 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSURGE: Geo-localization using Semantic Fusion with Hierarchy of Geographic Embeddings
Oct 01, 2025Worldwide visual geo-localization seeks to determine the geographic location of an image anywhere on Earth using only its visual content. Learned representations of geography for visual geo-localization remain an active research topic despite much progress. We formulate geo-localization as aligning the visual representation of the query image with a learned geographic representation. Our novel geographic representation explicitly models the world as a hierarchy of geographic embeddings. Additionally, we introduce an approach to efficiently fuse the appearance features of the query image with its semantic segmentation map, forming a robust visual representation. Our main experiments demonstrate improved all-time bests in 22 out of 25 metrics measured across five benchmark datasets compared to prior state-of-the-art (SOTA) methods and recent Large Vision-Language Models (LVLMs). Additional ablation studies support the claim that these gains are primarily driven by the combination of geographic and visual representations.
GFM4MPM: Towards Geospatial Foundation Models for Mineral Prospectivity Mapping
Jun 18, 2024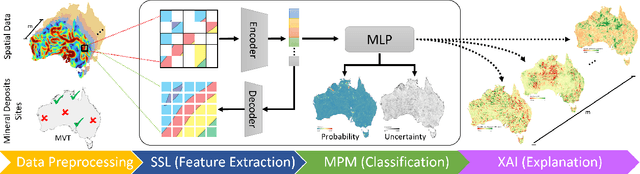
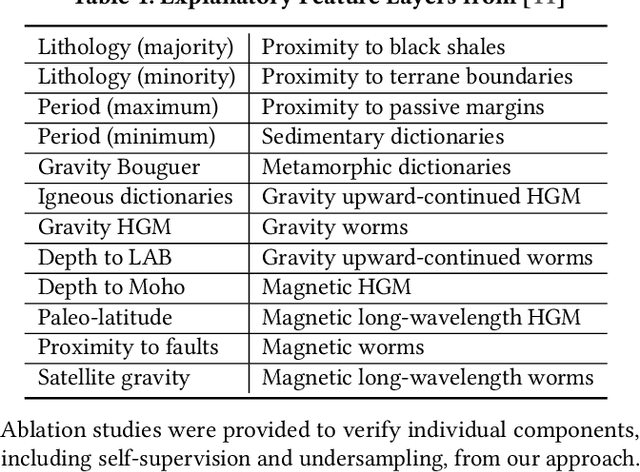
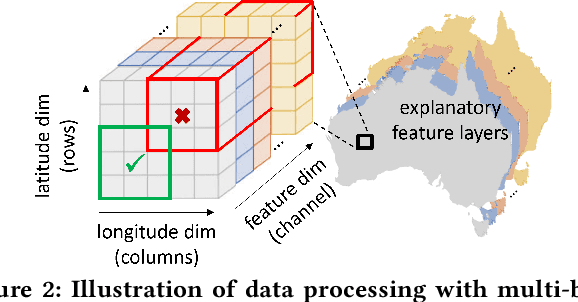
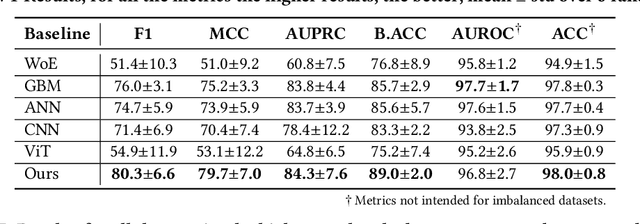
Machine Learning (ML) for Mineral Prospectivity Mapping (MPM) remains a challenging problem as it requires the analysis of associations between large-scale multi-modal geospatial data and few historical mineral commodity observations (positive labels). Recent MPM works have explored Deep Learning (DL) as a modeling tool with more representation capacity. However, these overparameterized methods may be more prone to overfitting due to their reliance on scarce labeled data. While a large quantity of unlabeled geospatial data exists, no prior MPM works have considered using such information in a self-supervised manner. Our MPM approach uses a masked image modeling framework to pretrain a backbone neural network in a self-supervised manner using unlabeled geospatial data alone. After pretraining, the backbone network provides feature extraction for downstream MPM tasks. We evaluated our approach alongside existing methods to assess mineral prospectivity of Mississippi Valley Type (MVT) and Clastic-Dominated (CD) Lead-Zinc deposits in North America and Australia. Our results demonstrate that self-supervision promotes robustness in learned features, improving prospectivity predictions. Additionally, we leverage explainable artificial intelligence techniques to demonstrate that individual predictions can be interpreted from a geological perspective.
Uncertainty Propagation through Trained Deep Neural Networks Using Factor Graphs
Dec 10, 2023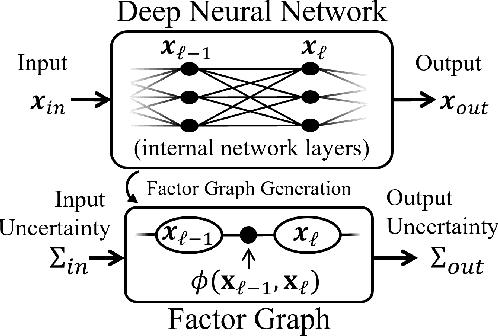
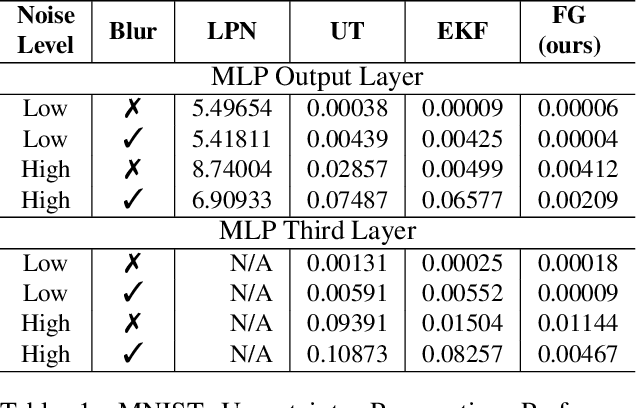
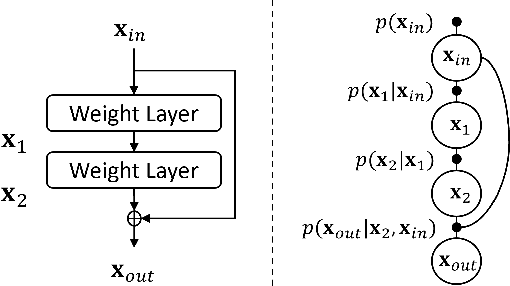
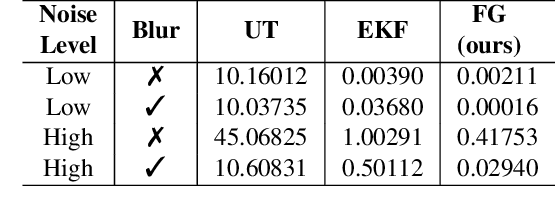
Predictive uncertainty estimation remains a challenging problem precluding the use of deep neural networks as subsystems within safety-critical applications. Aleatoric uncertainty is a component of predictive uncertainty that cannot be reduced through model improvements. Uncertainty propagation seeks to estimate aleatoric uncertainty by propagating input uncertainties to network predictions. Existing uncertainty propagation techniques use one-way information flows, propagating uncertainties layer-by-layer or across the entire neural network while relying either on sampling or analytical techniques for propagation. Motivated by the complex information flows within deep neural networks (e.g. skip connections), we developed and evaluated a novel approach by posing uncertainty propagation as a non-linear optimization problem using factor graphs. We observed statistically significant improvements in performance over prior work when using factor graphs across most of our experiments that included three datasets and two neural network architectures. Our implementation balances the benefits of sampling and analytical propagation techniques, which we believe, is a key factor in achieving performance improvements.
Explainable Knowledge Graph Embedding: Inference Reconciliation for Knowledge Inferences Supporting Robot Actions
May 04, 2022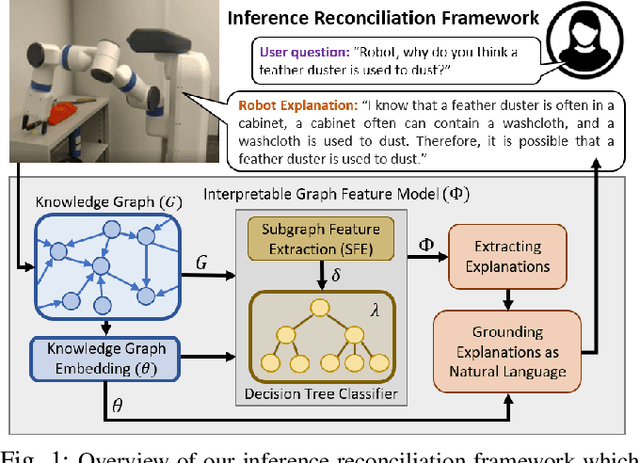


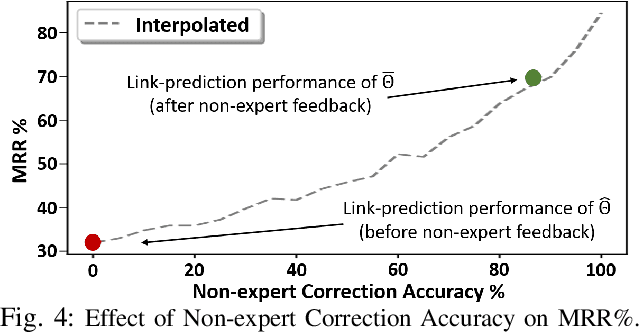
Learned knowledge graph representations supporting robots contain a wealth of domain knowledge that drives robot behavior. However, there does not exist an inference reconciliation framework that expresses how a knowledge graph representation affects a robot's sequential decision making. We use a pedagogical approach to explain the inferences of a learned, black-box knowledge graph representation, a knowledge graph embedding. Our interpretable model, uses a decision tree classifier to locally approximate the predictions of the black-box model, and provides natural language explanations interpretable by non-experts. Results from our algorithmic evaluation affirm our model design choices, and the results of our user studies with non-experts support the need for the proposed inference reconciliation framework. Critically, results from our simulated robot evaluation indicate that our explanations enable non-experts to correct erratic robot behaviors due to nonsensical beliefs within the black-box.
Towards Robust One-shot Task Execution using Knowledge Graph Embeddings
May 10, 2021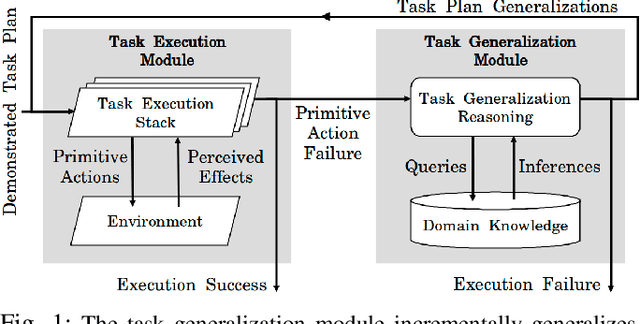
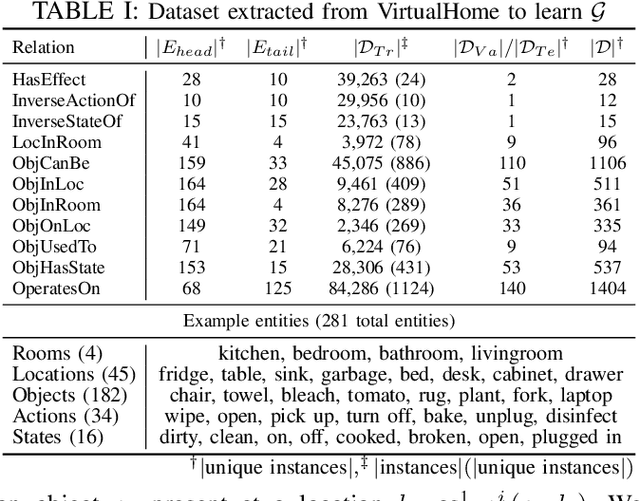
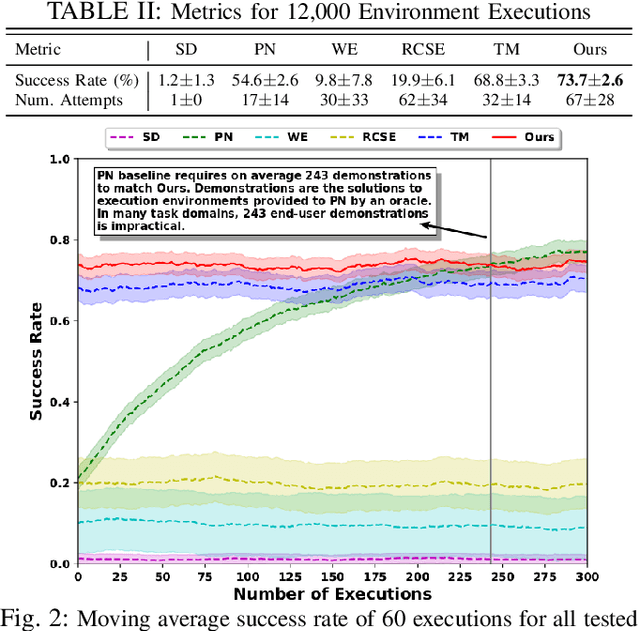
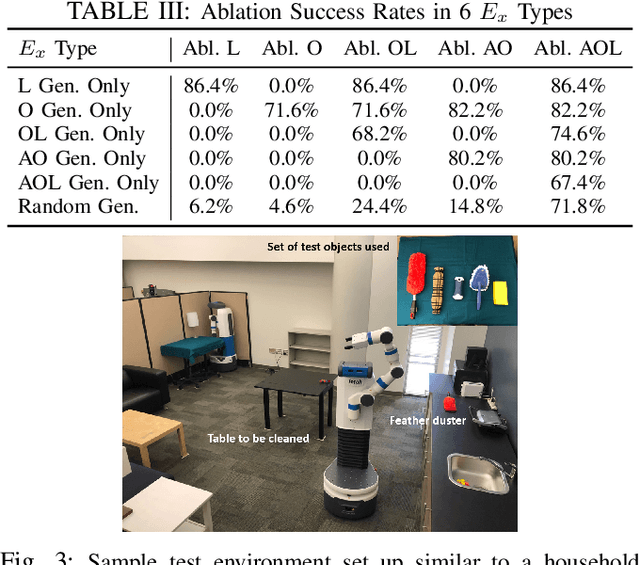
Requiring multiple demonstrations of a task plan presents a burden to end-users of robots. However, robustly executing tasks plans from a single end-user demonstration is an ongoing challenge in robotics. We address the problem of one-shot task execution, in which a robot must generalize a single demonstration or prototypical example of a task plan to a new execution environment. Our approach integrates task plans with domain knowledge to infer task plan constituents for new execution environments. Our experimental evaluations show that our knowledge representation makes more relevant generalizations that result in significantly higher success rates over tested baselines. We validated the approach on a physical platform, which resulted in the successful generalization of initial task plans to 38 of 50 execution environments with errors resulting from autonomous robot operation included.
Continual Learning of Knowledge Graph Embeddings
Jan 14, 2021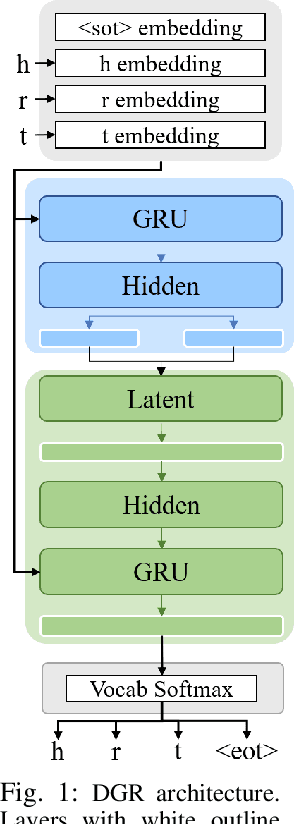
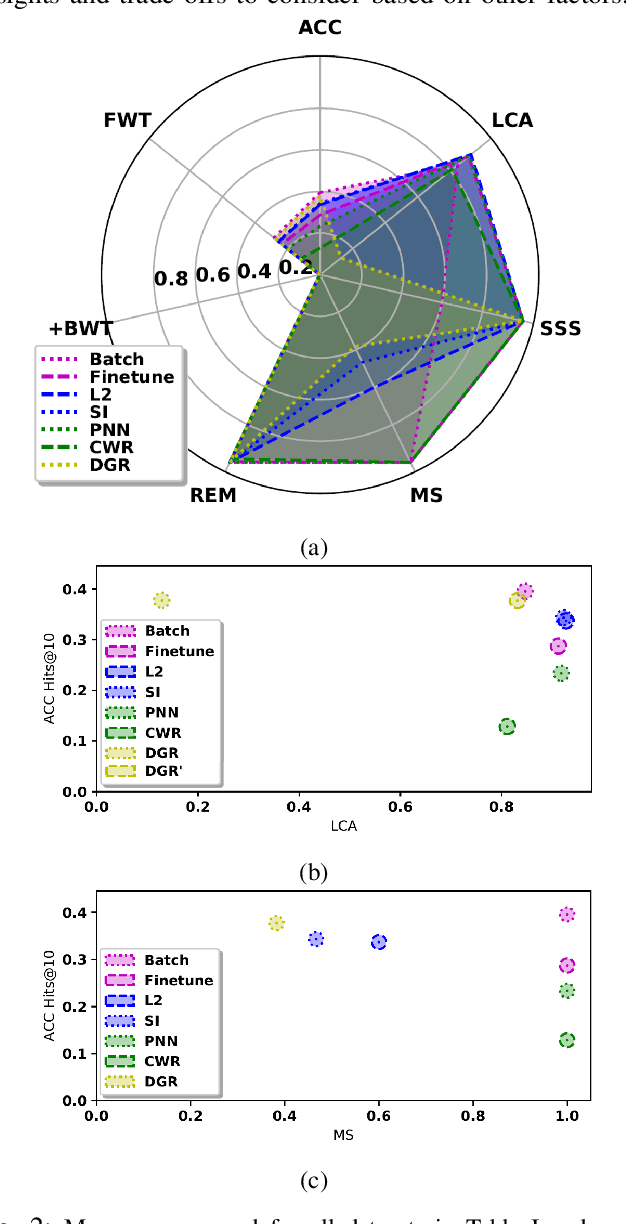
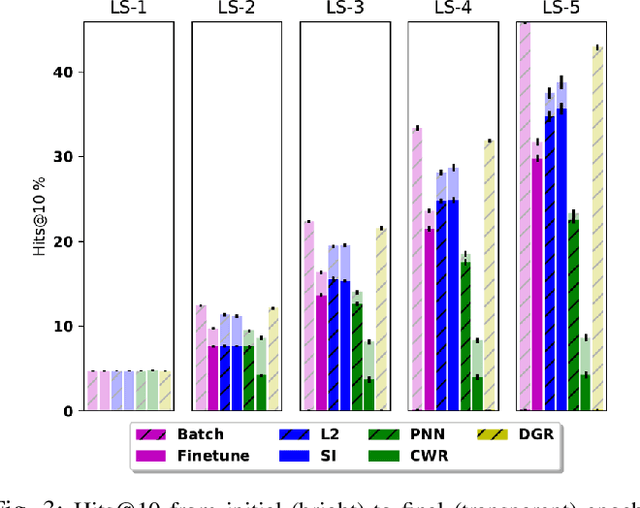
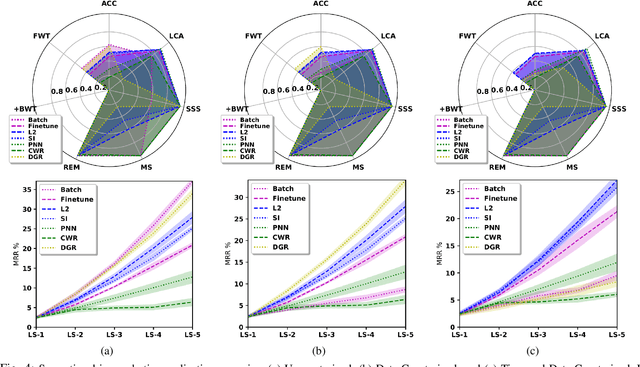
In recent years, there has been a resurgence in methods that use distributed (neural) representations to represent and reason about semantic knowledge for robotics applications. However, while robots often observe previously unknown concepts, these representations typically assume that all concepts are known a priori, and incorporating new information requires all concepts to be learned afresh. Our work relaxes the static assumptions of these representations to tackle the incremental knowledge graph embedding problem by leveraging principles of a range of continual learning methods. Through an experimental evaluation with several knowledge graphs and embedding representations, we provide insights about trade-offs for practitioners to match a semantics-driven robotics application to a suitable continual knowledge graph embedding method.
Taking Recoveries to Task: Recovery-Driven Development for Recipe-based Robot Tasks
Jan 28, 2020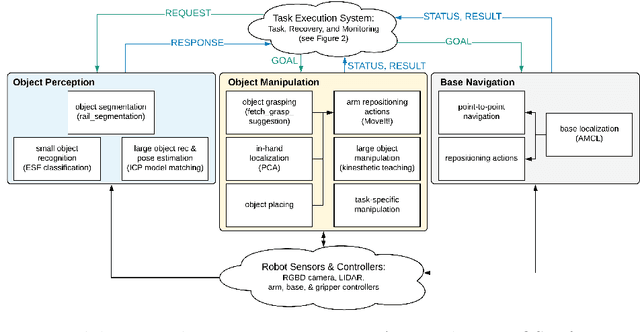
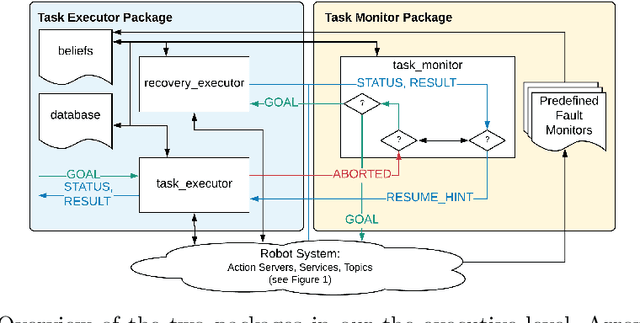

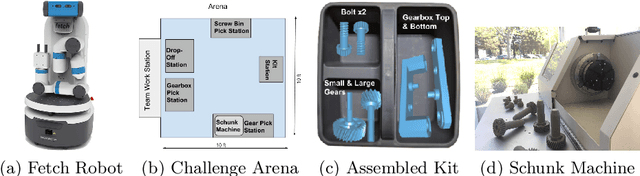
Robot task execution when situated in real-world environments is fragile. As such, robot architectures must rely on robust error recovery, adding non-trivial complexity to highly-complex robot systems. To handle this complexity in development, we introduce Recovery-Driven Development (RDD), an iterative task scripting process that facilitates rapid task and recovery development by leveraging hierarchical specification, separation of nominal task and recovery development, and situated testing. We validate our approach with our challenge-winning mobile manipulator software architecture developed using RDD for the FetchIt! Challenge at the IEEE 2019 International Conference on Robotics and Automation. We attribute the success of our system to the level of robustness achieved using RDD, and conclude with lessons learned for developing such systems.
CAGE: Context-Aware Grasping Engine
Sep 24, 2019
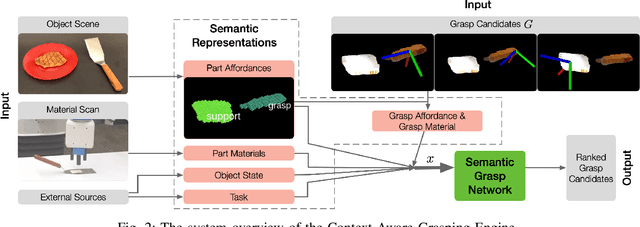
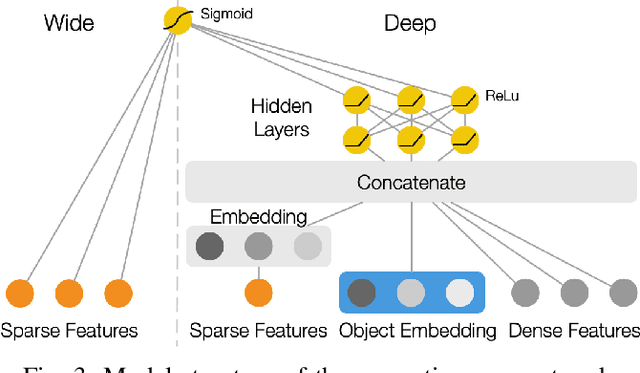
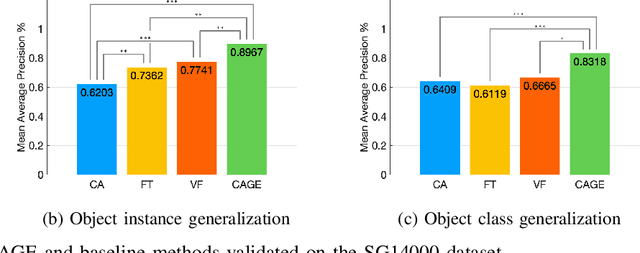
Semantic grasping is the problem of selecting stable grasps that are functionally suitable for specific object manipulation tasks. In order for robots to effectively perform object manipulation, a broad sense of context, including object and task constraints, needs to be accounted for. We introduce the Context-Aware Grasping Engine, a neural network structure based on the Wide & Deep model, to learn suitable semantic grasps from data. We quantitatively validate our approach against three prior methods on a novel dataset consisting of 14,000 semantic grasps for 44 objects, 7 tasks, and 6 different object states. Our approach outperformed all baselines by statistically significant margins, producing new insights into the importance of balancing memorization and generalization of contexts for semantic grasping. We further demonstrate the effectiveness of our approach on robot experiments in which the presented model successfully achieved 31 of 32 grasps.
Leveraging Semantics for Incremental Learning in Multi-Relational Embeddings
May 29, 2019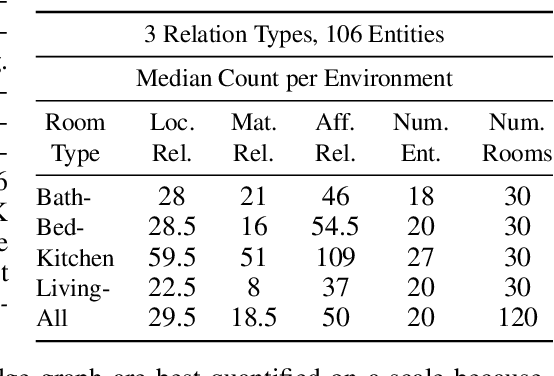
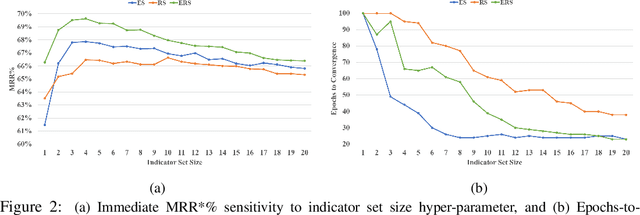
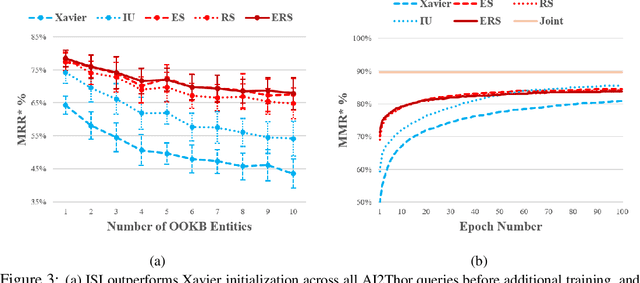

Prior work has shown that the multi-relational embedding objective can be reformulated to learn dynamic knowledge graphs, enabling incremental class learning. The core contribution of our work is Incremental Semantic Initialization, which enables the multi-relational embedding parameters for a novel concept to be initialized in relation to previously learned embeddings of semantically similar concepts. We present three variants of our approach: Entity Similarity Initialization, Relational Similarity Initialization, and Hybrid Similarity Initialization, that reason about entities, relations between entities, or both, respectively. When evaluated on the mined AI2Thor dataset, our experiments show that incremental semantic initialization improves immediate query performance by 21.3 MRR* percentage points, on average. Additionally, the best performing proposed method reduced the number of epochs required to approach joint-learning performance by 57.4\% on average.
Path Ranking with Attention to Type Hierarchies
May 26, 2019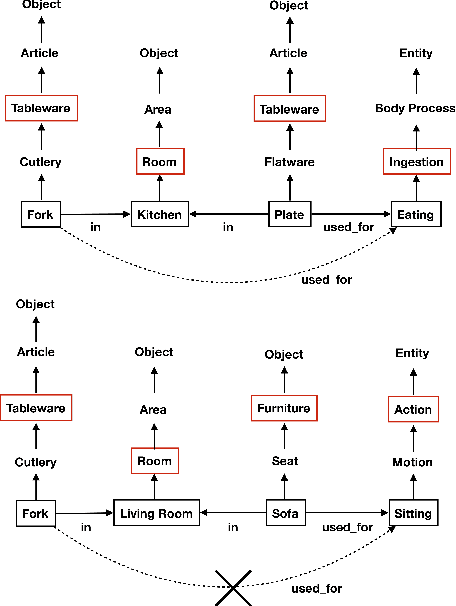
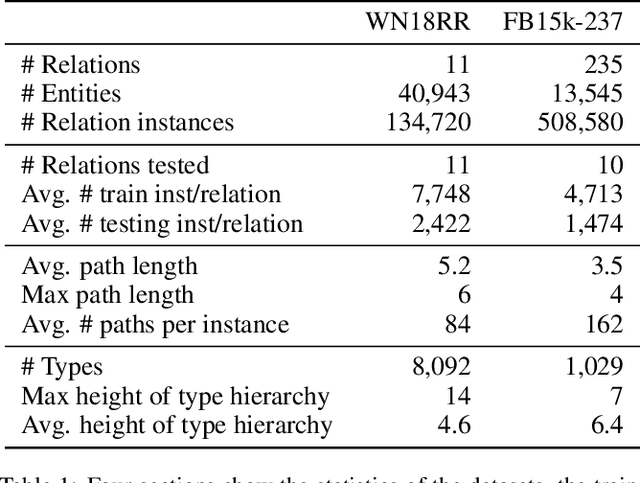
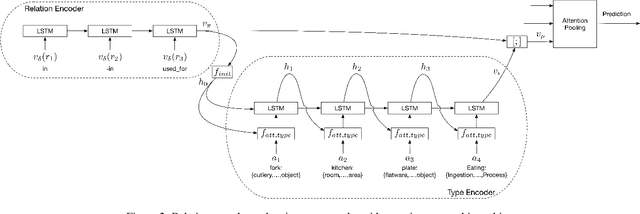
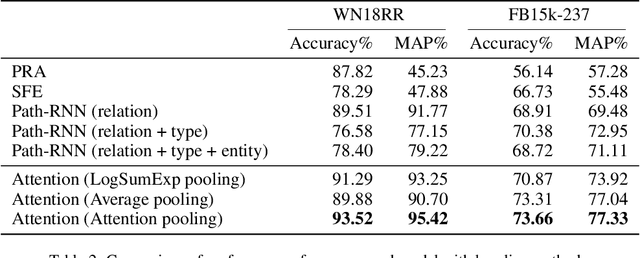
The knowledge base completion problem is the problem of inferring missing information from existing facts in knowledge bases. Path-ranking based methods use sequences of relations as general patterns of paths for prediction. However, these patterns usually lack accuracy because they are generic and can often apply to widely varying scenarios. We leverage type hierarchies of entities to create a new class of path patterns that are both discriminative and generalizable. Then we propose an attention-based RNN model, which can be trained end-to-end, to discover the new path patterns most suitable for the data. Experiments conducted on two benchmark knowledge base completion datasets demonstrate that the proposed model outperforms existing methods by a statistically significant margin. Our quantitative analysis of the path patterns shows that they balance between generalization and discrimination.