 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthicMind: A Risk-Aware Framework for Ethical-Emotional Alignment in Multi-Turn Dialogue
Apr 10, 2026Intelligent dialogue systems are increasingly deployed in emotionally and ethically sensitive settings, where failures in either emotional attunement or ethical judgment can cause significant harm. Existing dialogue models typically address empathy and ethical safety in isolation, and often fail to adapt their behavior as ethical risk and user emotion evolve across multi-turn interactions. We formulate ethical-emotional alignment in dialogue as an explicit turn-level decision problem, and propose \textsc{EthicMind}, a risk-aware framework that implements this formulation in multi-turn dialogue at inference time. At each turn, \textsc{EthicMind} jointly analyzes ethical risk signals and user emotion, plans a high-level response strategy, and generates context-sensitive replies that balance ethical guidance with emotional engagement, without requiring additional model training. To evaluate alignment behavior under ethically complex interactions, we introduce a risk-stratified, multi-turn evaluation protocol with a context-aware user simulation procedure. Experimental results show that \textsc{EthicMind} achieves more consistent ethical guidance and emotional engagement than competitive baselines, particularly in high-risk and morally ambiguous scenarios.
Breakdowns in Conversational AI: Interactional Failures in Emotionally and Ethically Sensitive Contexts
Apr 03, 2026Conversational AI is increasingly deployed in emotionally charged and ethically sensitive interactions. Previous research has primarily concentrated on emotional benchmarks or static safety checks, overlooking how alignment unfolds in evolving conversation. We explore the research question: what breakdowns arise when conversational agents confront emotionally and ethically sensitive behaviors, and how do these affect dialogue quality? To stress-test chatbot performance, we develop a persona-conditioned user simulator capable of engaging in multi-turn dialogue with psychological personas and staged emotional pacing. Our analysis reveals that mainstream models exhibit recurrent breakdowns that intensify as emotional trajectories escalate. We identify several common failure patterns, including affective misalignments, ethical guidance failures, and cross-dimensional trade-offs where empathy supersedes or undermines responsibility. We organize these patterns into a taxonomy and discuss the design implications, highlighting the necessity to maintain ethical coherence and affective sensitivity throughout dynamic interactions. The study offers the HCI community a new perspective on the diagnosis and improvement of conversational AI in value-sensitive and emotionally charged contexts.
Retrieval-augmented in-context learning for multimodal large language models in disease classification
May 04, 2025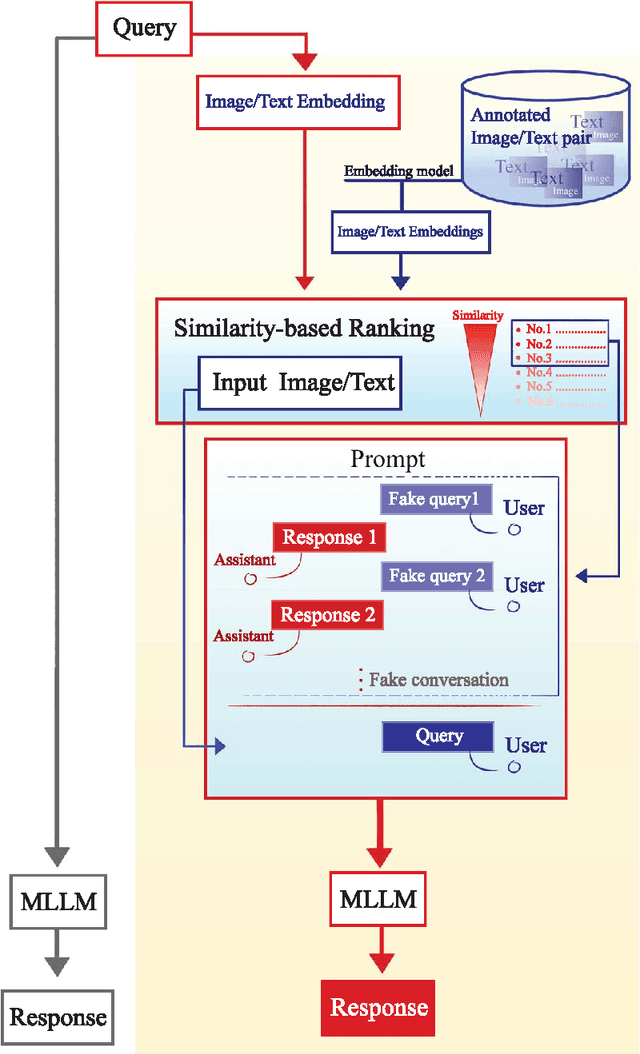
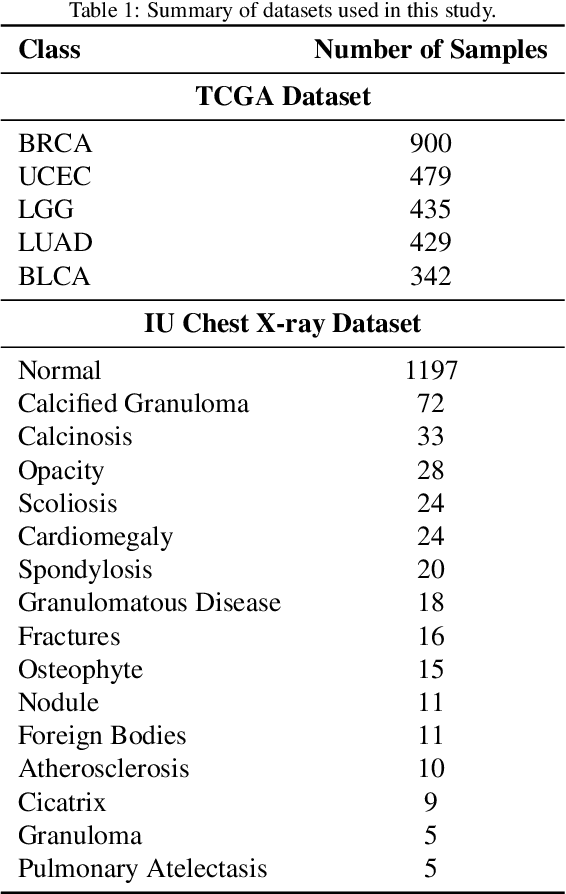
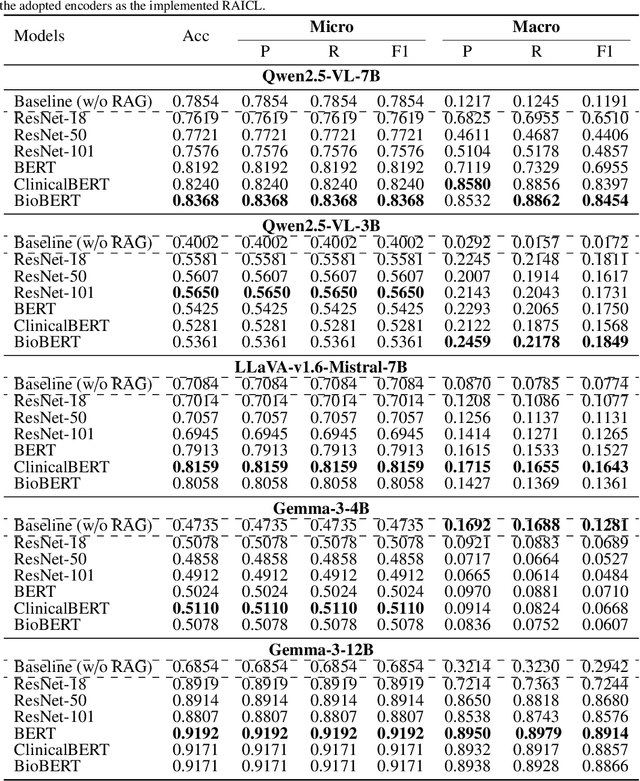
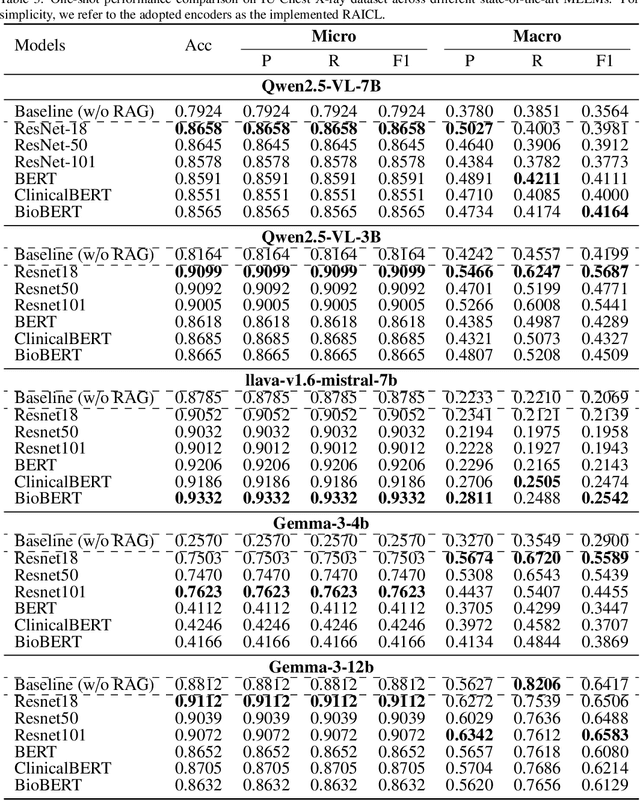
Objectives: We aim to dynamically retrieve informative demonstrations, enhancing in-context learning in multimodal large language models (MLLMs) for disease classification. Methods: We propose a Retrieval-Augmented In-Context Learning (RAICL) framework, which integrates retrieval-augmented generation (RAG) and in-context learning (ICL) to adaptively select demonstrations with similar disease patterns, enabling more effective ICL in MLLMs. Specifically, RAICL examines embeddings from diverse encoders, including ResNet, BERT, BioBERT, and ClinicalBERT, to retrieve appropriate demonstrations, and constructs conversational prompts optimized for ICL. We evaluated the framework on two real-world multi-modal datasets (TCGA and IU Chest X-ray), assessing its performance across multiple MLLMs (Qwen, Llava, Gemma), embedding strategies, similarity metrics, and varying numbers of demonstrations. Results: RAICL consistently improved classification performance. Accuracy increased from 0.7854 to 0.8368 on TCGA and from 0.7924 to 0.8658 on IU Chest X-ray. Multi-modal inputs outperformed single-modal ones, with text-only inputs being stronger than images alone. The richness of information embedded in each modality will determine which embedding model can be used to get better results. Few-shot experiments showed that increasing the number of retrieved examples further enhanced performance. Across different similarity metrics, Euclidean distance achieved the highest accuracy while cosine similarity yielded better macro-F1 scores. RAICL demonstrated consistent improvements across various MLLMs, confirming its robustness and versatility. Conclusions: RAICL provides an efficient and scalable approach to enhance in-context learning in MLLMs for multimodal disease classification.
MMRAG: Multi-Mode Retrieval-Augmented Generation with Large Language Models for Biomedical In-Context Learning
Feb 21, 2025



Objective: To optimize in-context learning in biomedical natural language processing by improving example selection. Methods: We introduce a novel multi-mode retrieval-augmented generation (MMRAG) framework, which integrates four retrieval strategies: (1) Random Mode, selecting examples arbitrarily; (2) Top Mode, retrieving the most relevant examples based on similarity; (3) Diversity Mode, ensuring variation in selected examples; and (4) Class Mode, selecting category-representative examples. This study evaluates MMRAG on three core biomedical NLP tasks: Named Entity Recognition (NER), Relation Extraction (RE), and Text Classification (TC). The datasets used include BC2GM for gene and protein mention recognition (NER), DDI for drug-drug interaction extraction (RE), GIT for general biomedical information extraction (RE), and HealthAdvice for health-related text classification (TC). The framework is tested with two large language models (Llama2-7B, Llama3-8B) and three retrievers (Contriever, MedCPT, BGE-Large) to assess performance across different retrieval strategies. Results: The results from the Random mode indicate that providing more examples in the prompt improves the model's generation performance. Meanwhile, Top mode and Diversity mode significantly outperform Random mode on the RE (DDI) task, achieving an F1 score of 0.9669, a 26.4% improvement. Among the three retrievers tested, Contriever outperformed the other two in a greater number of experiments. Additionally, Llama 2 and Llama 3 demonstrated varying capabilities across different tasks, with Llama 3 showing a clear advantage in handling NER tasks. Conclusion: MMRAG effectively enhances biomedical in-context learning by refining example selection, mitigating data scarcity issues, and demonstrating superior adaptability for NLP-driven healthcare applications.
Bridging the User-side Knowledge Gap in Knowledge-aware Recommendations with Large Language Models
Dec 18, 2024



In recent years, knowledge graphs have been integrated into recommender systems as item-side auxiliary information, enhancing recommendation accuracy. However, constructing and integrating structural user-side knowledge remains a significant challenge due to the improper granularity and inherent scarcity of user-side features. Recent advancements in Large Language Models (LLMs) offer the potential to bridge this gap by leveraging their human behavior understanding and extensive real-world knowledge. Nevertheless, integrating LLM-generated information into recommender systems presents challenges, including the risk of noisy information and the need for additional knowledge transfer. In this paper, we propose an LLM-based user-side knowledge inference method alongside a carefully designed recommendation framework to address these challenges. Our approach employs LLMs to infer user interests based on historical behaviors, integrating this user-side information with item-side and collaborative data to construct a hybrid structure: the Collaborative Interest Knowledge Graph (CIKG). Furthermore, we propose a CIKG-based recommendation framework that includes a user interest reconstruction module and a cross-domain contrastive learning module to mitigate potential noise and facilitate knowledge transfer. We conduct extensive experiments on three real-world datasets to validate the effectiveness of our method. Our approach achieves state-of-the-art performance compared to competitive baselines, particularly for users with sparse interactions.
SSP: A Simple and Safe automatic Prompt engineering method towards realistic image synthesis on LVM
Jan 02, 2024Recently, text-to-image (T2I) synthesis has undergone significant advancements, particularly with the emergence of Large Language Models (LLM) and their enhancement in Large Vision Models (LVM), greatly enhancing the instruction-following capabilities of traditional T2I models. Nevertheless, previous methods focus on improving generation quality but introduce unsafe factors into prompts. We explore that appending specific camera descriptions to prompts can enhance safety performance. Consequently, we propose a simple and safe prompt engineering method (SSP) to improve image generation quality by providing optimal camera descriptions. Specifically, we create a dataset from multi-datasets as original prompts. To select the optimal camera, we design an optimal camera matching approach and implement a classifier for original prompts capable of automatically matching. Appending camera descriptions to original prompts generates optimized prompts for further LVM image generation. Experiments demonstrate that SSP improves semantic consistency by an average of 16% compared to others and safety metrics by 48.9%.
COKE: A Cognitive Knowledge Graph for Machine Theory of Mind
May 09, 2023Theory of mind (ToM) refers to humans' ability to understand and infer the desires, beliefs, and intentions of others. The acquisition of ToM plays a key role in humans' social cognition and interpersonal relations. Though indispensable for social intelligence, ToM is still lacking for modern AI and NLP systems since they cannot access the human mental state and cognitive process beneath the training corpus. To empower AI systems with the ToM ability and narrow the gap between them and humans, in this paper, we propose COKE: the first cognitive knowledge graph for machine theory of mind. Specifically, COKE formalizes ToM as a collection of 45k+ manually verified cognitive chains that characterize human mental activities and subsequent behavioral/affective responses when facing specific social circumstances. Beyond that, we further generalize COKE using pre-trained language models and build a powerful cognitive generation model COKE+. Experimental results in both automatic and human evaluation demonstrate the high quality of COKE and the superior ToM ability of COKE+.
Automated Paper Screening for Clinical Reviews Using Large Language Models
May 01, 2023Objective: To assess the performance of the OpenAI GPT API in accurately and efficiently identifying relevant titles and abstracts from real-world clinical review datasets and compare its performance against ground truth labelling by two independent human reviewers. Methods: We introduce a novel workflow using the OpenAI GPT API for screening titles and abstracts in clinical reviews. A Python script was created to make calls to the GPT API with the screening criteria in natural language and a corpus of title and abstract datasets that have been filtered by a minimum of two human reviewers. We compared the performance of our model against human-reviewed papers across six review papers, screening over 24,000 titles and abstracts. Results: Our results show an accuracy of 0.91, a sensitivity of excluded papers of 0.91, and a sensitivity of included papers of 0.76. On a randomly selected subset of papers, the GPT API demonstrated the ability to provide reasoning for its decisions and corrected its initial decision upon being asked to explain its reasoning for a subset of incorrect classifications. Conclusion: The GPT API has the potential to streamline the clinical review process, save valuable time and effort for researchers, and contribute to the overall quality of clinical reviews. By prioritizing the workflow and acting as an aid rather than a replacement for researchers and reviewers, the GPT API can enhance efficiency and lead to more accurate and reliable conclusions in medical research.
Safety Assessment of Chinese Large Language Models
Apr 20, 2023With the rapid popularity of large language models such as ChatGPT and GPT-4, a growing amount of attention is paid to their safety concerns. These models may generate insulting and discriminatory content, reflect incorrect social values, and may be used for malicious purposes such as fraud and dissemination of misleading information. Evaluating and enhancing their safety is particularly essential for the wide application of large language models (LLMs). To further promote the safe deployment of LLMs, we develop a Chinese LLM safety assessment benchmark. Our benchmark explores the comprehensive safety performance of LLMs from two perspectives: 8 kinds of typical safety scenarios and 6 types of more challenging instruction attacks. Our benchmark is based on a straightforward process in which it provides the test prompts and evaluates the safety of the generated responses from the evaluated model. In evaluation, we utilize the LLM's strong evaluation ability and develop it as a safety evaluator by prompting. On top of this benchmark, we conduct safety assessments and analyze 15 LLMs including the OpenAI GPT series and other well-known Chinese LLMs, where we observe some interesting findings. For example, we find that instruction attacks are more likely to expose safety issues of all LLMs. Moreover, to promote the development and deployment of safe, responsible, and ethical AI, we publicly release SafetyPrompts including 100k augmented prompts and responses by LLMs.
Recent Advances towards Safe, Responsible, and Moral Dialogue Systems: A Survey
Feb 18, 2023With the development of artificial intelligence, dialogue systems have been endowed with amazing chit-chat capabilities, and there is widespread interest and discussion about whether the generated contents are socially beneficial. In this paper, we present a new perspective of research scope towards building a safe, responsible, and modal dialogue system, including 1) abusive and toxic contents, 2) unfairness and discrimination, 3) ethics and morality issues, and 4) risk of misleading and privacy information. Besides, we review the mainstream methods for evaluating the safety of large models from the perspectives of exposure and detection of safety issues. The recent advances in methodologies for the safety improvement of both end-to-end dialogue systems and pipeline-based models are further introduced. Finally, we discussed six existing challenges towards responsible AI: explainable safety monitoring, continuous learning of safety issues, robustness against malicious attacks, multimodal information processing, unified research framework, and multidisciplinary theory integration. We hope this survey will inspire further research toward safer dialogue systems.