 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SayCoNav: Utilizing Large Language Models for Adaptive Collaboration in Decentralized Multi-Robot Navigation
May 19, 2025Adaptive collaboration is critical to a team of autonomous robots to perform complicated navigation tasks in large-scale unknown environments. An effective collaboration strategy should be determined and adapted according to each robot's skills and current status to successfully achieve the shared goal. We present SayCoNav, a new approach that leverages large language models (LLMs) for automatically generating this collaboration strategy among a team of robots. Building on the collaboration strategy, each robot uses the LLM to generate its plans and actions in a decentralized way. By sharing information to each other during navigation, each robot also continuously updates its step-by-step plans accordingly. We evaluate SayCoNav on Multi-Object Navigation (MultiON) tasks, that require the team of the robots to utilize their complementary strengths to efficiently search multiple different objects in unknown environments. By validating SayCoNav with varied team compositions and conditions against baseline methods, our experimental results show that SayCoNav can improve search efficiency by at most 44.28% through effective collaboration among heterogeneous robots. It can also dynamically adapt to the changing conditions during task execution.
Pelican: Correcting Hallucination in Vision-LLMs via Claim Decomposition and Program of Thought Verification
Jul 02, 2024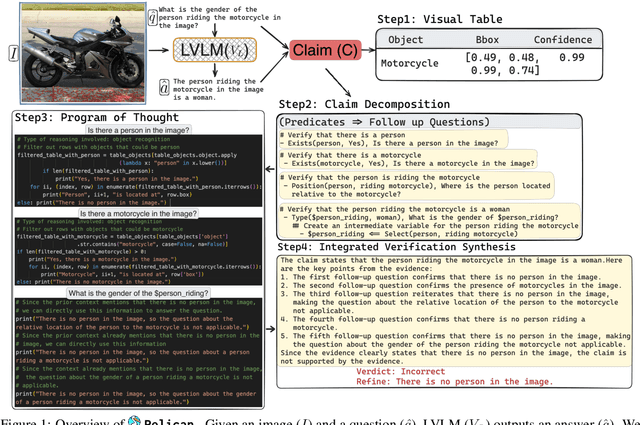
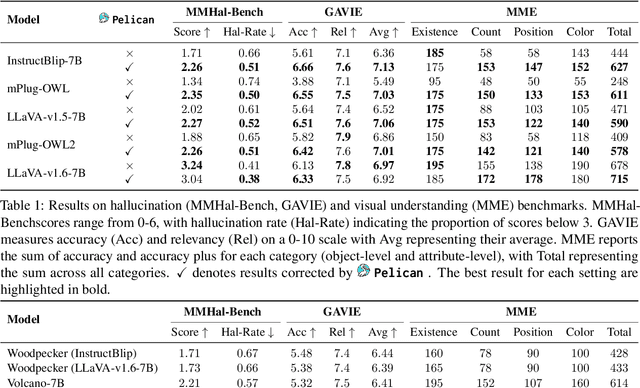
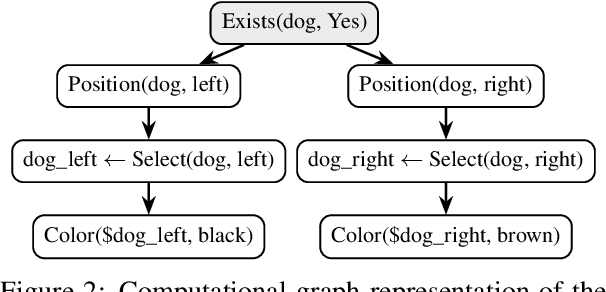

Large Visual Language Models (LVLMs) struggle with hallucinations in visual instruction following task(s), limiting their trustworthiness and real-world applicability. We propose Pelican -- a novel framework designed to detect and mitigate hallucinations through claim verification. Pelican first decomposes the visual claim into a chain of sub-claims based on first-order predicates. These sub-claims consist of (predicate, question) pairs and can be conceptualized as nodes of a computational graph. We then use Program-of-Thought prompting to generate Python code for answering these questions through flexible composition of external tools. Pelican improves over prior work by introducing (1) intermediate variables for precise grounding of object instances, and (2) shared computation for answering the sub-question to enable adaptive corrections and inconsistency identification. We finally use reasoning abilities of LLM to verify the correctness of the the claim by considering the consistency and confidence of the (question, answer) pairs from each sub-claim. Our experiments reveal a drop in hallucination rate by $\sim$8%-32% across various baseline LVLMs and a 27% drop compared to approaches proposed for hallucination mitigation on MMHal-Bench. Results on two other benchmarks further corroborate our results.
A Video is Worth 10,000 Words: Training and Benchmarking with Diverse Captions for Better Long Video Retrieval
Nov 30, 2023



Existing long video retrieval systems are trained and tested in the paragraph-to-video retrieval regime, where every long video is described by a single long paragraph. This neglects the richness and variety of possible valid descriptions of a video, which could be described in moment-by-moment detail, or in a single phrase summary, or anything in between. To provide a more thorough evaluation of the capabilities of long video retrieval systems, we propose a pipeline that leverages state-of-the-art large language models to carefully generate a diverse set of synthetic captions for long videos. We validate this pipeline's fidelity via rigorous human inspection. We then benchmark a representative set of video language models on these synthetic captions using a few long video datasets, showing that they struggle with the transformed data, especially the shortest captions. We also propose a lightweight fine-tuning method, where we use a contrastive loss to learn a hierarchical embedding loss based on the differing levels of information among the various captions. Our method improves performance both on the downstream paragraph-to-video retrieval task (+1.1% R@1 on ActivityNet), as well as for the various long video retrieval metrics we compute using our synthetic data (+3.6% R@1 for short descriptions on ActivityNet). For data access and other details, please refer to our project website at https://mgwillia.github.io/10k-words.
DRESS: Instructing Large Vision-Language Models to Align and Interact with Humans via Natural Language Feedback
Nov 16, 2023



We present DRESS, a large vision language model (LVLM) that innovatively exploits Natural Language feedback (NLF) from Large Language Models to enhance its alignment and interactions by addressing two key limitations in the state-of-the-art LVLMs. First, prior LVLMs generally rely only on the instruction finetuning stage to enhance alignment with human preferences. Without incorporating extra feedback, they are still prone to generate unhelpful, hallucinated, or harmful responses. Second, while the visual instruction tuning data is generally structured in a multi-turn dialogue format, the connections and dependencies among consecutive conversational turns are weak. This reduces the capacity for effective multi-turn interactions. To tackle these, we propose a novel categorization of the NLF into two key types: critique and refinement. The critique NLF identifies the strengths and weaknesses of the responses and is used to align the LVLMs with human preferences. The refinement NLF offers concrete suggestions for improvement and is adopted to improve the interaction ability of the LVLMs-- which focuses on LVLMs' ability to refine responses by incorporating feedback in multi-turn interactions. To address the non-differentiable nature of NLF, we generalize conditional reinforcement learning for training. Our experimental results demonstrate that DRESS can generate more helpful (9.76%), honest (11.52%), and harmless (21.03%) responses, and more effectively learn from feedback during multi-turn interactions compared to SOTA LVMLs.
Demonstrations Are All You Need: Advancing Offensive Content Paraphrasing using In-Context Learning
Oct 16, 2023



Paraphrasing of offensive content is a better alternative to content removal and helps improve civility in a communication environment. Supervised paraphrasers; however, rely heavily on large quantities of labelled data to help preserve meaning and intent. They also retain a large portion of the offensiveness of the original content, which raises questions on their overall usability. In this paper we aim to assist practitioners in developing usable paraphrasers by exploring In-Context Learning (ICL) with large language models (LLMs), i.e., using a limited number of input-label demonstration pairs to guide the model in generating desired outputs for specific queries. Our study focuses on key factors such as -- number and order of demonstrations, exclusion of prompt instruction, and reduction in measured toxicity. We perform principled evaluation on three datasets, including our proposed Context-Aware Polite Paraphrase dataset, comprising of dialogue-style rude utterances, polite paraphrases, and additional dialogue context. We evaluate our approach using two closed source and one open source LLM. Our results reveal that ICL is comparable to supervised methods in generation quality, while being qualitatively better by 25% on human evaluation and attaining lower toxicity by 76%. Also, ICL-based paraphrasers only show a slight reduction in performance even with just 10% training data.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 22, 2023



Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments. In addition, SayNav also enables efficient generalization of learning to navigate from simulation to real novel environments.
Measuring and Improving Chain-of-Thought Reasoning in Vision-Language Models
Sep 08, 2023Vision-language models (VLMs) have recently demonstrated strong efficacy as visual assistants that can parse natural queries about the visual content and generate human-like outputs. In this work, we explore the ability of these models to demonstrate human-like reasoning based on the perceived information. To address a crucial concern regarding the extent to which their reasoning capabilities are fully consistent and grounded, we also measure the reasoning consistency of these models. We achieve this by proposing a chain-of-thought (CoT) based consistency measure. However, such an evaluation requires a benchmark that encompasses both high-level inference and detailed reasoning chains, which is costly. We tackle this challenge by proposing a LLM-Human-in-the-Loop pipeline, which notably reduces cost while simultaneously ensuring the generation of a high-quality dataset. Based on this pipeline and the existing coarse-grained annotated dataset, we build the CURE benchmark to measure both the zero-shot reasoning performance and consistency of VLMs. We evaluate existing state-of-the-art VLMs, and find that even the best-performing model is unable to demonstrate strong visual reasoning capabilities and consistency, indicating that substantial efforts are required to enable VLMs to perform visual reasoning as systematically and consistently as humans. As an early step, we propose a two-stage training framework aimed at improving both the reasoning performance and consistency of VLMs. The first stage involves employing supervised fine-tuning of VLMs using step-by-step reasoning samples automatically generated by LLMs. In the second stage, we further augment the training process by incorporating feedback provided by LLMs to produce reasoning chains that are highly consistent and grounded. We empirically highlight the effectiveness of our framework in both reasoning performance and consistency.
TIJO: Trigger Inversion with Joint Optimization for Defending Multimodal Backdoored Models
Aug 07, 2023We present a Multimodal Backdoor Defense technique TIJO (Trigger Inversion using Joint Optimization). Recent work arXiv:2112.07668 has demonstrated successful backdoor attacks on multimodal models for the Visual Question Answering task. Their dual-key backdoor trigger is split across two modalities (image and text), such that the backdoor is activated if and only if the trigger is present in both modalities. We propose TIJO that defends against dual-key attacks through a joint optimization that reverse-engineers the trigger in both the image and text modalities. This joint optimization is challenging in multimodal models due to the disconnected nature of the visual pipeline which consists of an offline feature extractor, whose output is then fused with the text using a fusion module. The key insight enabling the joint optimization in TIJO is that the trigger inversion needs to be carried out in the object detection box feature space as opposed to the pixel space. We demonstrate the effectiveness of our method on the TrojVQA benchmark, where TIJO improves upon the state-of-the-art unimodal methods from an AUC of 0.6 to 0.92 on multimodal dual-key backdoors. Furthermore, our method also improves upon the unimodal baselines on unimodal backdoors. We present ablation studies and qualitative results to provide insights into our algorithm such as the critical importance of overlaying the inverted feature triggers on all visual features during trigger inversion. The prototype implementation of TIJO is available at https://github.com/SRI-CSL/TIJO.
Multilingual Content Moderation: A Case Study on Reddit
Feb 19, 2023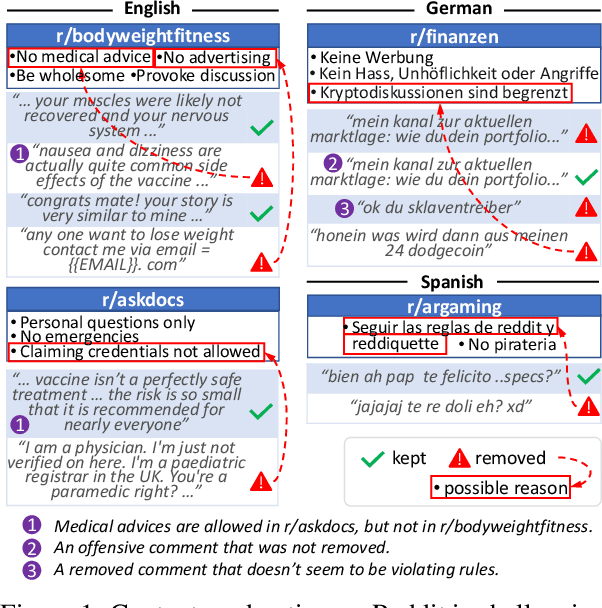
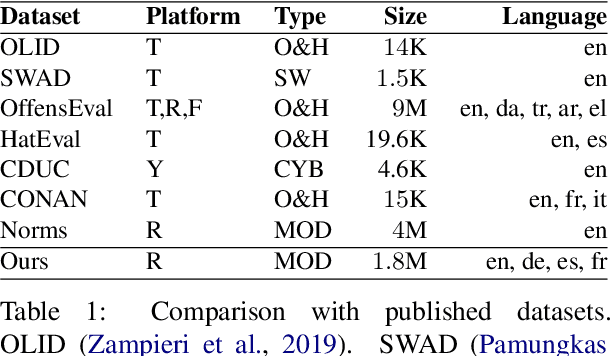
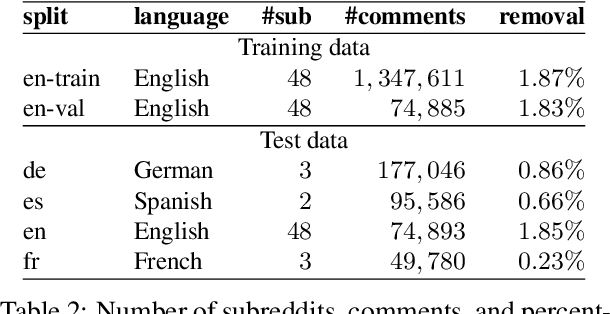
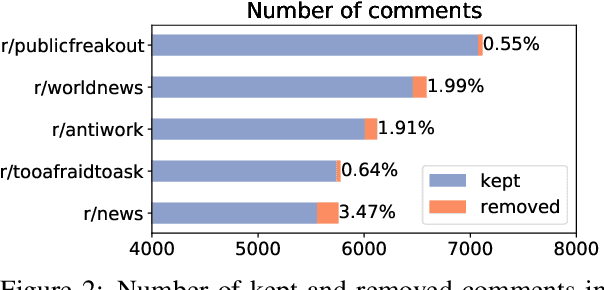
Content moderation is the process of flagging content based on pre-defined platform rules. There has been a growing need for AI moderators to safeguard users as well as protect the mental health of human moderators from traumatic content. While prior works have focused on identifying hateful/offensive language, they are not adequate for meeting the challenges of content moderation since 1) moderation decisions are based on violation of rules, which subsumes detection of offensive speech, and 2) such rules often differ across communities which entails an adaptive solution. We propose to study the challenges of content moderation by introducing a multilingual dataset of 1.8 Million Reddit comments spanning 56 subreddits in English, German, Spanish and French. We perform extensive experimental analysis to highlight the underlying challenges and suggest related research problems such as cross-lingual transfer, learning under label noise (human biases), transfer of moderation models, and predicting the violated rule. Our dataset and analysis can help better prepare for the challenges and opportunities of auto moderation.