 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robustness and Chain-of-Thought Consistency of RL-Finetuned VLMs
Feb 13, 2026Reinforcement learning (RL) fine-tuning has become a key technique for enhancing large language models (LLMs) on reasoning-intensive tasks, motivating its extension to vision language models (VLMs). While RL-tuned VLMs improve on visual reasoning benchmarks, they remain vulnerable to weak visual grounding, hallucinations, and over-reliance on textual cues. We show that simple, controlled textual perturbations--misleading captions or incorrect chain-of-thought (CoT) traces--cause substantial drops in robustness and confidence, and that these effects are more pronounced when CoT consistency is taken into account across open-source multimodal reasoning models. Entropy-based metrics further show that these perturbations reshape model uncertainty and probability mass on the correct option, exposing model-specific trends in miscalibration. To better understand these vulnerabilities, we further analyze RL fine-tuning dynamics and uncover an accuracy-faithfulness trade-off: fine-tuning raises benchmark accuracy, but can simultaneously erode the reliability of the accompanying CoT and its robustness to contextual shifts. Although adversarial augmentation improves robustness, it does not by itself prevent faithfulness drift. Incorporating a faithfulness-aware reward can restore alignment between answers and reasoning, but when paired with augmentation, training risks collapsing onto shortcut strategies and robustness remains elusive. Together, these findings highlight the limitations of accuracy-only evaluations and motivate training and assessment protocols that jointly emphasize correctness, robustness, and the faithfulness of visually grounded reasoning.
GaitContour: Efficient Gait Recognition based on a Contour-Pose Representation
Nov 27, 2023Gait recognition holds the promise to robustly identify subjects based on walking patterns instead of appearance information. In recent years, this field has been dominated by learning methods based on two principal input representations: dense silhouette masks or sparse pose keypoints. In this work, we propose a novel, point-based Contour-Pose representation, which compactly expresses both body shape and body parts information. We further propose a local-to-global architecture, called GaitContour, to leverage this novel representation and efficiently compute subject embedding in two stages. The first stage consists of a local transformer that extracts features from five different body regions. The second stage then aggregates the regional features to estimate a global human gait representation. Such a design significantly reduces the complexity of the attention operation and improves efficiency and performance simultaneously. Through large scale experiments, GaitContour is shown to perform significantly better than previous point-based methods, while also being significantly more efficient than silhouette-based methods. On challenging datasets with significant distractors, GaitContour can even outperform silhouette-based methods.
DIFFNAT: Improving Diffusion Image Quality Using Natural Image Statistics
Nov 16, 2023



Diffusion models have advanced generative AI significantly in terms of editing and creating naturalistic images. However, efficiently improving generated image quality is still of paramount interest. In this context, we propose a generic "naturalness" preserving loss function, viz., kurtosis concentration (KC) loss, which can be readily applied to any standard diffusion model pipeline to elevate the image quality. Our motivation stems from the projected kurtosis concentration property of natural images, which states that natural images have nearly constant kurtosis values across different band-pass versions of the image. To retain the "naturalness" of the generated images, we enforce reducing the gap between the highest and lowest kurtosis values across the band-pass versions (e.g., Discrete Wavelet Transform (DWT)) of images. Note that our approach does not require any additional guidance like classifier or classifier-free guidance to improve the image quality. We validate the proposed approach for three diverse tasks, viz., (1) personalized few-shot finetuning using text guidance, (2) unconditional image generation, and (3) image super-resolution. Integrating the proposed KC loss has improved the perceptual quality across all these tasks in terms of both FID, MUSIQ score, and user evaluation.
Dual Prompt Tuning for Domain-Aware Federated Learning
Oct 04, 2023



Federated learning is a distributed machine learning paradigm that allows multiple clients to collaboratively train a shared model with their local data. Nonetheless, conventional federated learning algorithms often struggle to generalize well due to the ubiquitous domain shift across clients. In this work, we consider a challenging yet realistic federated learning scenario where the training data of each client originates from different domains. We address the challenges of domain shift by leveraging the technique of prompt learning, and propose a novel method called Federated Dual Prompt Tuning (Fed-DPT). Specifically, Fed-DPT employs a pre-trained vision-language model and then applies both visual and textual prompt tuning to facilitate domain adaptation over decentralized data. Extensive experiments of Fed-DPT demonstrate its significant effectiveness in domain-aware federated learning. With a pre-trained CLIP model (ViT-Base as image encoder), the proposed Fed-DPT attains 68.4% average accuracy over six domains in the DomainNet dataset, which improves the original CLIP by a large margin of 14.8%.
HaLP: Hallucinating Latent Positives for Skeleton-based Self-Supervised Learning of Actions
Apr 01, 2023Supervised learning of skeleton sequence encoders for action recognition has received significant attention in recent times. However, learning such encoders without labels continues to be a challenging problem. While prior works have shown promising results by applying contrastive learning to pose sequences, the quality of the learned representations is often observed to be closely tied to data augmentations that are used to craft the positives. However, augmenting pose sequences is a difficult task as the geometric constraints among the skeleton joints need to be enforced to make the augmentations realistic for that action. In this work, we propose a new contrastive learning approach to train models for skeleton-based action recognition without labels. Our key contribution is a simple module, HaLP - to Hallucinate Latent Positives for contrastive learning. Specifically, HaLP explores the latent space of poses in suitable directions to generate new positives. To this end, we present a novel optimization formulation to solve for the synthetic positives with an explicit control on their hardness. We propose approximations to the objective, making them solvable in closed form with minimal overhead. We show via experiments that using these generated positives within a standard contrastive learning framework leads to consistent improvements across benchmarks such as NTU-60, NTU-120, and PKU-II on tasks like linear evaluation, transfer learning, and kNN evaluation. Our code will be made available at https://github.com/anshulbshah/HaLP.
STEPs: Self-Supervised Key Step Extraction from Unlabeled Procedural Videos
Jan 02, 2023



We address the problem of extracting key steps from unlabeled procedural videos, motivated by the potential of Augmented Reality (AR) headsets to revolutionize job training and performance. We decompose the problem into two steps: representation learning and key steps extraction. We employ self-supervised representation learning via a training strategy that adapts off-the-shelf video features using a temporal module. Training implements self-supervised learning losses involving multiple cues such as appearance, motion and pose trajectories extracted from videos to learn generalizable representations. Our method extracts key steps via a tunable algorithm that clusters the representations extracted from procedural videos. We quantitatively evaluate our approach with key step localization and also demonstrate the effectiveness of the extracted representations on related downstream tasks like phase classification. Qualitative results demonstrate that the extracted key steps are meaningful to succinctly represent the procedural tasks.
DiffAlign : Few-shot learning using diffusion based synthesis and alignment
Dec 11, 2022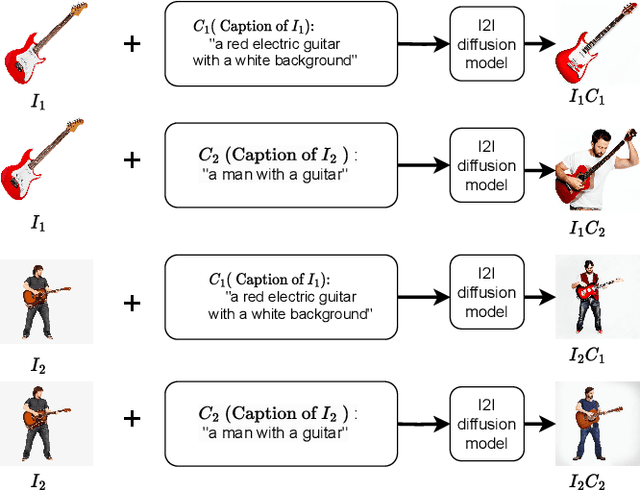
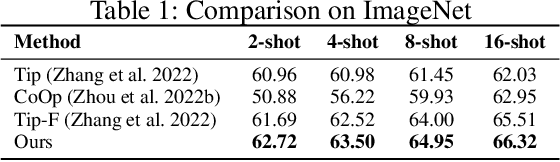
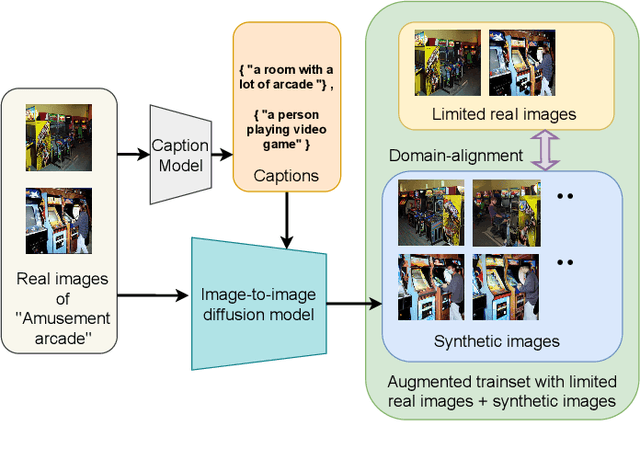
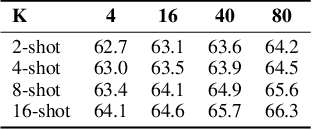
We address the problem of few-shot classification where the goal is to learn a classifier from a limited set of samples. While data-driven learning is shown to be effective in various applications, learning from less data still remains challenging. To address this challenge, existing approaches consider various data augmentation techniques for increasing the number of training samples. Pseudo-labeling is commonly used in a few-shot setup, where approximate labels are estimated for a large set of unlabeled images. We propose DiffAlign which focuses on generating images from class labels. Specifically, we leverage the recent success of the generative models (e.g., DALL-E and diffusion models) that can generate realistic images from texts. However, naive learning on synthetic images is not adequate due to the domain gap between real and synthetic images. Thus, we employ a maximum mean discrepancy (MMD) loss to align the synthetic images to the real images minimizing the domain gap. We evaluate our method on the standard few-shot classification benchmarks: CIFAR-FS, FC100, miniImageNet, tieredImageNet and a cross-domain few-shot classification benchmark: miniImageNet to CUB. The proposed approach significantly outperforms the stateof-the-art in both 5-shot and 1-shot setups on these benchmarks. Our approach is also shown to be effective in the zero-shot classification setup
Unfolding a blurred image
Jan 28, 2022We present a solution for the goal of extracting a video from a single motion blurred image to sequentially reconstruct the clear views of a scene as beheld by the camera during the time of exposure. We first learn motion representation from sharp videos in an unsupervised manner through training of a convolutional recurrent video autoencoder network that performs a surrogate task of video reconstruction. Once trained, it is employed for guided training of a motion encoder for blurred images. This network extracts embedded motion information from the blurred image to generate a sharp video in conjunction with the trained recurrent video decoder. As an intermediate step, we also design an efficient architecture that enables real-time single image deblurring and outperforms competing methods across all factors: accuracy, speed, and compactness. Experiments on real scenes and standard datasets demonstrate the superiority of our framework over the state-of-the-art and its ability to generate a plausible sequence of temporally consistent sharp frames.
Max-Margin Contrastive Learning
Dec 21, 2021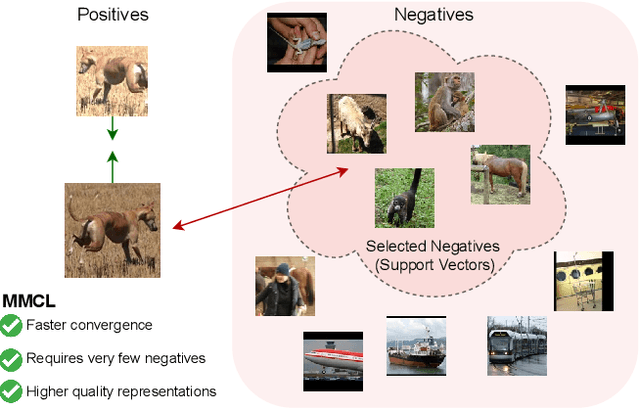
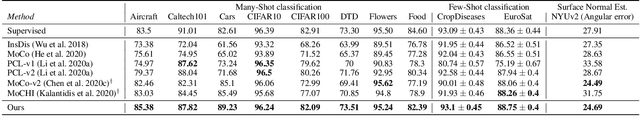
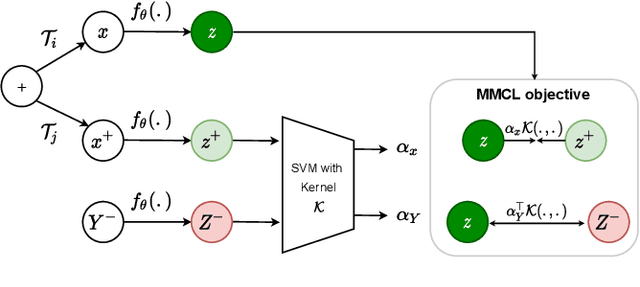
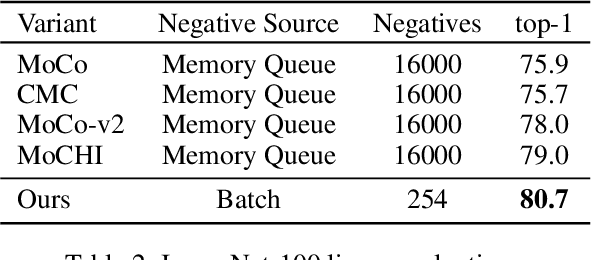
Standard contrastive learning approaches usually require a large number of negatives for effective unsupervised learning and often exhibit slow convergence. We suspect this behavior is due to the suboptimal selection of negatives used for offering contrast to the positives. We counter this difficulty by taking inspiration from support vector machines (SVMs) to present max-margin contrastive learning (MMCL). Our approach selects negatives as the sparse support vectors obtained via a quadratic optimization problem, and contrastiveness is enforced by maximizing the decision margin. As SVM optimization can be computationally demanding, especially in an end-to-end setting, we present simplifications that alleviate the computational burden. We validate our approach on standard vision benchmark datasets, demonstrating better performance in unsupervised representation learning over state-of-the-art, while having better empirical convergence properties.
Object-Aware Cropping for Self-Supervised Learning
Dec 01, 2021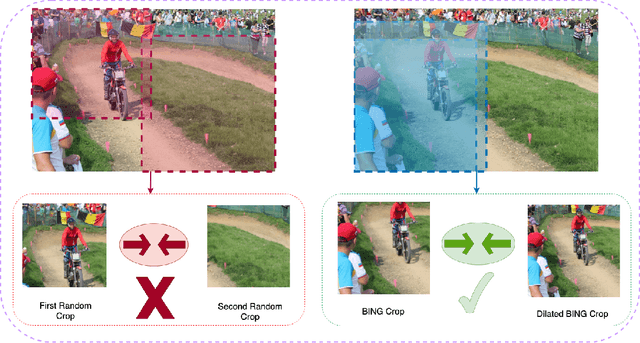
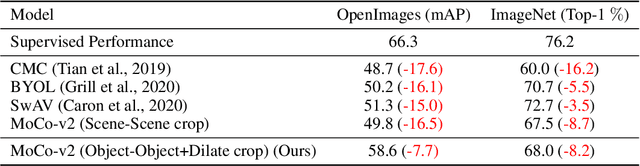
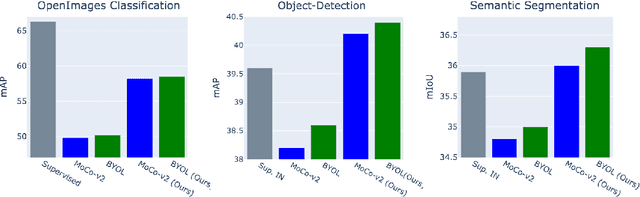

A core component of the recent success of self-supervised learning is cropping data augmentation, which selects sub-regions of an image to be used as positive views in the self-supervised loss. The underlying assumption is that randomly cropped and resized regions of a given image share information about the objects of interest, which the learned representation will capture. This assumption is mostly satisfied in datasets such as ImageNet where there is a large, centered object, which is highly likely to be present in random crops of the full image. However, in other datasets such as OpenImages or COCO, which are more representative of real world uncurated data, there are typically multiple small objects in an image. In this work, we show that self-supervised learning based on the usual random cropping performs poorly on such datasets. We propose replacing one or both of the random crops with crops obtained from an object proposal algorithm. This encourages the model to learn both object and scene level semantic representations. Using this approach, which we call object-aware cropping, results in significant improvements over scene cropping on classification and object detection benchmarks. For example, on OpenImages, our approach achieves an improvement of 8.8% mAP over random scene-level cropping using MoCo-v2 based pre-training. We also show significant improvements on COCO and PASCAL-VOC object detection and segmentation tasks over the state-of-the-art self-supervised learning approaches. Our approach is efficient, simple and general, and can be used in most existing contrastive and non-contrastive self-supervised learning frameworks.