 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
Object-Aware Cropping for Self-Supervised Learning
Dec 01, 2021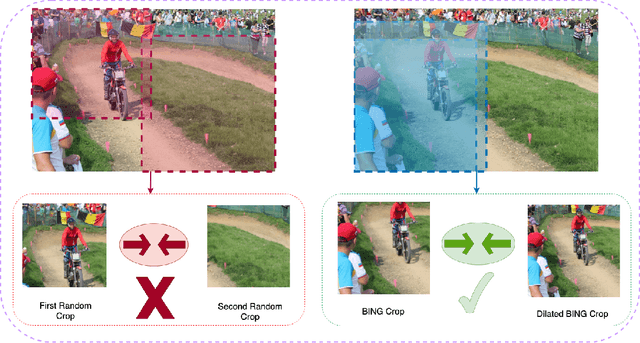
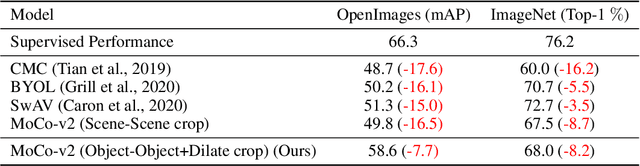
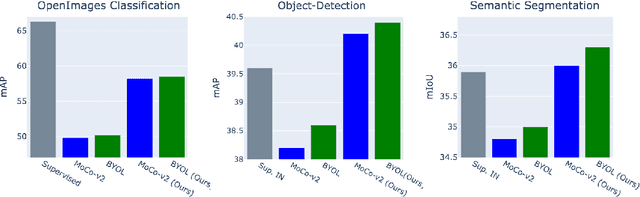

A core component of the recent success of self-supervised learning is cropping data augmentation, which selects sub-regions of an image to be used as positive views in the self-supervised loss. The underlying assumption is that randomly cropped and resized regions of a given image share information about the objects of interest, which the learned representation will capture. This assumption is mostly satisfied in datasets such as ImageNet where there is a large, centered object, which is highly likely to be present in random crops of the full image. However, in other datasets such as OpenImages or COCO, which are more representative of real world uncurated data, there are typically multiple small objects in an image. In this work, we show that self-supervised learning based on the usual random cropping performs poorly on such datasets. We propose replacing one or both of the random crops with crops obtained from an object proposal algorithm. This encourages the model to learn both object and scene level semantic representations. Using this approach, which we call object-aware cropping, results in significant improvements over scene cropping on classification and object detection benchmarks. For example, on OpenImages, our approach achieves an improvement of 8.8% mAP over random scene-level cropping using MoCo-v2 based pre-training. We also show significant improvements on COCO and PASCAL-VOC object detection and segmentation tasks over the state-of-the-art self-supervised learning approaches. Our approach is efficient, simple and general, and can be used in most existing contrastive and non-contrastive self-supervised learning frameworks.
Learning Visual Representations for Transfer Learning by Suppressing Texture
Nov 04, 2020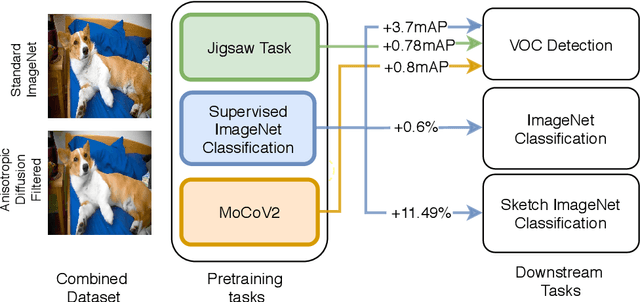
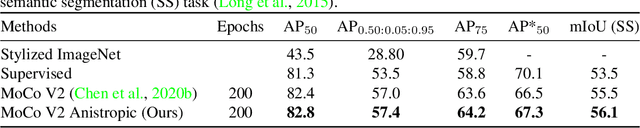


Recent literature has shown that features obtained from supervised training of CNNs may over-emphasize texture rather than encoding high-level information. In self-supervised learning in particular, texture as a low-level cue may provide shortcuts that prevent the network from learning higher level representations. To address these problems we propose to use classic methods based on anisotropic diffusion to augment training using images with suppressed texture. This simple method helps retain important edge information and suppress texture at the same time. We empirically show that our method achieves state-of-the-art results on object detection and image classification with eight diverse datasets in either supervised or self-supervised learning tasks such as MoCoV2 and Jigsaw. Our method is particularly effective for transfer learning tasks and we observed improved performance on five standard transfer learning datasets. The large improvements (up to 11.49\%) on the Sketch-ImageNet dataset, DTD dataset and additional visual analyses with saliency maps suggest that our approach helps in learning better representations that better transfer.
Pose And Joint-Aware Action Recognition
Oct 16, 2020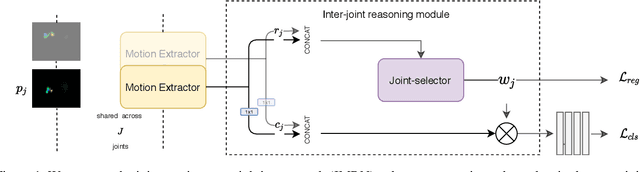
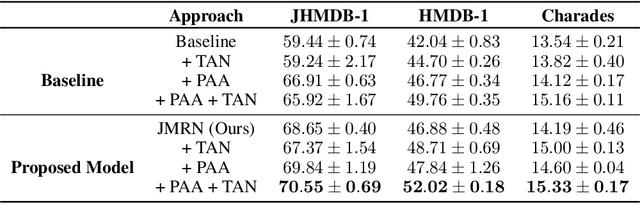
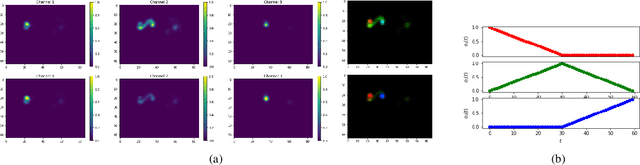
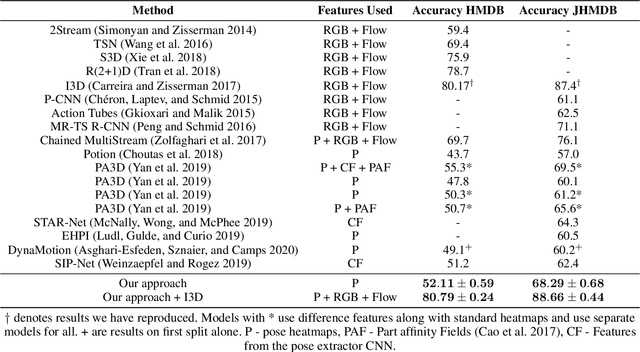
Most human action recognition systems typically consider static appearances and motion as independent streams of information. In this paper, we consider the evolution of human pose and propose a method to better capture interdependence among skeleton joints. Our model extracts motion information from each joint independently, reweighs the information and finally performs inter-joint reasoning. The effectiveness of pose and joint-based representations is strengthened using a geometry-aware data augmentation technique which jitters pose heatmaps while retaining the dynamics of the action. Our best model gives an absolute improvement of 8.19% on JHMDB, 4.31% on HMDB and 1.55 mAP on Charades datasets over state-of-the-art methods using pose heat-maps alone. Fusing with RGB and flow streams leads to improvement over state-of-the-art. Our model also outperforms the baseline on Mimetics, a dataset with out-of-context videos by 1.14% while using only pose heatmaps. Further, to filter out clips irrelevant for action recognition, we re-purpose our model for clip selection guided by pose information and show improved performance using fewer clips.
Visual Question Answering on Image Sets
Aug 27, 2020



We introduce the task of Image-Set Visual Question Answering (ISVQA), which generalizes the commonly studied single-image VQA problem to multi-image settings. Taking a natural language question and a set of images as input, it aims to answer the question based on the content of the images. The questions can be about objects and relationships in one or more images or about the entire scene depicted by the image set. To enable research in this new topic, we introduce two ISVQA datasets - indoor and outdoor scenes. They simulate the real-world scenarios of indoor image collections and multiple car-mounted cameras, respectively. The indoor-scene dataset contains 91,479 human annotated questions for 48,138 image sets, and the outdoor-scene dataset has 49,617 questions for 12,746 image sets. We analyze the properties of the two datasets, including question-and-answer distributions, types of questions, biases in dataset, and question-image dependencies. We also build new baseline models to investigate new research challenges in ISVQA.
Spatial Priming for Detecting Human-Object Interactions
Apr 09, 2020
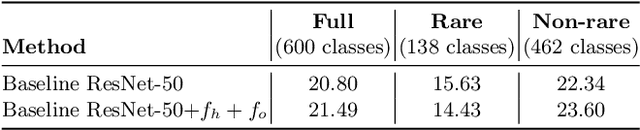
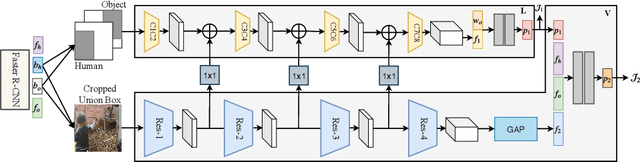
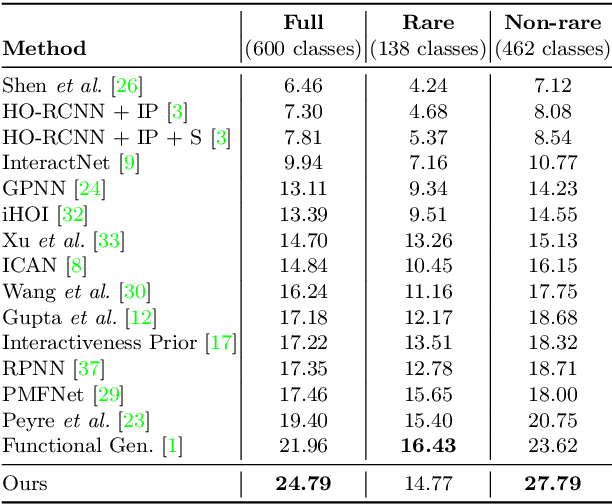
The relative spatial layout of a human and an object is an important cue for determining how they interact. However, until now, spatial layout has been used just as side-information for detecting human-object interactions (HOIs). In this paper, we present a method for exploiting this spatial layout information for detecting HOIs in images. The proposed method consists of a layout module which primes a visual module to predict the type of interaction between a human and an object. The visual and layout modules share information through lateral connections at several stages. The model uses predictions from the layout module as a prior to the visual module and the prediction from the visual module is given as the final output. It also incorporates semantic information about the object using word2vec vectors. The proposed model reaches an mAP of 24.79% for HICO-Det dataset which is about 2.8% absolute points higher than the current state-of-the-art.
How are attributes expressed in face DCNNs?
Oct 12, 2019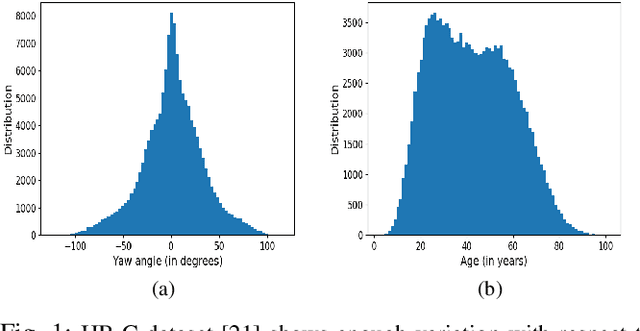
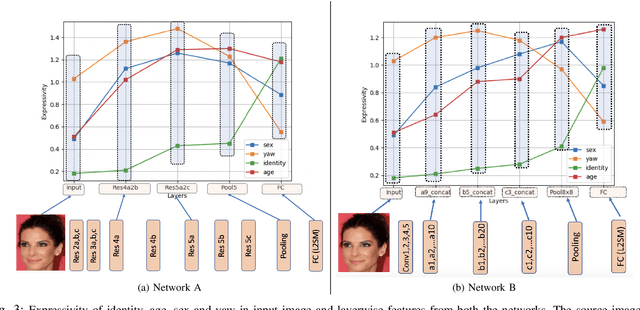
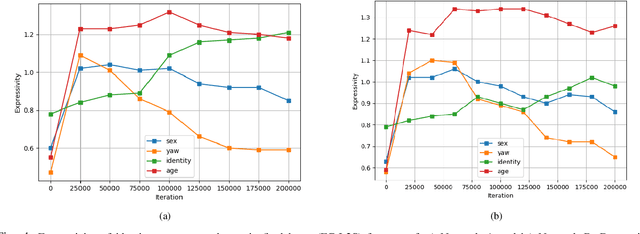
As deep networks become increasingly accurate at recognizing faces, it is vital to understand how these networks process faces. While these networks are solely trained to recognize identities, they also contain face related information such as sex, age, and pose of the face. The networks are not trained to learn these attributes. We introduce expressivity as a measure of how much a feature vector informs us about an attribute, where a feature vector can be from internal or final layers of a network. Expressivity is computed by a second neural network whose inputs are features and attributes. The output of the second neural network approximates the mutual information between feature vectors and an attribute. We investigate the expressivity for two different deep convolutional neural network (DCNN) architectures: a Resnet-101 and an Inception Resnet v2. In the final fully connected layer of the networks, we found the order of expressivity for facial attributes to be Age > Sex > Yaw. Additionally, we studied the changes in the encoding of facial attributes over training iterations. We found that as training progresses, expressivities of yaw, sex, and age decrease. Our technique can be a tool for investigating the sources of bias in a network and a step towards explaining the network's identity decisions.
Detecting Human-Object Interactions via Functional Generalization
Apr 05, 2019



We present an approach for detecting human-object interactions (HOIs) in images, based on the idea that humans interact with functionally similar objects in a similar manner. The proposed model is simple and uses the visual features of the human, relative spatial orientation of the human and the object, and the knowledge that functionally similar objects take part in similar interactions with humans. We provide extensive experimental validation for our approach and demonstrate state-of-the-art results for HOI detection. On the HICO-Det dataset our method achieves a gain of over 7% absolute points in mean average precision (mAP) over published literature and even a gain of over 2.5% absolute mAP over contemporary work. We also show that our approach leads to significant performance gains for zero-shot HOI detection in the seen object setting. We further demonstrate that using a generic object detector, our model can generalize to interactions involving previously unseen objects.
A Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018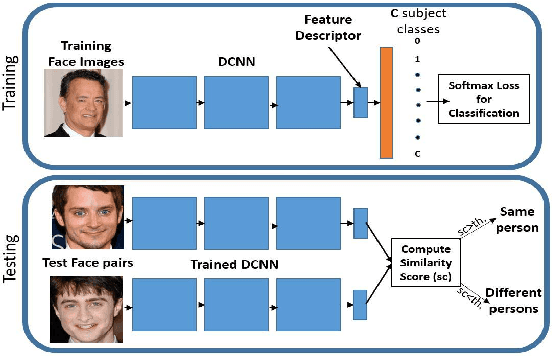
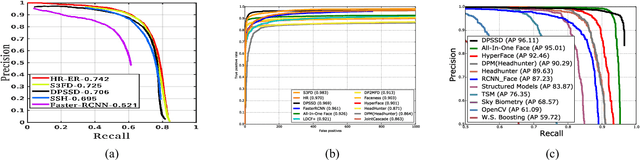
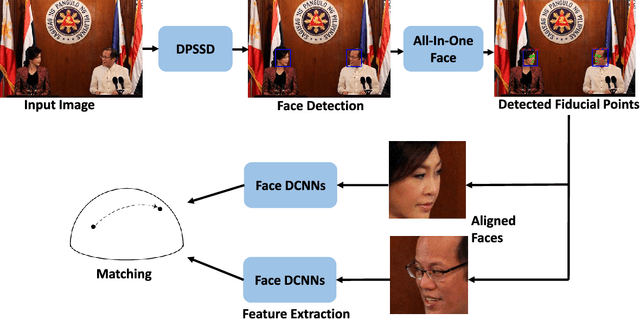
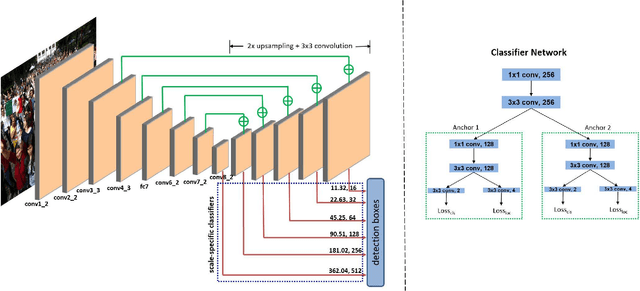
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).
Zero-Shot Object Detection
Jul 27, 2018



We introduce and tackle the problem of zero-shot object detection (ZSD), which aims to detect object classes which are not observed during training. We work with a challenging set of object classes, not restricting ourselves to similar and/or fine-grained categories as in prior works on zero-shot classification. We present a principled approach by first adapting visual-semantic embeddings for ZSD. We then discuss the problems associated with selecting a background class and motivate two background-aware approaches for learning robust detectors. One of these models uses a fixed background class and the other is based on iterative latent assignments. We also outline the challenge associated with using a limited number of training classes and propose a solution based on dense sampling of the semantic label space using auxiliary data with a large number of categories. We propose novel splits of two standard detection datasets - MSCOCO and VisualGenome, and present extensive empirical results in both the traditional and generalized zero-shot settings to highlight the benefits of the proposed methods. We provide useful insights into the algorithm and conclude by posing some open questions to encourage further research.