 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFM4MPM: Towards Geospatial Foundation Models for Mineral Prospectivity Mapping
Jun 18, 2024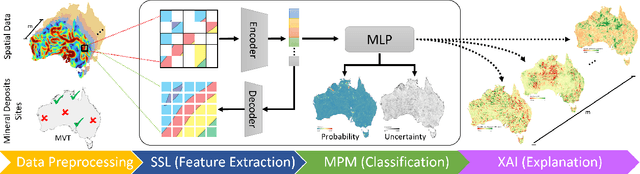
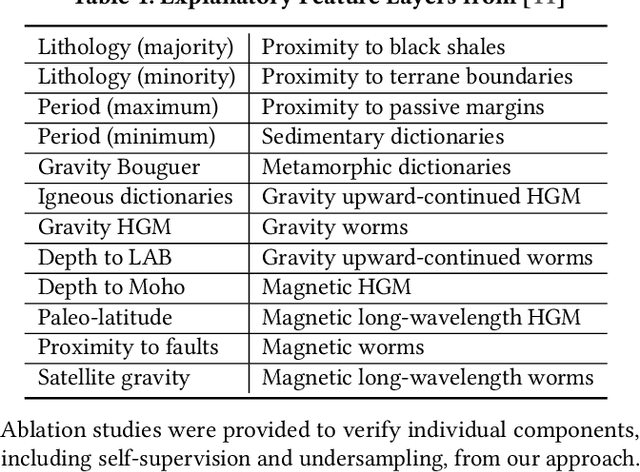
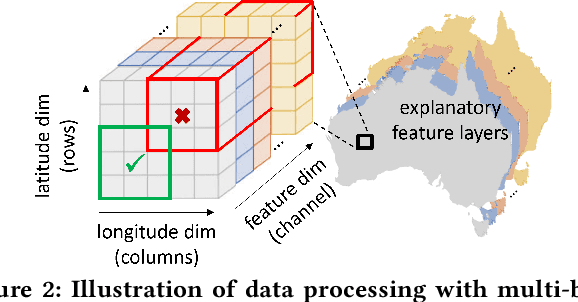
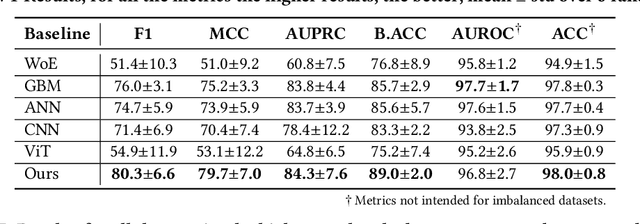
Machine Learning (ML) for Mineral Prospectivity Mapping (MPM) remains a challenging problem as it requires the analysis of associations between large-scale multi-modal geospatial data and few historical mineral commodity observations (positive labels). Recent MPM works have explored Deep Learning (DL) as a modeling tool with more representation capacity. However, these overparameterized methods may be more prone to overfitting due to their reliance on scarce labeled data. While a large quantity of unlabeled geospatial data exists, no prior MPM works have considered using such information in a self-supervised manner. Our MPM approach uses a masked image modeling framework to pretrain a backbone neural network in a self-supervised manner using unlabeled geospatial data alone. After pretraining, the backbone network provides feature extraction for downstream MPM tasks. We evaluated our approach alongside existing methods to assess mineral prospectivity of Mississippi Valley Type (MVT) and Clastic-Dominated (CD) Lead-Zinc deposits in North America and Australia. Our results demonstrate that self-supervision promotes robustness in learned features, improving prospectivity predictions. Additionally, we leverage explainable artificial intelligence techniques to demonstrate that individual predictions can be interpreted from a geological perspective.
SCP-GAN: Self-Correcting Discriminator Optimization for Training Consistency Preserving Metric GAN on Speech Enhancement Tasks
Oct 26, 2022


In recent years, Generative Adversarial Networks (GANs) have produced significantly improved results in speech enhancement (SE) tasks. They are difficult to train, however. In this work, we introduce several improvements to the GAN training schemes, which can be applied to most GAN-based SE models. We propose using consistency loss functions, which target the inconsistency in time and time-frequency domains caused by Fourier and Inverse Fourier Transforms. We also present self-correcting optimization for training a GAN discriminator on SE tasks, which helps avoid "harmful" training directions for parts of the discriminator loss function. We have tested our proposed methods on several state-of-the-art GAN-based SE models and obtained consistent improvements, including new state-of-the-art results for the Voice Bank+DEMAND dataset.
Breaking Time Invariance: Assorted-Time Normalization for RNNs
Sep 28, 2022
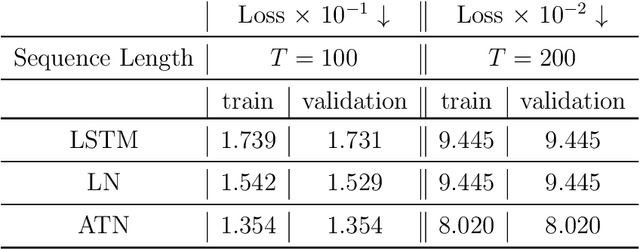
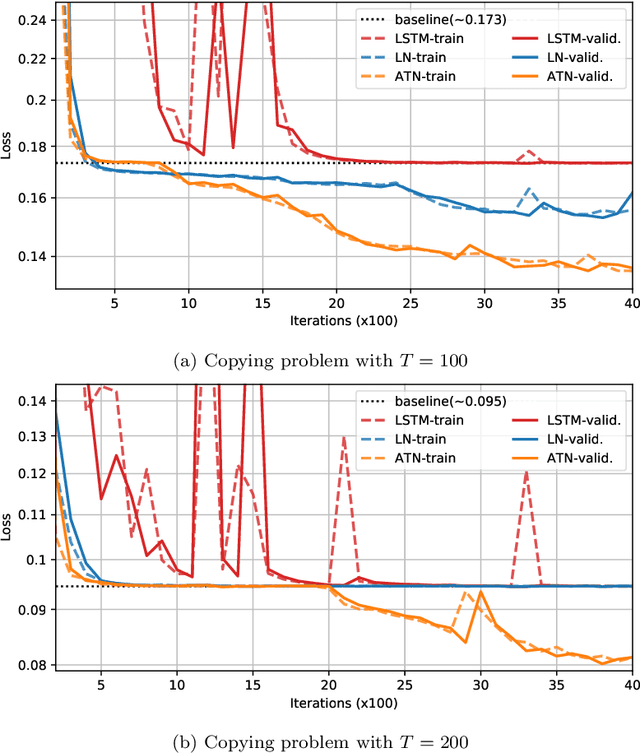
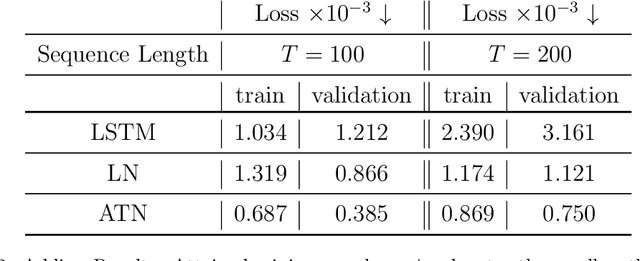
Methods such as Layer Normalization (LN) and Batch Normalization (BN) have proven to be effective in improving the training of Recurrent Neural Networks (RNNs). However, existing methods normalize using only the instantaneous information at one particular time step, and the result of the normalization is a preactivation state with a time-independent distribution. This implementation fails to account for certain temporal differences inherent in the inputs and the architecture of RNNs. Since these networks share weights across time steps, it may also be desirable to account for the connections between time steps in the normalization scheme. In this paper, we propose a normalization method called Assorted-Time Normalization (ATN), which preserves information from multiple consecutive time steps and normalizes using them. This setup allows us to introduce longer time dependencies into the traditional normalization methods without introducing any new trainable parameters. We present theoretical derivations for the gradient propagation and prove the weight scaling invariance property. Our experiments applying ATN to LN demonstrate consistent improvement on various tasks, such as Adding, Copying, and Denoise Problems and Language Modeling Problems.
Orthogonal Gated Recurrent Unit with Neumann-Cayley Transformation
Aug 12, 2022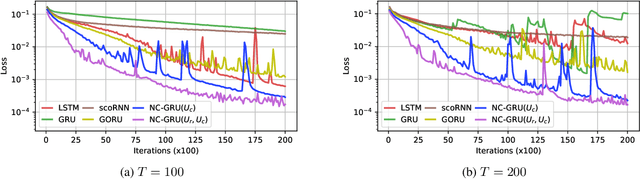
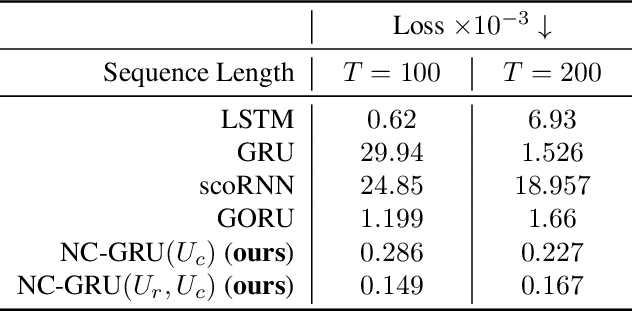
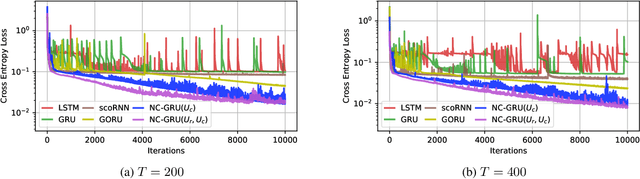
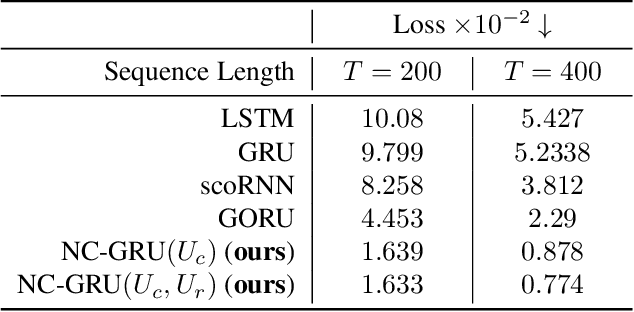
In recent years, using orthogonal matrices has been shown to be a promising approach in improving Recurrent Neural Networks (RNNs) with training, stability, and convergence, particularly, to control gradients. While Gated Recurrent Unit (GRU) and Long Short Term Memory (LSTM) architectures address the vanishing gradient problem by using a variety of gates and memory cells, they are still prone to the exploding gradient problem. In this work, we analyze the gradients in GRU and propose the usage of orthogonal matrices to prevent exploding gradient problems and enhance long-term memory. We study where to use orthogonal matrices and we propose a Neumann series-based Scaled Cayley transformation for training orthogonal matrices in GRU, which we call Neumann-Cayley Orthogonal GRU, or simply NC-GRU. We present detailed experiments of our model on several synthetic and real-world tasks, which show that NC-GRU significantly outperforms GRU as well as several other RNNs.
Symmetry Structured Convolutional Neural Networks
Mar 03, 2022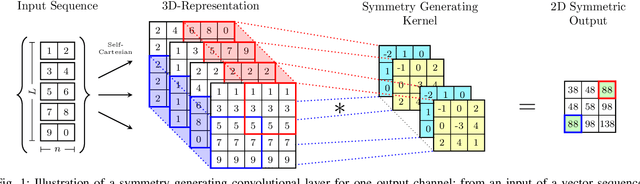
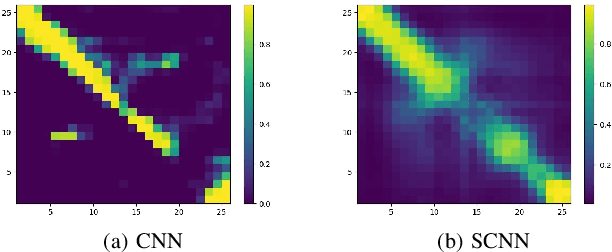
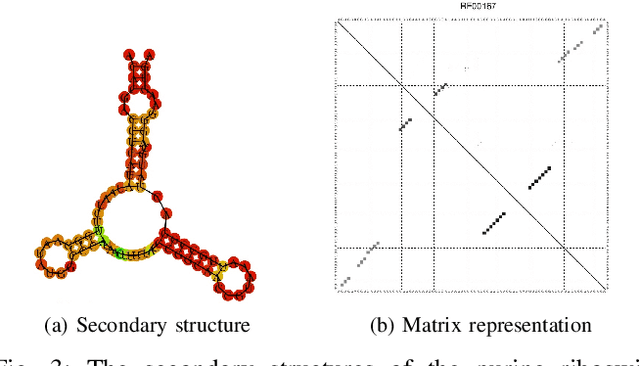
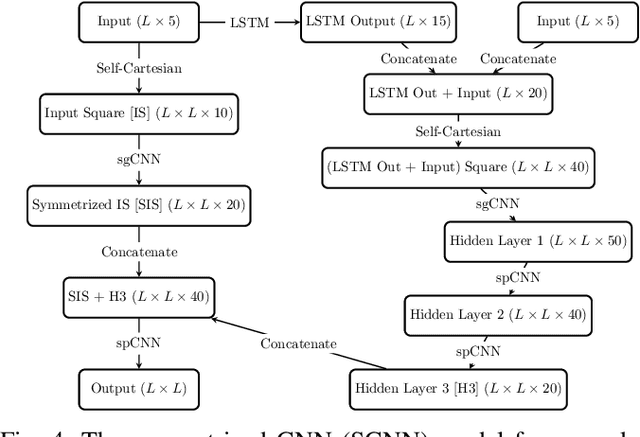
We consider Convolutional Neural Networks (CNNs) with 2D structured features that are symmetric in the spatial dimensions. Such networks arise in modeling pairwise relationships for a sequential recommendation problem, as well as secondary structure inference problems of RNA and protein sequences. We develop a CNN architecture that generates and preserves the symmetry structure in the network's convolutional layers. We present parameterizations for the convolutional kernels that produce update rules to maintain symmetry throughout the training. We apply this architecture to the sequential recommendation problem, the RNA secondary structure inference problem, and the protein contact map prediction problem, showing that the symmetric structured networks produce improved results using fewer numbers of machine parameters.
Adaptive Weighted Discriminator for Training Generative Adversarial Networks
Dec 05, 2020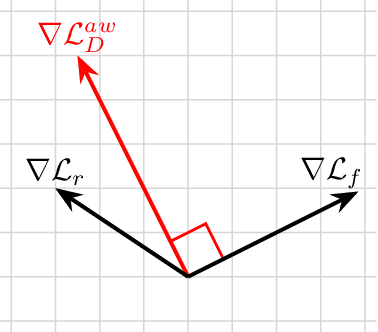
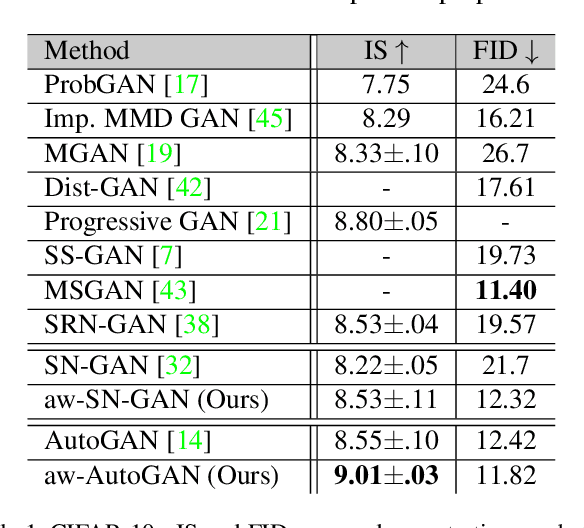

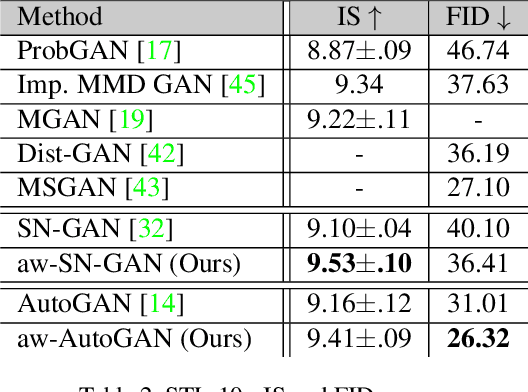
Generative adversarial network (GAN) has become one of the most important neural network models for classical unsupervised machine learning. A variety of discriminator loss functions have been developed to train GAN's discriminators and they all have a common structure: a sum of real and fake losses that only depends on the actual and generated data respectively. One challenge associated with an equally weighted sum of two losses is that the training may benefit one loss but harm the other, which we show causes instability and mode collapse. In this paper, we introduce a new family of discriminator loss functions that adopts a weighted sum of real and fake parts, which we call adaptive weighted loss functions or aw-loss functions. Using the gradients of the real and fake parts of the loss, we can adaptively choose weights to train a discriminator in the direction that benefits the GAN's stability. Our method can be potentially applied to any discriminator model with a loss that is a sum of the real and fake parts. Experiments validated the effectiveness of our loss functions on an unconditional image generation task, improving the baseline results by a significant margin on CIFAR-10, STL-10, and CIFAR-100 datasets in Inception Scores and FID.