 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Paper Screening for Clinical Reviews Using Large Language Models
May 01, 2023Objective: To assess the performance of the OpenAI GPT API in accurately and efficiently identifying relevant titles and abstracts from real-world clinical review datasets and compare its performance against ground truth labelling by two independent human reviewers. Methods: We introduce a novel workflow using the OpenAI GPT API for screening titles and abstracts in clinical reviews. A Python script was created to make calls to the GPT API with the screening criteria in natural language and a corpus of title and abstract datasets that have been filtered by a minimum of two human reviewers. We compared the performance of our model against human-reviewed papers across six review papers, screening over 24,000 titles and abstracts. Results: Our results show an accuracy of 0.91, a sensitivity of excluded papers of 0.91, and a sensitivity of included papers of 0.76. On a randomly selected subset of papers, the GPT API demonstrated the ability to provide reasoning for its decisions and corrected its initial decision upon being asked to explain its reasoning for a subset of incorrect classifications. Conclusion: The GPT API has the potential to streamline the clinical review process, save valuable time and effort for researchers, and contribute to the overall quality of clinical reviews. By prioritizing the workflow and acting as an aid rather than a replacement for researchers and reviewers, the GPT API can enhance efficiency and lead to more accurate and reliable conclusions in medical research.
Continual Learning of Knowledge Graph Embeddings
Jan 14, 2021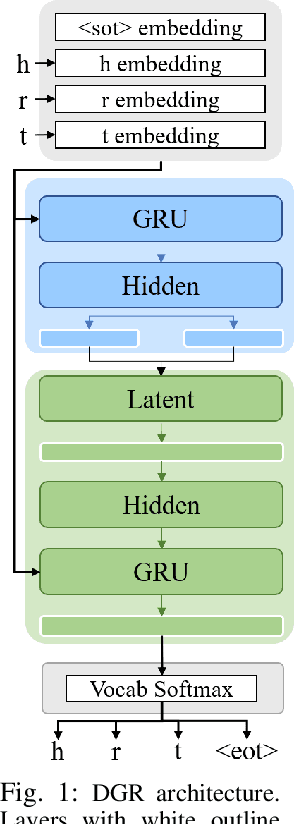
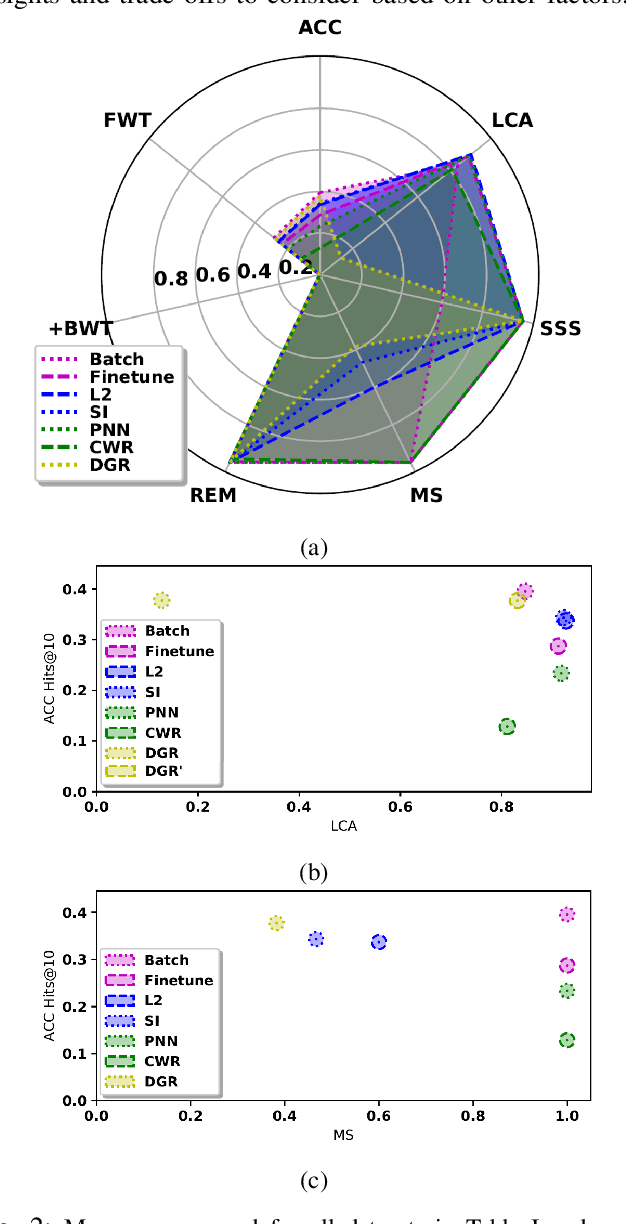
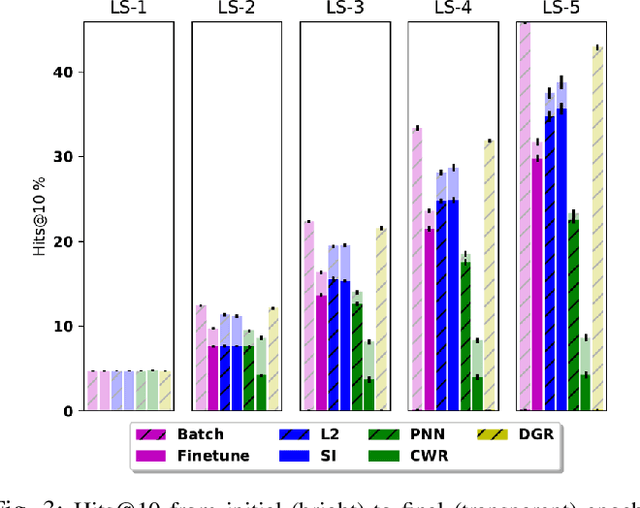
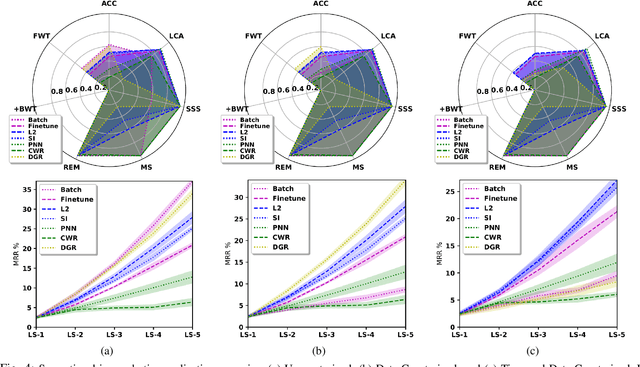
In recent years, there has been a resurgence in methods that use distributed (neural) representations to represent and reason about semantic knowledge for robotics applications. However, while robots often observe previously unknown concepts, these representations typically assume that all concepts are known a priori, and incorporating new information requires all concepts to be learned afresh. Our work relaxes the static assumptions of these representations to tackle the incremental knowledge graph embedding problem by leveraging principles of a range of continual learning methods. Through an experimental evaluation with several knowledge graphs and embedding representations, we provide insights about trade-offs for practitioners to match a semantics-driven robotics application to a suitable continual knowledge graph embedding method.