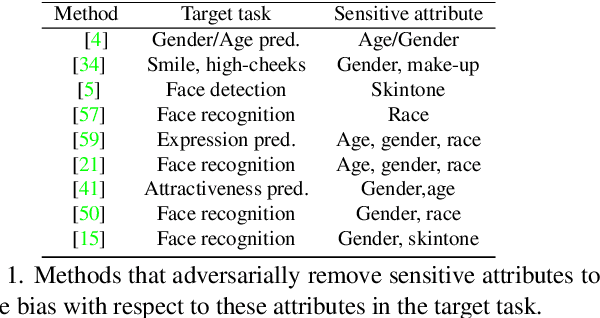
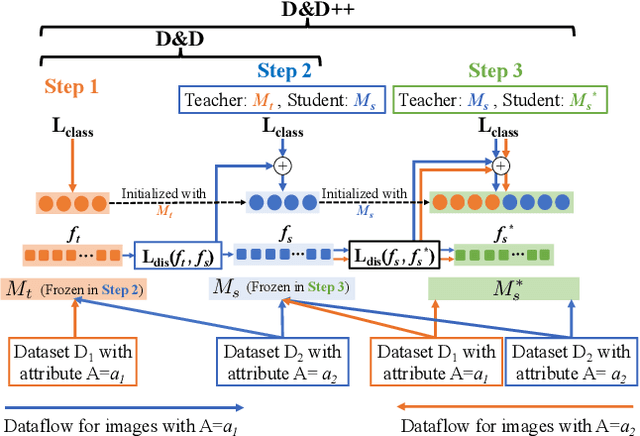
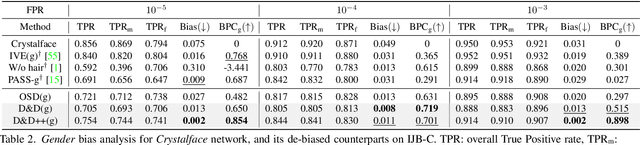
Face recognition networks generally demonstrate bias with respect to sensitive attributes like gender, skintone etc. For gender and skintone, we observe that the regions of the face that a network attends to vary by the category of an attribute. This might contribute to bias. Building on this intuition, we propose a novel distillation-based approach called Distill and De-bias (D&D) to enforce a network to attend to similar face regions, irrespective of the attribute category. In D&D, we train a teacher network on images from one category of an attribute; e.g. light skintone. Then distilling information from the teacher, we train a student network on images of the remaining category; e.g., dark skintone. A feature-level distillation loss constrains the student network to generate teacher-like representations. This allows the student network to attend to similar face regions for all attribute categories and enables it to reduce bias. We also propose a second distillation step on top of D&D, called D&D++. For the D&D++ network, we distill the `un-biasedness' of the D&D network into a new student network, the D&D++ network. We train the new network on all attribute categories; e.g., both light and dark skintones. This helps us train a network that is less biased for an attribute, while obtaining higher face verification performance than D&D. We show that D&D++ outperforms existing baselines in reducing gender and skintone bias on the IJB-C dataset, while obtaining higher face verification performance than existing adversarial de-biasing methods. We evaluate the effectiveness of our proposed methods on two state-of-the-art face recognition networks: Crystalface and ArcFace.
Multimodal Learning using Optimal Transport for Sarcasm and Humor Detection
Oct 21, 2021
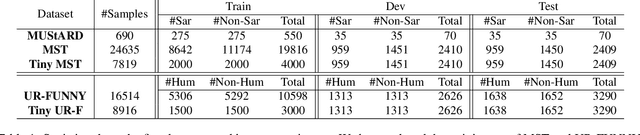
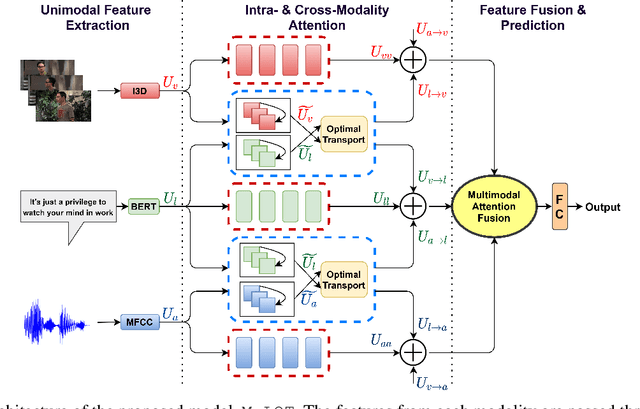
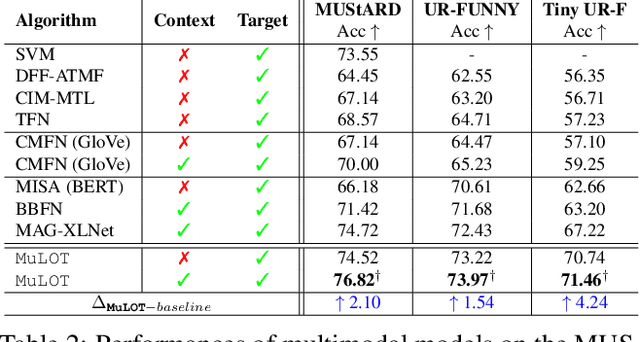
Multimodal learning is an emerging yet challenging research area. In this paper, we deal with multimodal sarcasm and humor detection from conversational videos and image-text pairs. Being a fleeting action, which is reflected across the modalities, sarcasm detection is challenging since large datasets are not available for this task in the literature. Therefore, we primarily focus on resource-constrained training, where the number of training samples is limited. To this end, we propose a novel multimodal learning system, MuLOT (Multimodal Learning using Optimal Transport), which utilizes self-attention to exploit intra-modal correspondence and optimal transport for cross-modal correspondence. Finally, the modalities are combined with multimodal attention fusion to capture the inter-dependencies across modalities. We test our approach for multimodal sarcasm and humor detection on three benchmark datasets - MUStARD (video, audio, text), UR-FUNNY (video, audio, text), MST (image, text) and obtain 2.1%, 1.54%, and 2.34% accuracy improvements over state-of-the-art.