 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGM-SLAM: Scene Graph Matching for Data-Efficient Distributed SLAM
Jun 15, 2026We introduce a data-efficient distributed Simultaneous Localization and Mapping (SLAM) framework designed for a team of robots equipped with LiDAR, cameras, and inertial sensors. Our framework uses scene graph matching to identify inter-robot measurement constraints. Unlike prior approaches that rely on feature-level matching, our framework is the first to perform scene graph matching using only object labels and centroids. Our approach constructs a scene graph by using fused RGB-LiDAR point clouds to generate both a semantically segmented point cloud layer, and a layer of discrete bounded objects, to accompany estimated robot trajectories. Scene graph matching is performed collaboratively through exchanging and matching object data with neighboring robots. To maximize communication efficiency, we utilize a multi-step data exchange and optimization process. We demonstrate the effectiveness and efficiency of our approach using both simulation and real-world datasets collected by legged robots in indoor and outdoor environments.
GeoSURGE: Geo-localization using Semantic Fusion with Hierarchy of Geographic Embeddings
Oct 01, 2025Worldwide visual geo-localization seeks to determine the geographic location of an image anywhere on Earth using only its visual content. Learned representations of geography for visual geo-localization remain an active research topic despite much progress. We formulate geo-localization as aligning the visual representation of the query image with a learned geographic representation. Our novel geographic representation explicitly models the world as a hierarchy of geographic embeddings. Additionally, we introduce an approach to efficiently fuse the appearance features of the query image with its semantic segmentation map, forming a robust visual representation. Our main experiments demonstrate improved all-time bests in 22 out of 25 metrics measured across five benchmark datasets compared to prior state-of-the-art (SOTA) methods and recent Large Vision-Language Models (LVLMs). Additional ablation studies support the claim that these gains are primarily driven by the combination of geographic and visual representations.
SayCoNav: Utilizing Large Language Models for Adaptive Collaboration in Decentralized Multi-Robot Navigation
May 19, 2025Adaptive collaboration is critical to a team of autonomous robots to perform complicated navigation tasks in large-scale unknown environments. An effective collaboration strategy should be determined and adapted according to each robot's skills and current status to successfully achieve the shared goal. We present SayCoNav, a new approach that leverages large language models (LLMs) for automatically generating this collaboration strategy among a team of robots. Building on the collaboration strategy, each robot uses the LLM to generate its plans and actions in a decentralized way. By sharing information to each other during navigation, each robot also continuously updates its step-by-step plans accordingly. We evaluate SayCoNav on Multi-Object Navigation (MultiON) tasks, that require the team of the robots to utilize their complementary strengths to efficiently search multiple different objects in unknown environments. By validating SayCoNav with varied team compositions and conditions against baseline methods, our experimental results show that SayCoNav can improve search efficiency by at most 44.28% through effective collaboration among heterogeneous robots. It can also dynamically adapt to the changing conditions during task execution.
Graph2Nav: 3D Object-Relation Graph Generation to Robot Navigation
Apr 23, 2025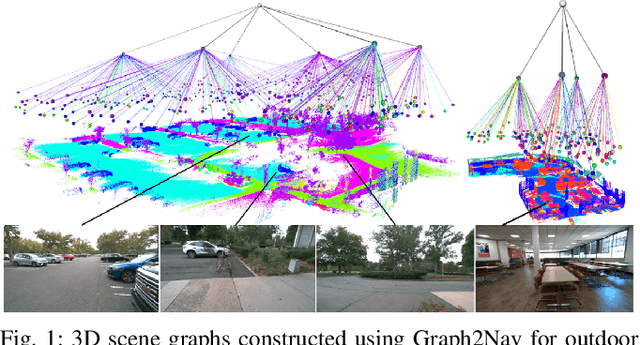
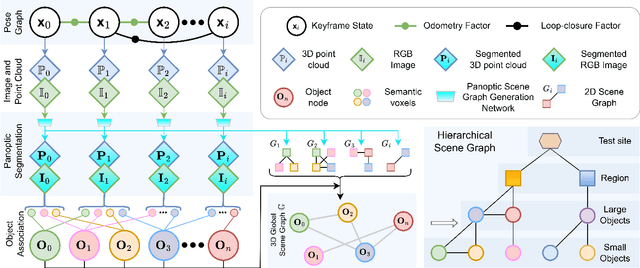
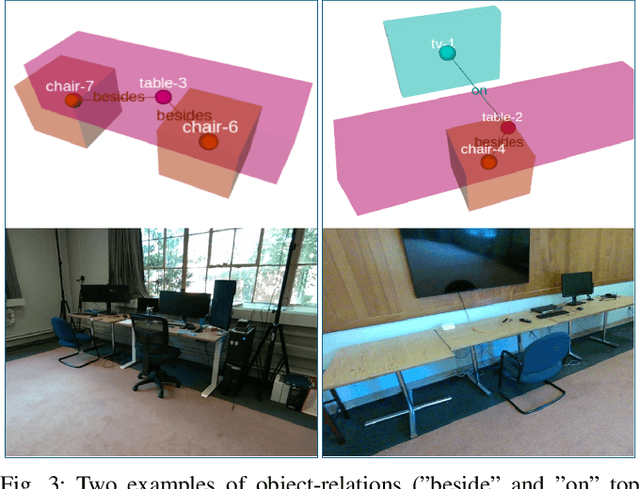

We propose Graph2Nav, a real-time 3D object-relation graph generation framework, for autonomous navigation in the real world. Our framework fully generates and exploits both 3D objects and a rich set of semantic relationships among objects in a 3D layered scene graph, which is applicable to both indoor and outdoor scenes. It learns to generate 3D semantic relations among objects, by leveraging and advancing state-of-the-art 2D panoptic scene graph works into the 3D world via 3D semantic mapping techniques. This approach avoids previous training data constraints in learning 3D scene graphs directly from 3D data. We conduct experiments to validate the accuracy in locating 3D objects and labeling object-relations in our 3D scene graphs. We also evaluate the impact of Graph2Nav via integration with SayNav, a state-of-the-art planner based on large language models, on an unmanned ground robot to object search tasks in real environments. Our results demonstrate that modeling object relations in our scene graphs improves search efficiency in these navigation tasks.
DUDA: Distilled Unsupervised Domain Adaptation for Lightweight Semantic Segmentation
Apr 14, 2025Unsupervised Domain Adaptation (UDA) is essential for enabling semantic segmentation in new domains without requiring costly pixel-wise annotations. State-of-the-art (SOTA) UDA methods primarily use self-training with architecturally identical teacher and student networks, relying on Exponential Moving Average (EMA) updates. However, these approaches face substantial performance degradation with lightweight models due to inherent architectural inflexibility leading to low-quality pseudo-labels. To address this, we propose Distilled Unsupervised Domain Adaptation (DUDA), a novel framework that combines EMA-based self-training with knowledge distillation (KD). Our method employs an auxiliary student network to bridge the architectural gap between heavyweight and lightweight models for EMA-based updates, resulting in improved pseudo-label quality. DUDA employs a strategic fusion of UDA and KD, incorporating innovative elements such as gradual distillation from large to small networks, inconsistency loss prioritizing poorly adapted classes, and learning with multiple teachers. Extensive experiments across four UDA benchmarks demonstrate DUDA's superiority in achieving SOTA performance with lightweight models, often surpassing the performance of heavyweight models from other approaches.
GFM4MPM: Towards Geospatial Foundation Models for Mineral Prospectivity Mapping
Jun 18, 2024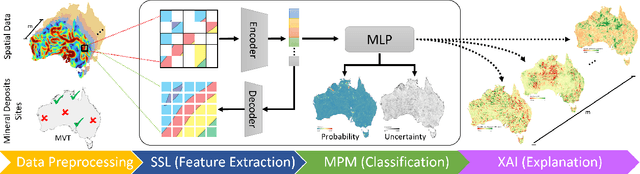
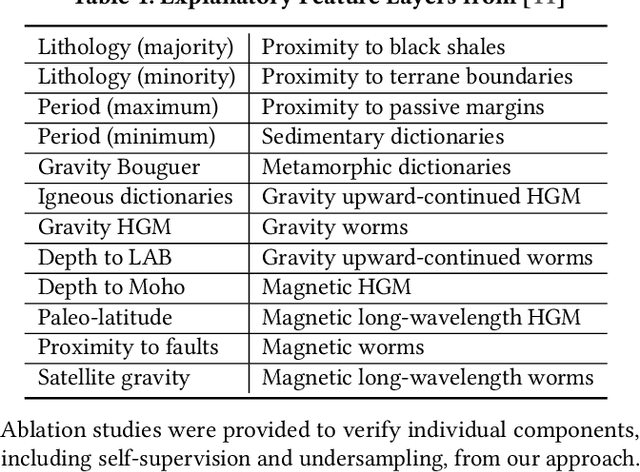
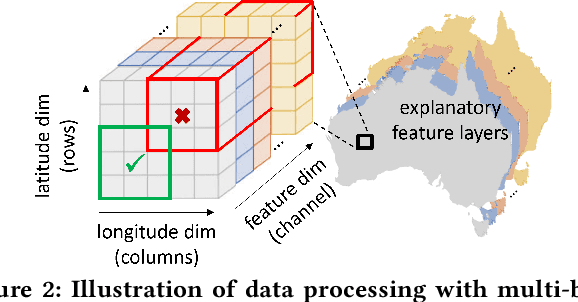
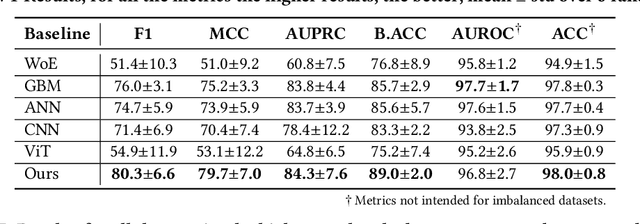
Machine Learning (ML) for Mineral Prospectivity Mapping (MPM) remains a challenging problem as it requires the analysis of associations between large-scale multi-modal geospatial data and few historical mineral commodity observations (positive labels). Recent MPM works have explored Deep Learning (DL) as a modeling tool with more representation capacity. However, these overparameterized methods may be more prone to overfitting due to their reliance on scarce labeled data. While a large quantity of unlabeled geospatial data exists, no prior MPM works have considered using such information in a self-supervised manner. Our MPM approach uses a masked image modeling framework to pretrain a backbone neural network in a self-supervised manner using unlabeled geospatial data alone. After pretraining, the backbone network provides feature extraction for downstream MPM tasks. We evaluated our approach alongside existing methods to assess mineral prospectivity of Mississippi Valley Type (MVT) and Clastic-Dominated (CD) Lead-Zinc deposits in North America and Australia. Our results demonstrate that self-supervision promotes robustness in learned features, improving prospectivity predictions. Additionally, we leverage explainable artificial intelligence techniques to demonstrate that individual predictions can be interpreted from a geological perspective.
Uncertainty Propagation through Trained Deep Neural Networks Using Factor Graphs
Dec 10, 2023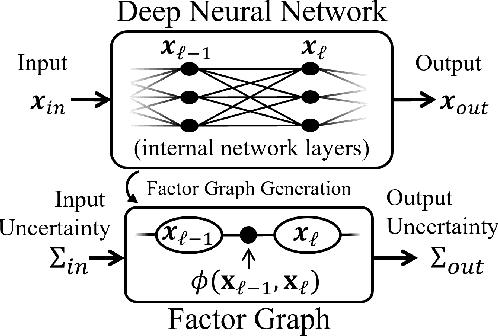
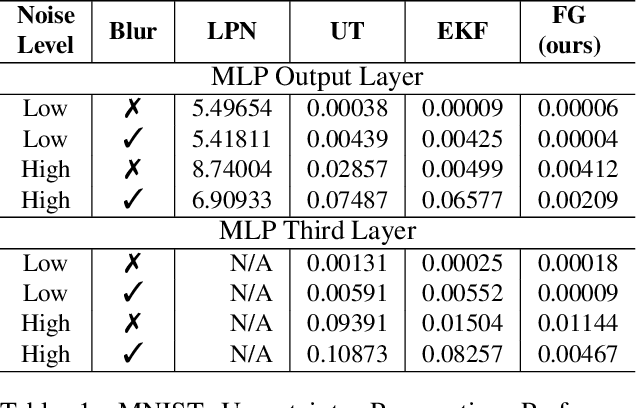
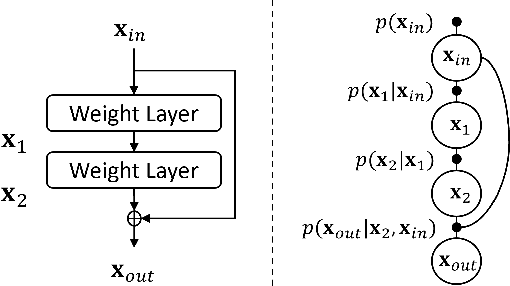
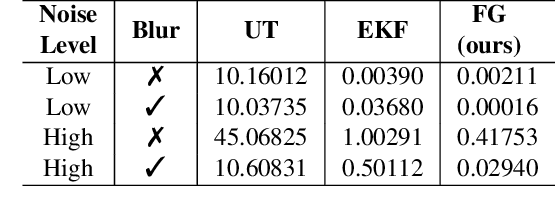
Predictive uncertainty estimation remains a challenging problem precluding the use of deep neural networks as subsystems within safety-critical applications. Aleatoric uncertainty is a component of predictive uncertainty that cannot be reduced through model improvements. Uncertainty propagation seeks to estimate aleatoric uncertainty by propagating input uncertainties to network predictions. Existing uncertainty propagation techniques use one-way information flows, propagating uncertainties layer-by-layer or across the entire neural network while relying either on sampling or analytical techniques for propagation. Motivated by the complex information flows within deep neural networks (e.g. skip connections), we developed and evaluated a novel approach by posing uncertainty propagation as a non-linear optimization problem using factor graphs. We observed statistically significant improvements in performance over prior work when using factor graphs across most of our experiments that included three datasets and two neural network architectures. Our implementation balances the benefits of sampling and analytical propagation techniques, which we believe, is a key factor in achieving performance improvements.
Unsupervised Domain Adaptation for Semantic Segmentation with Pseudo Label Self-Refinement
Oct 25, 2023



Deep learning-based solutions for semantic segmentation suffer from significant performance degradation when tested on data with different characteristics than what was used during the training. Adapting the models using annotated data from the new domain is not always practical. Unsupervised Domain Adaptation (UDA) approaches are crucial in deploying these models in the actual operating conditions. Recent state-of-the-art (SOTA) UDA methods employ a teacher-student self-training approach, where a teacher model is used to generate pseudo-labels for the new data which in turn guide the training process of the student model. Though this approach has seen a lot of success, it suffers from the issue of noisy pseudo-labels being propagated in the training process. To address this issue, we propose an auxiliary pseudo-label refinement network (PRN) for online refining of the pseudo labels and also localizing the pixels whose predicted labels are likely to be noisy. Being able to improve the quality of pseudo labels and select highly reliable ones, PRN helps self-training of segmentation models to be robust against pseudo label noise propagation during different stages of adaptation. We evaluate our approach on benchmark datasets with three different domain shifts, and our approach consistently performs significantly better than the previous state-of-the-art methods.
SayNav: Grounding Large Language Models for Dynamic Planning to Navigation in New Environments
Sep 22, 2023



Semantic reasoning and dynamic planning capabilities are crucial for an autonomous agent to perform complex navigation tasks in unknown environments. It requires a large amount of common-sense knowledge, that humans possess, to succeed in these tasks. We present SayNav, a new approach that leverages human knowledge from Large Language Models (LLMs) for efficient generalization to complex navigation tasks in unknown large-scale environments. SayNav uses a novel grounding mechanism, that incrementally builds a 3D scene graph of the explored environment as inputs to LLMs, for generating feasible and contextually appropriate high-level plans for navigation. The LLM-generated plan is then executed by a pre-trained low-level planner, that treats each planned step as a short-distance point-goal navigation sub-task. SayNav dynamically generates step-by-step instructions during navigation and continuously refines future steps based on newly perceived information. We evaluate SayNav on a new multi-object navigation task, that requires the agent to utilize a massive amount of human knowledge to efficiently search multiple different objects in an unknown environment. SayNav outperforms an oracle based Point-nav baseline, achieving a success rate of 95.35% (vs 56.06% for the baseline), under the ideal settings on this task, highlighting its ability to generate dynamic plans for successfully locating objects in large-scale new environments. In addition, SayNav also enables efficient generalization of learning to navigate from simulation to real novel environments.
Cross-View Visual Geo-Localization for Outdoor Augmented Reality
Mar 28, 2023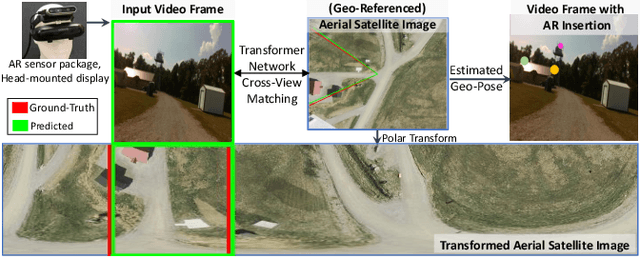



Precise estimation of global orientation and location is critical to ensure a compelling outdoor Augmented Reality (AR) experience. We address the problem of geo-pose estimation by cross-view matching of query ground images to a geo-referenced aerial satellite image database. Recently, neural network-based methods have shown state-of-the-art performance in cross-view matching. However, most of the prior works focus only on location estimation, ignoring orientation, which cannot meet the requirements in outdoor AR applications. We propose a new transformer neural network-based model and a modified triplet ranking loss for joint location and orientation estimation. Experiments on several benchmark cross-view geo-localization datasets show that our model achieves state-of-the-art performance. Furthermore, we present an approach to extend the single image query-based geo-localization approach by utilizing temporal information from a navigation pipeline for robust continuous geo-localization. Experimentation on several large-scale real-world video sequences demonstrates that our approach enables high-precision and stable AR insertion.