 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Generation of Personalities with Large Language Models
Apr 10, 2024
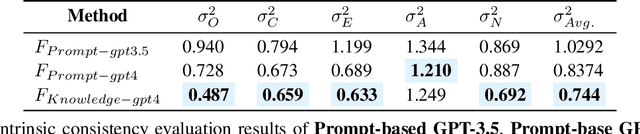
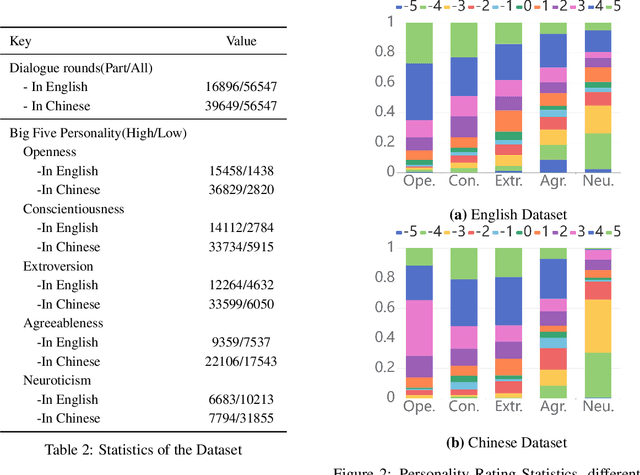

In the realm of mimicking human deliberation, large language models (LLMs) show promising performance, thereby amplifying the importance of this research area. Deliberation is influenced by both logic and personality. However, previous studies predominantly focused on the logic of LLMs, neglecting the exploration of personality aspects. In this work, we introduce Dynamic Personality Generation (DPG), a dynamic personality generation method based on Hypernetworks. Initially, we embed the Big Five personality theory into GPT-4 to form a personality assessment machine, enabling it to evaluate characters' personality traits from dialogues automatically. We propose a new metric to assess personality generation capability based on this evaluation method. Then, we use this personality assessment machine to evaluate dialogues in script data, resulting in a personality-dialogue dataset. Finally, we fine-tune DPG on the personality-dialogue dataset. Experiments prove that DPG's personality generation capability is stronger after fine-tuning on this dataset than traditional fine-tuning methods, surpassing prompt-based GPT-4.
SSP: A Simple and Safe automatic Prompt engineering method towards realistic image synthesis on LVM
Jan 02, 2024Recently, text-to-image (T2I) synthesis has undergone significant advancements, particularly with the emergence of Large Language Models (LLM) and their enhancement in Large Vision Models (LVM), greatly enhancing the instruction-following capabilities of traditional T2I models. Nevertheless, previous methods focus on improving generation quality but introduce unsafe factors into prompts. We explore that appending specific camera descriptions to prompts can enhance safety performance. Consequently, we propose a simple and safe prompt engineering method (SSP) to improve image generation quality by providing optimal camera descriptions. Specifically, we create a dataset from multi-datasets as original prompts. To select the optimal camera, we design an optimal camera matching approach and implement a classifier for original prompts capable of automatically matching. Appending camera descriptions to original prompts generates optimized prompts for further LVM image generation. Experiments demonstrate that SSP improves semantic consistency by an average of 16% compared to others and safety metrics by 48.9%.
F3-Pruning: A Training-Free and Generalized Pruning Strategy towards Faster and Finer Text-to-Video Synthesis
Dec 06, 2023Recently Text-to-Video (T2V) synthesis has undergone a breakthrough by training transformers or diffusion models on large-scale datasets. Nevertheless, inferring such large models incurs huge costs.Previous inference acceleration works either require costly retraining or are model-specific.To address this issue, instead of retraining we explore the inference process of two mainstream T2V models using transformers and diffusion models.The exploration reveals the redundancy in temporal attention modules of both models, which are commonly utilized to establish temporal relations among frames.Consequently, we propose a training-free and generalized pruning strategy called F3-Pruning to prune redundant temporal attention weights.Specifically, when aggregate temporal attention values are ranked below a certain ratio, corresponding weights will be pruned.Extensive experiments on three datasets using a classic transformer-based model CogVideo and a typical diffusion-based model Tune-A-Video verify the effectiveness of F3-Pruning in inference acceleration, quality assurance and broad applicability.