 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGT23D-Bench: A Comprehensive General Text-to-3D Generation Benchmark
Dec 13, 2024Recent advances in General Text-to-3D (GT23D) have been significant. However, the lack of a benchmark has hindered systematic evaluation and progress due to issues in datasets and metrics: 1) The largest 3D dataset Objaverse suffers from omitted annotations, disorganization, and low-quality. 2) Existing metrics only evaluate textual-image alignment without considering the 3D-level quality. To this end, we are the first to present a comprehensive benchmark for GT23D called GT23D-Bench consisting of: 1) a 400k high-fidelity and well-organized 3D dataset that curated issues in Objaverse through a systematical annotation-organize-filter pipeline; and 2) comprehensive 3D-aware evaluation metrics which encompass 10 clearly defined metrics thoroughly accounting for multi-dimension of GT23D. Notably, GT23D-Bench features three properties: 1) Multimodal Annotations. Our dataset annotates each 3D object with 64-view depth maps, normal maps, rendered images, and coarse-to-fine captions. 2) Holistic Evaluation Dimensions. Our metrics are dissected into a) Textual-3D Alignment measures textual alignment with multi-granularity visual 3D representations; and b) 3D Visual Quality which considers texture fidelity, multi-view consistency, and geometry correctness. 3) Valuable Insights. We delve into the performance of current GT23D baselines across different evaluation dimensions and provide insightful analysis. Extensive experiments demonstrate that our annotations and metrics are aligned with human preferences.
SeMv-3D: Towards Semantic and Mutil-view Consistency simultaneously for General Text-to-3D Generation with Triplane Priors
Oct 10, 2024Recent advancements in generic 3D content generation from text prompts have been remarkable by fine-tuning text-to-image diffusion (T2I) models or employing these T2I models as priors to learn a general text-to-3D model. While fine-tuning-based methods ensure great alignment between text and generated views, i.e., semantic consistency, their ability to achieve multi-view consistency is hampered by the absence of 3D constraints, even in limited view. In contrast, prior-based methods focus on regressing 3D shapes with any view that maintains uniformity and coherence across views, i.e., multi-view consistency, but such approaches inevitably compromise visual-textual alignment, leading to a loss of semantic details in the generated objects. To achieve semantic and multi-view consistency simultaneously, we propose SeMv-3D, a novel framework for general text-to-3d generation. Specifically, we propose a Triplane Prior Learner (TPL) that learns triplane priors with 3D spatial features to maintain consistency among different views at the 3D level, e.g., geometry and texture. Moreover, we design a Semantic-aligned View Synthesizer (SVS) that preserves the alignment between 3D spatial features and textual semantics in latent space. In SVS, we devise a simple yet effective batch sampling and rendering strategy that can generate arbitrary views in a single feed-forward inference. Extensive experiments present our SeMv-3D's superiority over state-of-the-art performances with semantic and multi-view consistency in any view. Our code and more visual results are available at https://anonymous.4open.science/r/SeMv-3D-6425.
Training-Free Semantic Video Composition via Pre-trained Diffusion Model
Jan 17, 2024



The video composition task aims to integrate specified foregrounds and backgrounds from different videos into a harmonious composite. Current approaches, predominantly trained on videos with adjusted foreground color and lighting, struggle to address deep semantic disparities beyond superficial adjustments, such as domain gaps. Therefore, we propose a training-free pipeline employing a pre-trained diffusion model imbued with semantic prior knowledge, which can process composite videos with broader semantic disparities. Specifically, we process the video frames in a cascading manner and handle each frame in two processes with the diffusion model. In the inversion process, we propose Balanced Partial Inversion to obtain generation initial points that balance reversibility and modifiability. Then, in the generation process, we further propose Inter-Frame Augmented attention to augment foreground continuity across frames. Experimental results reveal that our pipeline successfully ensures the visual harmony and inter-frame coherence of the outputs, demonstrating efficacy in managing broader semantic disparities.
Make-A-Storyboard: A General Framework for Storyboard with Disentangled and Merged Control
Dec 06, 2023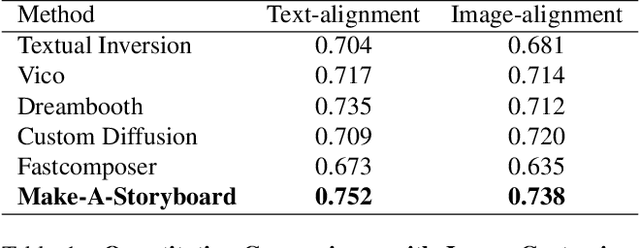
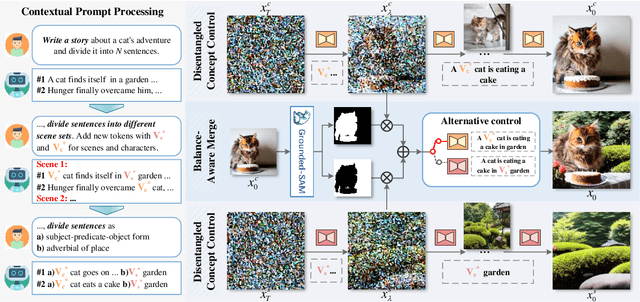


Story Visualization aims to generate images aligned with story prompts, reflecting the coherence of storybooks through visual consistency among characters and scenes.Whereas current approaches exclusively concentrate on characters and neglect the visual consistency among contextually correlated scenes, resulting in independent character images without inter-image coherence.To tackle this issue, we propose a new presentation form for Story Visualization called Storyboard, inspired by film-making, as illustrated in Fig.1.Specifically, a Storyboard unfolds a story into visual representations scene by scene. Within each scene in Storyboard, characters engage in activities at the same location, necessitating both visually consistent scenes and characters.For Storyboard, we design a general framework coined as Make-A-Storyboard that applies disentangled control over the consistency of contextual correlated characters and scenes and then merge them to form harmonized images.Extensive experiments demonstrate 1) Effectiveness.the effectiveness of the method in story alignment, character consistency, and scene correlation; 2) Generalization. Our method could be seamlessly integrated into mainstream Image Customization methods, empowering them with the capability of story visualization.
F3-Pruning: A Training-Free and Generalized Pruning Strategy towards Faster and Finer Text-to-Video Synthesis
Dec 06, 2023Recently Text-to-Video (T2V) synthesis has undergone a breakthrough by training transformers or diffusion models on large-scale datasets. Nevertheless, inferring such large models incurs huge costs.Previous inference acceleration works either require costly retraining or are model-specific.To address this issue, instead of retraining we explore the inference process of two mainstream T2V models using transformers and diffusion models.The exploration reveals the redundancy in temporal attention modules of both models, which are commonly utilized to establish temporal relations among frames.Consequently, we propose a training-free and generalized pruning strategy called F3-Pruning to prune redundant temporal attention weights.Specifically, when aggregate temporal attention values are ranked below a certain ratio, corresponding weights will be pruned.Extensive experiments on three datasets using a classic transformer-based model CogVideo and a typical diffusion-based model Tune-A-Video verify the effectiveness of F3-Pruning in inference acceleration, quality assurance and broad applicability.
MotionZero:Exploiting Motion Priors for Zero-shot Text-to-Video Generation
Nov 28, 2023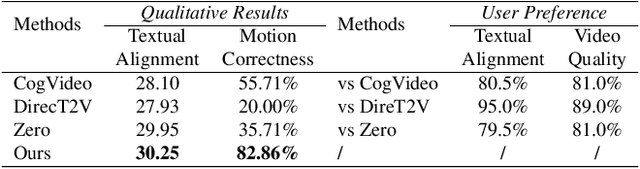
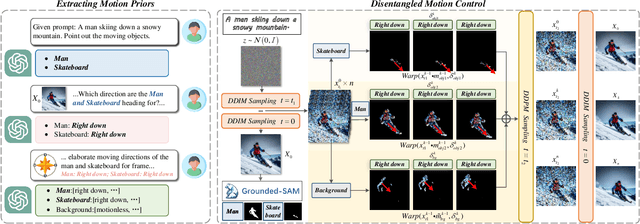
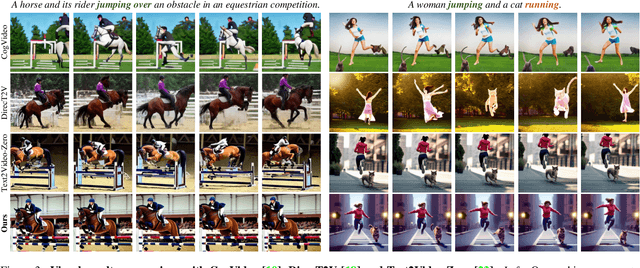

Zero-shot Text-to-Video synthesis generates videos based on prompts without any videos. Without motion information from videos, motion priors implied in prompts are vital guidance. For example, the prompt "airplane landing on the runway" indicates motion priors that the "airplane" moves downwards while the "runway" stays static. Whereas the motion priors are not fully exploited in previous approaches, thus leading to two nontrivial issues: 1) the motion variation pattern remains unaltered and prompt-agnostic for disregarding motion priors; 2) the motion control of different objects is inaccurate and entangled without considering the independent motion priors of different objects. To tackle the two issues, we propose a prompt-adaptive and disentangled motion control strategy coined as MotionZero, which derives motion priors from prompts of different objects by Large-Language-Models and accordingly applies motion control of different objects to corresponding regions in disentanglement. Furthermore, to facilitate videos with varying degrees of motion amplitude, we propose a Motion-Aware Attention scheme which adjusts attention among frames by motion amplitude. Extensive experiments demonstrate that our strategy could correctly control motion of different objects and support versatile applications including zero-shot video edit.